
大数据文摘作品
编译:Apricock、万如苑、小鱼
机器学习方向的面试可以说是非常恐怖了。你觉得自己什么都知道,但面试的时候却很容易陷入窘境。其实很多问题可以事先准备,本文搜集了一些机器学习方向面试时常见的题目,希望能在求职路上助你一臂之力。
过去的几个月中,我参加了一些公司数据科学、机器学习等方向初级岗位的面试。
我面试的这些岗位和数据科学、常规机器学习还有专业的自然语言处理、计算机视觉相关。我参加了亚马逊、三星、优步、华为等大公司的面试,除此之外还有一些初创公司的面试。这些初创公司有些处于启动阶段,也有些已经成型并得到投资。
简单介绍一下我的背景:在校期间攻读机器学习和计算机视觉的硕士学位,主要进行学术方面的研究,但是有在一家早期初创公司(和ML无关)实习八个月的经历。
今天我想跟你们分享我在面试中被问到的问题,以及如去何解答。其中一部分问题很常见,旨在考察你的理论知识储备。但也有一些问题颇具创意,非常有意思。我将把常见的问题简单列出来,不多做解释,因为网上有许多资料可以参考。比较罕见、棘手的问题,我会深入探讨一下。希望你读完这篇文章后,可以在机器学习的面试中表现出色,获得自己满意的工作。
首先来看一些常见的理论问题:
什么是偏差-方差之间的权衡?

什么是梯度下降?

请解释过拟合和欠拟合。如何应对这两种情况?
如何解决维数灾难问题?

什么是正则化?为什么要正则化?请给出一些正则化常用方法。

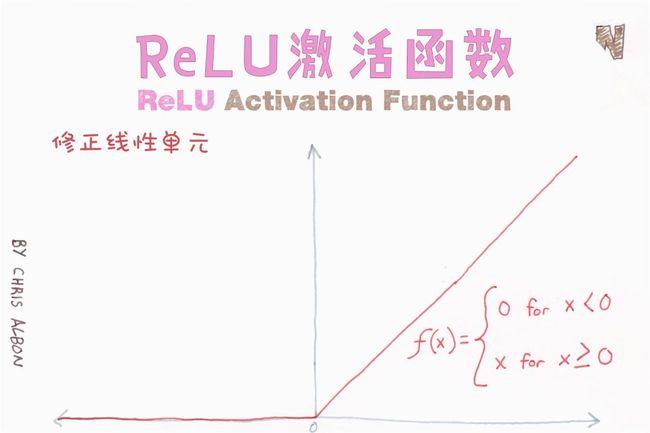
为什么在神经网络中,ReLU是比Sigmoid更好、更常用的激活函数?
数据规范化是什么?为什么需要对数据进行规范化?
我觉得这个问题很重要,值得强调。数据规范化在预处理阶段尤为重要,它可以将数值缩放到特定的范围,以在反向传播时获得更好的收敛性。一般而言,规范化就是让每一个数据点减去它们的均值,并除以标准差。
如果不这样处理,一些(数量级较大的)特征值在代价函数中的权重就会更大(如果大数量级特征值改变1%,代价函数的变化就会很大,但小数量级的特征值改变1%产生的影响则微乎其微)。规范化使得所有特征值具有相同的权重。
请解释降维,以及使用场合和它的优势。
降维是一种通过分析出主变量来减少特征变量的过程,其中主变量通常就是重要的特征。一个特征变量的重要性取决于它对数据信息的解释程度,以及你所采用的方法。至于如何选取方法,主要靠不断摸索,以及你自己的偏好。通常大家会从线性方法开始,如果结果欠缺拟合性,则考虑尝试非线性的方法。
数据降维的优势有以下几点:(1)节省存储空间;(2)节省计算时间(比如应用于机器学习算法时);(3)去除冗余特征变量,正如同时以平方米和平方英里存储地区面积没有任何意义(甚至可能是收集数据时出现错误);(4)将数据降维到二维或三维后,我们或许可以画图,将数据可视化,以观察数据具有的模式,获得对数据的直观感受;(5)特征变量过多或模型过于复杂可能导致模型过拟合。
如何处理数据集中缺失或损坏的数据?
你可以在数据集中找到缺失/损坏的数据,并删除它所在的行或列,或是用其他值代替之。Pandas中有两个非常有效的函数:isnull()和dropna(),这两个函数可以帮你找到有缺失/损坏数据的行,并删除对应值。如果要用占位符(比如0)填充这些无效值,你可以使用fillna()函数。
请解释一下某种聚类算法。
我写了一篇热门文章《数据科学家应当知晓的5种聚类算法》,详尽细致讨论了这些算法,文章的可视化也很棒。
文章链接:
https://towardsdatascience.com/the-5-clustering-algorithms-data-scientists-need-to-know-a36d136ef68
如何开展探索性数据分析(EDA)?
EDA的目的是在应用预测模型之前,了解数据的信息,获得对数据的直观感受。总的来说,开展探索性数据分析一般采取由粗到精的方法。我们首先获取一些高层次、全局性的直观感受。检查一下不平衡的类,查看每一类的均值和方差。看看第一行,了解数据大致内容。
运行pandas中的df.info()函数,看看哪些是连续变量、分类变量,并查看变量的数据类型(整型、浮点型、字符串)。然后删掉一些在分析、预测中不需要的列,这些列中的很多行数值都相同(提供的信息也相同),或者存在很多缺失值。我们也可以用某一行/列的众数或中值填充该行/列中的缺失值。
此外可以做一些基本的可视化操作。从相对高层次、全局性的角度开始,比如绘制分类特征关于类别的条形图,绘制最终类别的条形图,探究一下最“常用”的特征,对独立变量进行可视化以获得一些认知和灵感等。
接下来可以展开更具体的探索。比如同时对两三个特征进行可视化,看看它们相互有何联系。也可以做主成分分析,来确定哪些特征中包含的信息最多。类似地,还可以将一些特征分组,以观察组间联系。
比如可以考察一下,取A = B = 0时,不同的类会有什么表现?取A = 1、B = 0时呢?还要比较一下不同特征的影响,比方说特征A可以取“男性”或“女性”,则可以画出特征A与旅客舱位的关系图,判断男性和女性选在舱位选择上是否有差异。
除了条形图、散点图或是其他基本图表,也可以画出PDF(概率分布函数)或CDF(累计分布函数)、使用重叠绘图方法等。还可以考察一下统计特性,比如分布、p值等。最后就该建立机器学习模型了。
从简单的模型开始,比如朴素贝叶斯、线性回归等。如果上述模型效果不理想,或是数据高度非线性,则考虑使用多项式回归、决策树或支持向量机。EDA可以挑选出重要的特征。如果数据量很大,可以使用神经网络。别忘了检查ROC曲线(感受性曲线)、准确率和召回率。
怎么知道应当选取何种机器学习模型?
虽然人们应当坚信天下没有免费的午餐,但还是有一些指导原则相当通用。我在一篇文章里写了如何选取合适的回归模型,还有一篇备忘录也很棒!
文章链接:
https://towardsdatascience.com/selecting-the-best-machine-learning-algorithm-for-your-regression-problem-20c330bad4ef
备忘录链接:
https://www.google.com/search?tbs=simg:CAESqQIJvnrCwg_15JjManQILEKjU2AQaBAgUCAoMCxCwjKcIGmIKYAgDEijqAvQH8wfpB_1AH_1hL1B_1YH6QKOE6soyT-TJ9A0qCipKKoo0TS0NL0-GjA_15sJ-3A24wpvrDVRc8bM3x0nrW3Ctn6tFeYFLpV7ldtVRVDHO-s-8FnDFrpLKzC8gBAwLEI6u_1ggaCgoICAESBO
为什么对图像使用卷积而不只是FC层?
这个问题比较有趣,因为提出这个问题的公司并不多。恰巧,在一家专攻计算机视觉的公司的面试中,我被问到这个问题。答案应分成两部分:首先,卷积可以保存、编码、使用图像的空间信息。只用FC层的话可能就没有相关空间信息了。其次,卷积神经网络(CNN)某种程度上本身具有平移不变性,因为每个卷积核都充当了它自己的滤波器/特征监测器。
为什么CNN具有平移不变性?
上文解释过,每个卷积核都充当了它自己的滤波器/特征监测器。假设你正在进行目标检测,这个目标处于图片的何处并不重要,因为我们要以滑动窗口的方式,将卷积应用于整个图像。
为什么用CNN分类需要进行最大池化?
这也是属于计算机视觉领域的一个问题。CNN中的最大池化可以减少计算量,因为特征图在池化后将会变小。与此同时,因为采取了最大池化,并不会丧失太多图像的语义信息。还有一个理论认为,最大池化有利于使CNN具有更好的平移不变性。关于这个问题,可以看一下吴恩达讲解最大池化优点的视频。
视频链接:
https://www.coursera.org/learn/convolutional-neural-networks/lecture/hELHk/pooling-layers
为什么用CNN分割时通常需要编码-解码结构?
CNN编码器可以看作是特征提取网络,解码器则利用它提供的信息,“解码”特征并放大到原始大小,以此预测图像片段。
残差网络有什么意义?
残差网络主要能够让它之前的层直接访问特征,这使得信息在网络中更易于传播。一篇很有趣的论文解释了本地的跳跃式传导如何赋予网络多路径结构,使得特征能够以不同路径在整个网络中传播。
论文链接:
https://arxiv.org/abs/1605.06431
批量标准化是什么?它为什么有效?
训练深层神经网络很复杂,因为在训练过程中,随着前几层输入的参数不断变化,每层输入的分布也随之变化。一种方法是将每层输入规范化,输出函数均值为0,标准差为1。对每一层的每个小批量输入都采用上述方式进行规范化(计算每个小批量输入的均值和方差,然后标准化)。这和神经网络的输入的规范化类似。
批量标准化有什么好处?我们知道,对输入进行规范化有助于神经网络学习。但神经网络不过是一系列的层,每层的输出又成为下一层的输入。也就是说,我们可以将其中每一层视作子网络的第一层。把神经网络想象成一系列互相传递信息的网络结构,因此在激活函数作用于输出之前,先将每一层输出规范化,再将其传递到下一层(子网络)。
如何处理不平衡数据集?
关于这个问题我写了一篇文章,请查看文章中第三个小标题。
文章链接:
https://towardsdatascience.com/7-practical-deep-learning-tips-97a9f514100e
为什么要使用许多小卷积核(如3*3的卷积核),而非少量大卷积核?
这篇VGGNet的论文中有很详细的解释。有两个原因:首先,同少数大卷积核一样,更多小卷积核也可以得到相同的感受野和空间背景,而且用小卷积核需要的参数更少、计算量更小。其次,使用小卷积核需要更多过滤器,这意味会使用更多的激活函数,因此你的CNN可以得到更具特异性的映射函数。
论文链接:
https://arxiv.org/pdf/1409.1556.pdf
你有和我们公司相关的项目经历吗?
在回答这个问题时,你需要把自己的研究和他们的业务的联系起来。想想看你是否做过什么研究,或学过什么技能,能和公司业务及你申请的岗位有所联系。这种经历不需要百分之百符合所申请的岗位,只要在某种程度上有关联,这些经历就会成为你很大的加分项。
请介绍一下你目前的硕士研究项目。哪些项目和申请岗位有关联?未来发展方向是什么?
这个问题的答案同上,你懂的

结论
以上就是所有我在应聘数据科学和机器学习相关岗位时被问到的问题。希望你喜欢这篇文章,并从中获益。
相关报道:
https://towardsdatascience.com/data-science-and-machine-learning-interview-questions-3f6207cf040b