开始正式搭建Hadoop环境,之所以分开写,也是便于阅读及以后参考。
Hadoop环境的搭建过程中,需要配置几个XML文件,接下来简单介绍下这几个XML文件的作用
core-site.xml
主要配置NameNode的一些信息,主要属性如下:
fs.defaultFS
hdfs://ns
hadoop.tmp.dir
/usr/local/hadoop/hdpdata/
需要手动创建hdpdata目录
ha.zookeeper.quorum
node01:2181,node02:2181,node03:2181
zookeeper地址,多个用逗号隔开
hdfs-site.xml
主要配置hdfs
dfs.nameservices
ns
指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致
dfs.ha.namenodes.ns
nn1,nn2
ns命名空间下有两个NameNode,逻辑代号,随便起名字,分别是nn1,nn2
dfs.namenode.rpc-address.ns.nn1
node01:9000
nn1的RPC通信地址
dfs.namenode.http-address.ns.nn1
node01:50070
nn1的http通信地址
dfs.namenode.rpc-address.ns.nn2
node02:9000
nn2的RPC通信地址
dfs.namenode.http-address.ns.nn2
node02:50070
nn2的http通信地址
dfs.namenode.shared.edits.dir
qjournal://node03:8485;node04:8485;node05:8485/ns
指定NameNode的edits元数据在JournalNode上的存放位置
dfs.journalnode.edits.dir
/usr/local/hadoop/journaldata
指定JournalNode在本地磁盘存放数据的位置
dfs.ha.automatic-failover.enabled
true
开启NameNode失败自动切换
dfs.client.failover.proxy.provider.ns
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
配置失败自动切换实现方式,使用内置的zkfc
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
配置隔离机制,多个机制用换行分割,先执行sshfence,执行失败后执行shell(/bin/true),/bin/true会直接返回0表示成功
dfs.ha.fencing.ssh.private-key-files
/home/hadoop/.ssh/id_rsa
使用sshfence隔离机制时需要ssh免登陆
dfs.ha.fencing.ssh.connect-timeout
30000
配置sshfence隔离机制超时时间
dfs.replication
3
设置block副本数为3
dfs.block.size
134217728
设置block大小是128M
yarn-site.xml
yarn的一些配置信息
由于我们是在虚拟机中配置,hadoop默认集群内存大小为8192MB,一般来说是不够的,需要加参数限制,见下方对内存的设置,当然土豪随意
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yarn-ha
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
node01
yarn.resourcemanager.webapp.address.rm1
${yarn.resourcemanager.hostname.rm1}:8088
HTTP访问的端口号
yarn.resourcemanager.hostname.rm2
node02
yarn.resourcemanager.webapp.address.rm2
${yarn.resourcemanager.hostname.rm2}:8088
yarn.resourcemanager.zk-address
node01:2181,node02:2181,node03:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.log-aggregation-enable
true
yarn.nodemanager.remote-app-log-dir
/data/hadoop/yarn-logs
yarn.log-aggregation.retain-seconds
259200
yarn.scheduler.minimum-allocation-mb
2048
单个任务可申请最少内存,默认1024MB
yarn.nodemanager.resource.memory-mb
2048
nodemanager默认内存大小,默认为8192MB(value单位为MB)
yarn.nodemanager.resource.cpu-vcores
1
nodemanager cpu内核数
环境搭建
| 主机名 | IP | 安装软件 | 运行的进程 |
|---|---|---|---|
| node01 | 192.168.47.10 | JDK、Hadoop、Zookeeper | NameNode(Active)、DFSZKFailoverController(zkfc)、ResourceManager(Standby)、QuorumPeerMain(Zookeeper) |
| node02 | 192.168.47.11 | JDK、Hadoop、Zookeeper | NameNode(Standby)、DFSZKFailoverController(zkfc)、ResourceManager(Active)、QuorumPeerMain(Zookeeper)、Jobhistory |
| node03 | 192.168.47.12 | JDK、Hadoop、Zookeeper | DataNode、NodeManager、QuorumPeerMain(Zookeeper)、JournalNode |
| node04 | 192.168.47.13 | JDK、Hadoop | DataNode、NodeManager、JournalNode |
| node05 | 192.168.47.14 | JDK、Hadoop | DataNode、NodeManager、JournalNode |
本次环境搭建规划如下:
| 主机名 | IP | 安装软件 | 运行的进程 |
|---|---|---|---|
| node01 | 192.168.47.10 | JDK、Hadoop、Zookeeper | NameNode(Active)、DFSZKFailoverController(zkfc)、ResourceManager(Standby)、QuorumPeerMain(Zookeeper) |
| node02 | 192.168.47.11 | JDK、Hadoop、Zookeeper | NameNode(Standby)、DFSZKFailoverController(zkfc)、ResourceManager(Active)、QuorumPeerMain(Zookeeper)、Jobhistory |
| node03 | 192.168.47.12 | JDK、Hadoop、Zookeeper | DataNode、NodeManager、QuorumPeerMain(Zookeeper)、JournalNode |
| node04 | 192.168.47.13 | JDK、Hadoop | DataNode、NodeManager、JournalNode |
| node05 | 192.168.47.14 | JDK、Hadoop | DataNode、NodeManager、JournalNode |
搭建过程中,无特殊说明,均为使用hadoop用户
- 上传hadoop安装包,本次采用hadoop2.7.4版本
- 解压
tar -xzvf hadoop-2.7.4.tar.gz目录放在hadoop用户家目录apps下 - 切换root用户,创建软链接
ln -s /home/hadoop/apps/hadoop-2.7.4 /usr/local/hadoop - 修改属主
chown -R hadoop:hadoop /usr/local/hadoop - 修改环境变量:
vim /etc/profile,添加如下变量,其中,PATH为追加变量
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_HOME=$HADOOP_HOME
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 编译环境变量
source /etc/profile - 切换回hadoop用户,进入hadoop配置文件路径
cd /usr/local/hadoop/etc/hadoop - 修改hadoop-env.sh中JAVA_HOME为jdk安装路径/快捷路径
- 配置core-site.xml为之前xml内容
- 配置hdfs-site.xml为之前内容
- 配置yarn-site.xml为之前内容
- 配置mapred-site.xml为如下内容(Hadoop安装文件中此文件给的为mapred-site.xml.template,需修改为mapred-site.xml)
mapreduce.framework.name
yarn
指定mr框架为yarn方式
mapreduce.jobhistory.address
node02:10020
历史服务器端口号
mapreduce.jobhistory.webapp.address
node02:19888
历史服务器的WEB UI端口号
mapreduce.jobhistory.joblist.cache.size
2000
内存中缓存的historyfile文件信息(主要是job对应的文件目录)
- 手动创建指定的临时目录:
mkdir /usr/local/hadoop/hdpdata - 修改slaves文件,设置datanode和nodemanager启动节点主机名称
在slaves文件中添加节点的主机名称
node03
node04
node05
配置hadoop用户免密码登录
需要配置集群之间的免密码登录
- 在所有节点产生秘钥及公钥
ssh-keygen -t rsa - 在每个节点上,将公钥copy到node01
ssh-copy-id -i node01 - 将node01节点上的authorized_keys copy到其他节点
scp authorized_keys hadoop@node02:/home/hadoop/.ssh - 每个节点分别尝试与其他节点的ssh登录,包括自己
ssh node01,如果需要输入密码,则是第一次登录,输入就好
在其他节点配置hadoop
- 将配置好的hadoop安装目录copy到其他节点(切换到hadoop安装目录)
scp -r hadoop-2.7.4 hadoop@node02:/home/hadoop/apps - 创建软链接,修改软链接属主
- 添加环境变量
至此,集群环境准备工作基本就绪,检查一下防火墙是否关闭(iptables -L),及SELinux的状态(getenforce),防止启动时出错
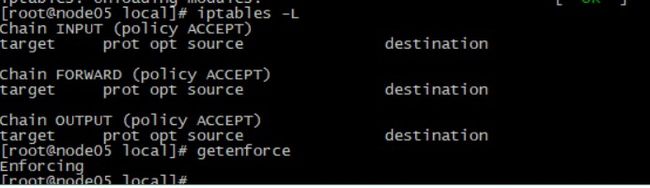 防火墙关闭但selinux不正常.jpg
防火墙关闭但selinux不正常.jpg
上图中,防火墙状态正常,但SELinux不对,设置SELinuxsetenforce 0,再看状态变为Permissive
启动集群
- 切换回hadoop用户
- 启动journalnode(分别在node03、node04、node05上启动)
/usr/local/hadoop/sbin/hadoop-daemon.sh start journalnode启动成功后,jps会看到多了如下进程JournalNode - 格式化HDFS 在node01上执行命令
hdfs namenode -format,格式化成功后会在core-site.xml中的hadoop.tmp.dir指定的路径下生成dfs文件夹,将该文件夹拷贝到node02的相同路径下
scp -r hdpdata hadoop@node02:/usr/local/hadoop - 在node01上执行格式化ZKFC的操作
hdfs zkfc -formatZK执行成功,日志输出如下信息
INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/ns in ZK
 格式化zkfc成功.jpg
格式化zkfc成功.jpg - 在node01上启动HDFS
sbin/start-dfs.sh
启动成功后,在node03、node04、node05会出现datanode进程,在node01、node02会出现NameNode进程及DFSZKFailoverController进程 - 在node02上启动YARN
sbin/start-yarn.sh - 在node01单独启动一个ResourceManger作为备份节点
sbin/yarn-daemon.sh start resourcemanager - 在node02上启动JobHistoryServer
sbin/mr-jobhistory-daemon.sh start historyserver - 至此,hadoop启动完成
HDFS HTTP访问地址
NameNode (active):http://192.168.47.10:50070
NameNode (standby):http://192.168.47.11:50070
ResourceManager HTTP访问地址
ResourceManager :http://192.168.47.11:8088
历史日志HTTP访问地址
JobHistoryServer:http://192.168.47.11:19888
集群验证
- 验证HDFS 是否正常工作及HA高可用
- 向hdfs上传一个文件
hadoop fs -put /usr/local/hadoop/README.txt / - 在active节点手动关闭active的namenode
sbin/hadoop-daemon.sh stop namenode - 通过HTTP 50070端口查看standby namenode的状态是否转换为active,再手动启动上一步关闭的namenode
sbin/hadoop-daemon.sh start namenode
- 验证YARN是否正常工作及ResourceManager HA高可用
- 运行测试hadoop提供的demo中的WordCount程序:
hadoop fs -mkdir /wordcount
hadoop fs -mkdir /wordcount/input
hadoop fs -mv /README.txt /wordcount/input
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount /wordcount/input /wordcount/output
注意:HDFS 上/wordcount/output 为输出路径不能存在,否则任务不能执行
- 验证ResourceManager HA
- 手动关闭node02的ResourceManager
sbin/yarn-daemon.sh stop resourcemanager - 通过HTTP 8088端口访问node01的ResourceManager查看状态
- 手动启动node02 的ResourceManager
sbin/yarn-daemon.sh start resourcemanager
附录:
- 关闭Journalnode: hadoop目录下:
sbin/hadoop-daemon.sh stop journalnode - 在刚开始搭建时,没有配置nodemanager内存大小,导致nodemanager启动不起来,查看日志,通过网络搜索,发现是内存不够,需要配置nodemanager的内存参数,见上文,内存参数为后来补充