来自崔庆才的个人博客
在爬取网页时,可能会出现一些问题,跑着跑着断掉了,报错了,连接丢失,,,这就是网站的反爬虫起作用了,一个IP访问的次数过于频繁就会被加入黑名单,过一会再放出来。。
网站的一般反爬策略:
限制IP访问频率,超过访问频率就断开(在每个请求前面加上 time.sleep;或者不停的换代理IP)
后台对访问进行统计,如果单个userAgent访问超过阀值,予以封锁。(反爬效果好,但是会造成误伤,一般的站点不会使用。。)
针对cookie的(这个解决办法很简单,一般的网站不会用)
今天针对1、2写个下载模块
首先使用了Python中的re模块
这是我们需要的模块:
requests
re
random(一个随机选择的模块)
(re 和 random 是python 自带的)
导入模块
import requests
import re
import random
思路:先找一个发布代理IP的网站,用代理IP来访问网站;当本地IP失效时,开始使用代理IP,代理IP失败六次后取消代理IP(这句话不明白啊,,,)
首先写一个基本的请求网页,并返回response的函数:
import requests
import re
import random
class download:
def get(self, url):
return requests.get(url)
很多网站会拒绝非浏览器请求,区分方法,(你发起的请求是否包含正常的User-Agent)
requests的请求的User-Agent大概是这样:python-requests/2.3.0 CPython/2.6.6 Windows/7 这个不是正常的User-Agent 所以我们得自己造一个来欺骗服务器(requests又一个headers参数能帮助我们伪装成浏览器!!)
网站会限制相同的User-Agent的访问频率,我们需要随机来一个User-Agent 下面是百度的User-Agent
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
修改上面的代码:
import requests
import re
import random
class download:
def __init__(self):
self.user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
def get(self, url):
UA = random.choice(self.user_agent_list) ##从self.user_agent_list中随机取出一个字符串(聪明的小哥儿一定发现了这是完整的User-Agent中:后面的一半段)
headers = {'User-Agent': UA} ##构造成一个完整的User-Agent (UA代表的是上面随机取出来的字符串哦)
response = requests.get(url, headers=headers) ##这样服务器就会以为我们是真的浏览器了
return response
可以实例化测试一下,header会不会变,,,
还有一点需要处理:限制IP频率的反爬虫!!
http://haoip.cc/tiqu.htm 这是一个获取代理IP的网站(也可以自己维护一个IP 代理池,不过有点麻烦。。)
先把这些IP爬取下来(用到了正则)
iplist = [] ##初始化一个list用来存放我们获取到的IP
html = requests.get("http://haoip.cc/tiqu.htm")##不解释咯
iplistn = re.findall(r'r/>(.*?)打印一下看看效果:
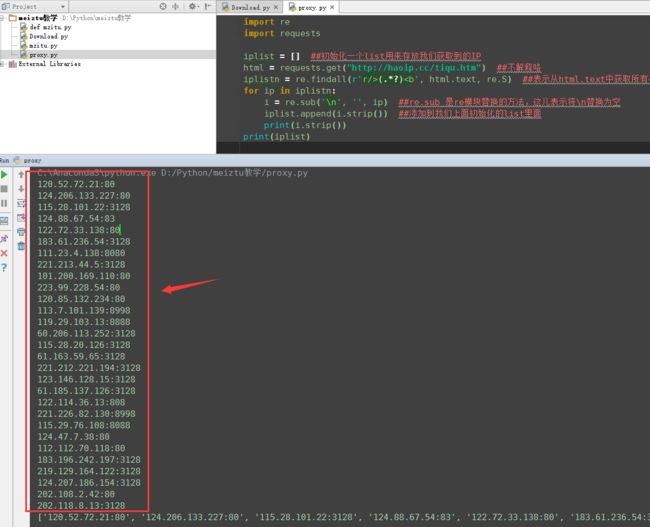
下面 [ ----- ] 中的内容就是我们添加进去的iplist这个初始化的list中的内容
现在把这段代码加到之前写的代码里面去,并判断是否使用了代理:
import re
import random
class download:
def __init__(self):
self.iplist = [] ##初始化一个list用来存放我们获取到的IP
html = requests.get("http://haoip.cc/tiqu.htm") ##不解释咯
iplistn = re.findall(r'r/>(.*?)自行测试
接下来判断,爬多少次换成代理爬取,多少次取消代理,,修改代码:
import requests
import re
import random
import time
class download:
def __init__(self):
self.iplist = [] ##初始化一个list用来存放我们获取到的IP
html = requests.get("http://haoip.cc/tiqu.htm") ##不解释咯
iplistn = re.findall(r'r/>(.*?) 0: ##num_retries是我们限定的重试次数
time.sleep(10) ##延迟十秒
print(u'获取网页出错,10S后将获取倒数第:', num_retries, u'次')
return self.get(url, timeout, num_retries-1) ##调用自身 并将次数减1
else:
print(u'开始使用代理')
time.sleep(10)
IP = ''.join(str(random.choice(self.iplist)).strip()) ##下面有解释哦
proxy = {'http': IP}
return self.get(url, timeout, proxy,) ##代理不为空的时候
else: ##当代理不为空
IP = ''.join(str(random.choice(self.iplist)).strip()) ##将从self.iplist中获取的字符串处理成我们需要的格式(处理了些什么自己看哦,这是基础呢)
proxy = {'http': IP} ##构造成一个代理
return requests.get(url, headers=headers, proxies=proxy, timeout = timeout) ##使用代理获取response
Xz = download() ##实例化
print(Xz.get("mzitu.com", 3)) ##打印headers
上面的代码添加了一个 timeout(防止超时),一个num_retries = 6(限制次数,6次过后使用代理)
接下来,使用6次代理后,取消代理,代码:
import requests
import re
import random
import time
class download:
def __init__(self):
self.iplist = [] ##初始化一个list用来存放我们获取到的IP
html = requests.get("http://haoip.cc/tiqu.htm") ##不解释咯
iplistn = re.findall(r'r/>(.*?) 0: ##num_retries是我们限定的重试次数
time.sleep(10) ##延迟十秒
print(u'获取网页出错,10S后将获取倒数第:', num_retries, u'次')
return self.get(url, timeout, num_retries-1) ##调用自身 并将次数减1
else:
print(u'开始使用代理')
time.sleep(10)
IP = ''.join(str(random.choice(self.iplist)).strip()) ##下面有解释哦
proxy = {'http': IP}
return self.get(url, timeout, proxy,) ##代理不为空的时候
else: ##当代理不为空
try:
IP = ''.join(str(random.choice(self.iplist)).strip()) ##将从self.iplist中获取的字符串处理成我们需要的格式(处理了些什么自己看哦,这是基础呢)
proxy = {'http': IP} ##构造成一个代理
return requests.get(url, headers=headers, proxies=proxy, timeout=timeout) ##使用代理获取response
except:
if num_retries > 0:
time.sleep(10)
IP = ''.join(str(random.choice(self.iplist)).strip())
proxy = {'http': IP}
print(u'正在更换代理,10S后将重新获取倒数第', num_retries, u'次')
print(u'当前代理是:', proxy)
return self.get(url, timeout, proxy, num_retries - 1)
else:
print(u'代理也不好使了!取消代理')
return self.get(url, 3)
OK ,(一个健壮的代码还包括的其他内容:判断地址是否是 robots.txt 文件禁止获取的;错误状态判断是否是服务器出错,限制爬虫深度防止掉入爬虫陷阱 等。。)
接下来,把这个模块使用到上一篇爬出红里面去,,(用法:将这个py文件放在和上一篇文件相同的文件夹里面,并新建一个init.py文件,)
在爬虫里面导入下载模块即可,class继承一下下载模块,然后替换掉上一篇爬虫里面的全部requests.get,为download.get即可,还必须加上timeout参数。。代码:
from bs4 import BeautifulSoup
import os
from Download import download
class mzitu(download):
def all_url(self, url):
html = download.get(self, url, 3) ##这儿替换了,并加上timeout参数
all_a = BeautifulSoup(html.text, 'lxml').find('div', class_='all').find_all('a')
for a in all_a:
title = a.get_text()
print(u'开始保存:', title)
path = str(title).replace("?", '_')
self.mkdir(path)
os.chdir("D:\mzitu\\"+path)
href = a['href']
self.html(href)
def html(self, href):
html = download.get(self, href, 3)
max_span = BeautifulSoup(html.text, 'lxml').find_all('span')[10].get_text()
for page in range(1, int(max_span) + 1):
page_url = href + '/' + str(page)
self.img(page_url)
def img(self, page_url):
img_html = download.get(self, page_url, 3) ##这儿替换了
img_url = BeautifulSoup(img_html.text, 'lxml').find('div', class_='main-image').find('img')['src']
self.save(img_url)
def save(self, img_url):
name = img_url[-9:-4]
print(u'开始保存:', img_url)
img = download.get(self, img_url, 3) ##这儿替换了,并加上timeout参数
f = open(name + '.jpg', 'ab')
f.write(img.content)
f.close()
def mkdir(self, path): ##这个函数创建文件夹
path = path.strip()
isExists = os.path.exists(os.path.join("D:\mzitu", path))
if not isExists:
print(u'建了一个名字叫做', path, u'的文件夹!')
os.makedirs(os.path.join("D:\mzitu", path))
return True
else:
print(u'名字叫做', path, u'的文件夹已经存在了!')
return False
Mzitu = mzitu() ##实例化
Mzitu.all_url('http://www.mzitu.com/all') ##给函数all_url传入参数 你可以当作启动爬虫(就是入口)
更新:今天做教程的时候发现我忽略了一个问题,上面的写法,属于子类继承父类,这种写法 子类没法用init;所以我改了一下写法,(其余都没变,不用担心。)直接贴代码了:
import requests
import re
import random
import time
class download():
def __init__(self):
self.iplist = [] ##初始化一个list用来存放我们获取到的IP
html = requests.get("http://haoip.cc/tiqu.htm") ##不解释咯
iplistn = re.findall(r'r/>(.*?) 0: ##num_retries是我们限定的重试次数
time.sleep(10) ##延迟十秒
print(u'获取网页出错,10S后将获取倒数第:', num_retries, u'次')
return self.get(url, timeout, num_retries-1) ##调用自身 并将次数减1
else:
print(u'开始使用代理')
time.sleep(10)
IP = ''.join(str(random.choice(self.iplist)).strip()) ##下面有解释哦
proxy = {'http': IP}
return self.get(url, timeout, proxy,) ##代理不为空的时候
else: ##当代理不为空
try:
IP = ''.join(str(random.choice(self.iplist)).strip()) ##将从self.iplist中获取的字符串处理成我们需要的格式(处理了些什么自己看哦,这是基础呢)
proxy = {'http': IP} ##构造成一个代理
return requests.get(url, headers=headers, proxies=proxy, timeout=timeout) ##使用代理获取response
except:
if num_retries > 0:
time.sleep(10)
IP = ''.join(str(random.choice(self.iplist)).strip())
proxy = {'http': IP}
print(u'正在更换代理,10S后将重新获取倒数第', num_retries, u'次')
print(u'当前代理是:', proxy)
return self.get(url, timeout, proxy, num_retries - 1)
else:
print(u'代理也不好使了!取消代理')
return self.get(url, 3)
request = download() ##
这个模块多了一个 reqests = download()
第二个(def mzitu.py):
from bs4 import BeautifulSoup
import os
from Download import request ##导入模块变了一下
from pymongo import MongoClient
class mzitu():
def all_url(self, url):
html = request.get(url, 3) ##这儿更改了一下(是不是发现 self 没见了?)
all_a = BeautifulSoup(html.text, 'lxml').find('div', class_='all').find_all('a')
for a in all_a:
title = a.get_text()
print(u'开始保存:', title)
path = str(title).replace("?", '_')
self.mkdir(path)
os.chdir("D:\mzitu\\"+path)
href = a['href']
self.html(href)
def html(self, href):
html = request.get(href, 3)##这儿更改了一下(是不是发现 self 没见了?)
max_span = BeautifulSoup(html.text, 'lxml').find_all('span')[10].get_text()
for page in range(1, int(max_span) + 1):
page_url = href + '/' + str(page)
self.img(page_url)
def img(self, page_url):
img_html = request.get(page_url, 3) ##这儿更改了一下(是不是发现 self 没见了?)
img_url = BeautifulSoup(img_html.text, 'lxml').find('div', class_='main-image').find('img')['src']
self.save(img_url)
def save(self, img_url):
name = img_url[-9:-4]
print(u'开始保存:', img_url)
img = request.get(img_url, 3) ##这儿更改了一下(是不是发现 self 没见了?)
f = open(name + '.jpg', 'ab')
f.write(img.content)
f.close()
def mkdir(self, path):
path = path.strip()
isExists = os.path.exists(os.path.join("D:\mzitu", path))
if not isExists:
print(u'建了一个名字叫做', path, u'的文件夹!')
os.makedirs(os.path.join("D:\mzitu", path))
return True
else:
print(u'名字叫做', path, u'的文件夹已经存在了!')
return False
Mzitu = mzitu() ##实例化
Mzitu.all_url('http://www.mzitu.com/all') ##给函数all_url传入参数 你可以当作启动爬虫(就是入口)
改动的地方有明确的标注!!