前段时间学习了人大薛薇老师的统计学基础课程,最近刚交了统计学作业,得到了TDU同学和薛老师的高度评价,并与薛老师交流了关于“原假设”的问题。在这里和大家分享一下这段学习历程,与大家共勉,也欢迎大家提一些建议哈。
薛老师这次课程主要是基于案例探讨统计分析方法的基本原理,她带来的第一个案例是北京市空气监测。
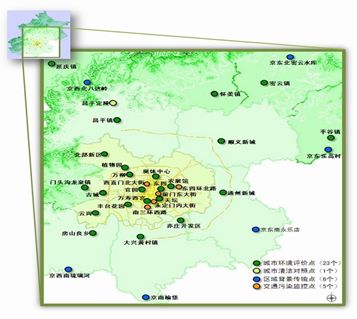
开头便告诉我们从统计视角看案例数据,确定研究的样本、步骤、问题,只研究供暖季的数据,数据处理的两种方式:
第一,计算该时段各站点各变量均值,样本量35
第二,忽略时间上的差异,视数据为截面数据。优势:有效扩大了样本量(采纳)
研究步骤和问题:
第一步,样本数据的描述统计。涉及问题:
了解数据缺失状况
基本描述统计
诊断极端值:从统计视角检测PM2.5爆表情况
第二步,依据样本,对样本来自的总体参数进行估计和对比。涉及问题:
估计北京市供暖季PM2.5(一个总体)的平均值
交通污染对PM2.5的影响:对比西直门北(区域)和定陵(区域)供暖季的PM2.5(两总体)的平均值
第三步,基于样本数据的深入研究
探讨PM2.5成因;对比北京四个不同区域(西北、西南、正南、东/东南)PM2.5总体均值差异
探讨PM2.5的空间特征和空气质量的区域划分
探讨AQI的全面性问题
接下来针对研究步骤和问题展开讲解,从最基础的直方图、概率密度函数、四分位数等内容到十分经典的假设检验、Bootstrap、多元线性回归、聚类分析、主成分分析都有讲解。
然后为我们带来了第二个案例,基于HR的调查研究IT员工离职问题,研究离职主要因素并预测是否离职。因为这里研究的二分类变量与其他变量之间的关系,对二分类的被解释变量不可以直接采用一般多元线性回归分析方法,因此进行改进如下:
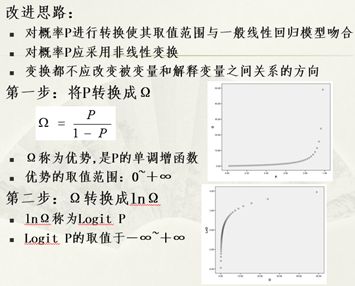
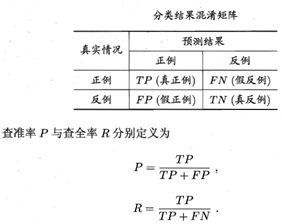
建立二项Logit模型,并讲解二分类模型的评价问题,查准率和查全率(覆盖率)和ROC曲线。
正所谓“实践是检验真理的唯一标准”,在上完课后就进入作业环节。
说实话,薛老师布置的作业并不难,只要好好复习课件,一般都能答出来,但复习课件不仅仅是为了完成作业,同时也是一个理解吸收提高的过程。(ps:自己的作业也十分荣幸的得到了TDU同学和薛老师满分+的评价,哈哈。)
以第一题为例,原题如下:
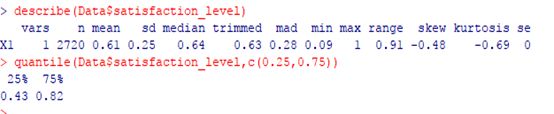
一、(15分)某大型企业HR通过随机调查获得了2720名技术员工对企业满意度的打分(取值范围:0~1)数据。对该样本的基本描述统计结果如下。
请问:
1、 请基于上述计算结果,粗略绘制满意度打分的概率密度分布曲线,并在图中画出有相同均值和标准差的正态分布曲线。(5分)
考察基础知识,概率密度分布曲线和正态分布曲线,这两个知识点虽然薛老师没有直接讲解,但都比较基础,要求我们有一定的R自学能力,查一下就能知道结果。通过plot绘制出density概率密度分布曲线,通过mean和sd求出均值和方差,然后通过curve绘制出dnorm正态分布曲线。
核心代码如下:
plot(density(Data$satisfaction_level))
mean_data = mean(Data$satisfaction_level)
sd_data = sd(Data$satisfaction_level)
curve(dnorm(x,mean_data,sd_data))
个人解答如下:
(1)满意度打分的概率密度分布曲线如图所示,可以看出,并不符合正态分布。
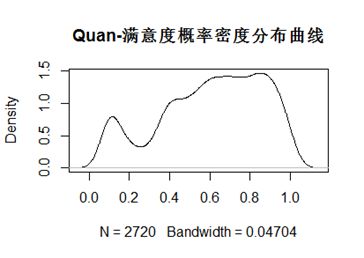
(2)求得均值为0.6078971,标准差为0.2541932,相应的正态分布曲线如图,
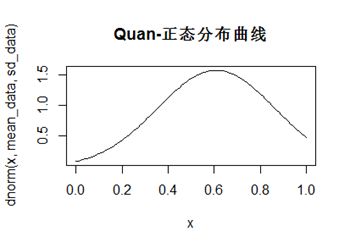
2、 基于上述计算结果,你认为满意度打分中是否存在异常数据?为什么?(5分)
正所谓外行看热闹,内行看门道,异常数据不是你觉得有异常就异常,需要理论依据,理论依据是啥?答:阈值,大于1.5倍的四分位差,详见PPT第17页。
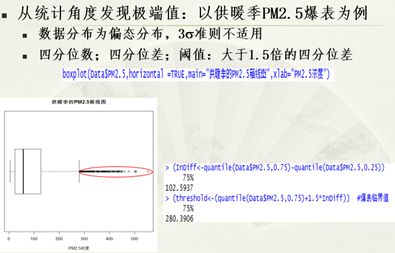
个人解答如下:
答:满意度打分不存在异常数据。为非对称分布。
(1)先计算1.5倍的四分位差:
1.5*(quantile(Data$satisfaction_level,c(0.25,0.75))[2]-
quantile(Data$satisfaction_level,c(0.25,0.75))[1])
得到标准0.585。
(2)在计算上四分位数和下四分位数:
quantile(Data$satisfaction_level,c(0.25,0.75))
得到0.43(25%)和0.82(75%)
(3)计算出最值:
describe(Data$satisfaction_level)
得到0.09(min)和1(max)
因(0.43-0.585)不存在和(0.82+0.585)不存在,故无异常点。
3、基于上述计算结果,如果希望刻画满意度打分的样本分布特征,应给出哪些最基本的描述统计结果?它们的含义是什么?(5分)
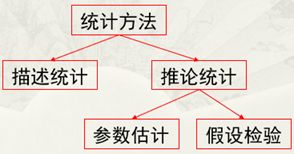
这道题考的十分基础,最基本的描述统计结果,可以参考Basic descriptive statistics useful for psychometrics里的描述统计量,但背后是统计方法中的描述统计,是统计学的基石,也是个人统计学的基本功,虽然简单,但必须重视。
个人解答如下:
答:可以有以下描述统计结果,
n:2720,一共有2720名技术员工的满意度数据;
mean:0.61,满意度的平均值为0.61分;
sd:0.25,满意度的标准差为0.25,反映满意度的离散程度;
min:0.09,满意度的最值,最低分0.09;
max:1,满意度的最值,最高分1;
skew:-0.48,左偏,偏离度-0.48;
se:0,均值的标准误差StandardError
备注:标准误=标准差/√n n是样本量。公式意思是:标准误等于标准差除以样本量的平方根,
其他题目类似,十分经典,不在一一展开。
之后,我还与薛老师进一步交流了关于“原假设”的问题。
我们先看问题以及我的解答:
二、(25分)员工甲认为:企业技术员工的工作压力大,他们对企业满意度打分的总体平均值不会高于0.5分。基于第一题的随机样本数据,员工乙利用假设检验方法对员工甲的观点进行了验证,分析结果如下。

请问:
员工乙采用的是哪种统计检验方法?请给出假设检验的原假设。(5分)
答:采用的是单个总体均值的假设检验;由alternative hypothesis:
true mean is not equal to 0.5知原假设为真实的均值等于0.5。
但薛老师认为原假设是H0:μ0≤0.5
我:如果按题意他们对企业满意度打分的总体平均值不会高于0.5分和最终结果平均值高于0.5分,那么原假设H0:μ0≤0.5。但如果看R执行的结果alternative hypothesis: true mean is not equal to 0.5,那么原假设为真实的均值等于0.5,即μ0 = 0.5。在这里是不是应该以R执行的结果为准。薛老师:程序给出的都是双侧检验的概率P值,单侧检验用它的1/2即可最后我提出加上alternative = "greater"这个参数,这样alternative被则假设、原假设、R结果、题意都统一,就没有歧义了。
t.test(Data$satisfaction_level,mu=0.5,side="less",alternative = "greater")

得到了薛老师的肯定,最终达成一致。
一场精彩的统计学课程结束了,但我们人生的学习之旅还有很长的路要走。
在此,感谢薛老师的精彩讲解,感谢TDU引入这样一门好课,感谢努力的自己。
时间在流逝,万物在成长,引用国学大师钱穆老师的一句话作为结语,过去未去,未来已来。