目录
基本概念及问题
图的三种表示方式
现实应用
图的遍历
最短路径 - Dijkstra算法
拓扑排序
最小生成树
基本概念及问题
V 顶点集
E边集
相关概念:有向图,无向图,带权图,有向无环图,出度,入度,最短路径等。
图的遍历:DFS BFS 常见可以解决的问题有: 联通分量 Flood Fill 寻路 走迷宫 迷宫生成 无权图的最短路径环的判断
最小生成树问题(Minimum Spanning Tree)Prim Kruskal
最短路径问题(Shortest Path)Dijkstra Bellman-Ford
拓扑排序(Topological sorting)
图的三种表示(以下面这个图为例):

1. Edge Lists
代表边的集合,或者数组。可以用一个二维数组表示一条边(如:[2,3]),或者用一个包含两个顶点信息的对象来表示。如果边上有权重信息,可以再增加一维数组,或者往边类型中再增加一个字段代表权重信息。

空间:O(|E|)。
确定一条边需要时间O(|E|)。
2. 邻接矩阵(Adjacency Matrix)
二维数组。

空间:O(V2)。即便对于松散矩阵,也需要这么多空间。对于无向图,矩阵是对称的;有向图,不一定对称。
确定一条边所需要时间:O(1)。
确定邻接点:O(|V|)。
3. 邻接表(Adjacency Lists)
前两种表示方式的结合。一个V集合,对每个顶点,维护一个由其所有邻接点组成的列表。

空间:无向图O(2|E|),有向图O(|E|)
确定一条边所需要时间:O(d),d为度。
确定邻接点:O(1)。
衡量每种表示利弊的标准:
1. 存储需要的空间
2. 确定给定的两个顶点之间是否存在一条边所需要的时间
3. 找出一个给定顶点的邻接点所需要的时间
根据不同的应用场景选择最合适的表示方式。
现实应用
可以用图对现实中许多系统建模。
比如对交通流量建模,顶点可以表示街道的十字路口,边表示街道。加权的边可以表示限速或者车道的数量。建模人员可以用这个系统来判断最佳路线及最有可能堵车的街道。
任何运输系统都可以用图来建模。比如,航空公司可以用图来为其飞行系统建模。将每个机场看成顶点,将经过两个顶点的每条航线看作一条边。加权的边可以看作从一个机场到另一个机场的航班成本,或两个机场之间的距离,这取决与建模的对象是什么。
包含局域网和广域网(如互联网)在内的计算机网络,同样经常用图来建模。
另一个可以用图来建模的实现系统是消费市场,顶点可以用来表示供应商和消费者。
图的遍历
深度优先搜索(DFS)
递归实现,或者采用非递归,需要定义栈。

注意 深度优先算法属于盲目搜索,无法保证搜索到的路径为最短路径。
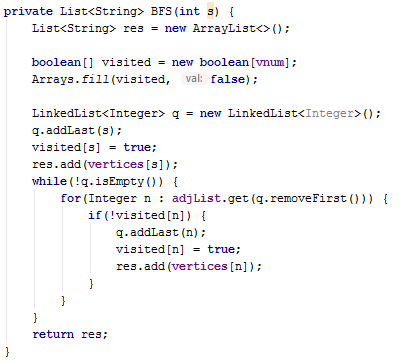
广度优先搜索(BFS)
需要使用队列实现。
在执行广度优先搜索时,会自动查找从一个顶点到另一个相邻顶点的最短路径。例如:要查找从顶点A到顶点D的最短路径,我们首先会查找从A到D是否有任何一条单边路径,接着查找两条边的路径,以此类推。这正是广度优先搜索的搜索过程,因此我们可以轻松地修改广度优先搜索算法,找出最短路径。
最短路径 - Dijkstra算法
算法特点:
迪科斯彻算法使用了广度优先搜索解决赋权有向图或者无向图的单源最短路径问题,算法最终得到一个最短路径树。该算法常用于路由算法或者作为其他图算法的一个子模块。
算法的思路
Dijkstra算法采用的是一种贪心的策略,声明一个数组dis来保存源点到各个顶点的最短距离和一个保存已经找到了最短路径的顶点的集合:T,初始时,原点 s 的路径权重被赋为 0 (dis[s] = 0)。若对于顶点 s 存在能直接到达的边(s,m),则把dis[m]设为w(s, m),同时把所有其他(s不能直接到达的)顶点的路径长度设为无穷大。初始时,集合T只有顶点s。 然后,从dis数组选择最小值,则该值就是源点s到该值对应的顶点的最短路径,并且把该点加入到T中,OK,此时完成一个顶点, 然后,我们需要看看新加入的顶点是否可以到达其他顶点并且看看通过该顶点到达其他点的路径长度是否比源点直接到达短,如果是,那么就替换这些顶点在dis中的值。 然后,又从dis中找出最小值,重复上述动作,直到T中包含了图的所有顶点。
LeetCode: 743. Network Delay Time
拓扑排序
在图论中,拓扑排序(Topological Sorting)是一个有向无环图(DAG, Directed Acyclic Graph)的所有顶点的线性序列。该序列必须满足下面两个条件:
1. 每个顶点出现且只出现一次
2. 若存在一条从顶点A 到顶点 B 的路径,那么在序列中顶点 A 出现在顶点 B 的前面
计算拓扑排序的方法:
1. 从DAG 图中选择一个 没有前驱(即入度为0)的顶点并输出。
2. 从图中删除该顶点和所有以它为起点的有向边。
3. 重复1 和 2 直到当前的 DAG 图为空或当前图中不存在无前驱的顶点为止。后一种情况说明有向图中必然存在环。
通常,一个有向无环图可以有一个或多个拓扑排序序列。
拓扑排序通常用来“排序”具有依赖关系的任务。
LeetCode: 207. Course Schedule
LeetCode: 210. Course Schedule II
最小生成树
相关概念
连通图:在无向图中,若任意两个顶点vi与vj都有路径相通,则称该无向图为连通图。
强连通图:在有向图中,若任意两个顶点vi与vj都有路径相通,则称该有向图为强连通图。
连通网:在连通图中,若图的边具有一定的意义,每一条边都对应着一个数,称为权;权代表着连接连个顶点的代价,称这种连通图叫做连通网。
生成树:一个连通图的生成树是指一个连通子图,它含有图中全部n个顶点,但只有足以构成一棵树的n-1条边。一颗有n个顶点的生成树有且仅有n-1条边,如果生成树中再添加一条边,则必定成环。
最小生成树:在连通网的所有生成树中,所有边的代价和最小的生成树,称为最小生成树。
下面介绍两种求最小生成树算法
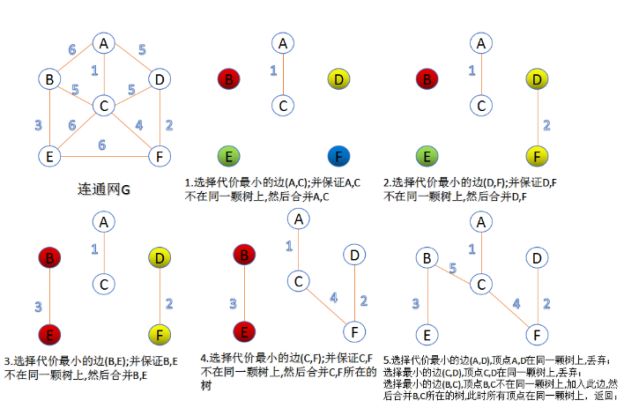
1.Kruskal算法
此算法可以称为 “加边法”,初始最小生成树边数为0,每迭代一次就选择一条满足条件的最小代价边,加入到最小生成树的边集合里。
1) 把图中的所有边按代价从小到大排序;
2) 把图中的 n 个顶点看成独立的 n 棵树组成的森林;
3) 按权值从小到大选择边,所选的边连接的两个顶点 ui,vi 应属于两颗不同的树,则成为最小生成树的一条边,并将这两颗树合并作为一颗树。
4) 重复上述步骤,直到所有顶点都在一颗树内或者有 n-1 条边为止。
如图所示:
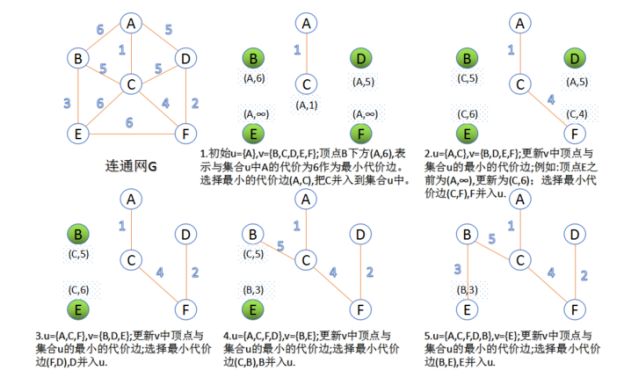
2. Prime算法
此算法可以称为 “加点法”,每次迭代选择代价最小的边对应的点,加入到最小生成树中。算法从某一个顶点 s 开始,逐渐长大覆盖整个连通网的所有顶点。
1) 图的所有顶点集合为V;初始令集合u = {s},v = V−u;
2) 在两个集合u,v能够组成的边中,选择一条代价最小的边(u0, v0),加入到最小生成树中,并把v0并入到集合u中。
3) 重复上述步骤,直到所有顶点都在一颗树内或者有n-1条边为止。
如图所示:
引用:
数据结构图的表示及相关算法&LeetCode题目
算法导论--最小生成树(Kruskal和Prim算法)
数据结构与算法:图和图算法(一)
Analysis of breadth-first search
最短路径问题---Dijkstra算法详解