一、云服务器配置:为Python安装scrapy
1)检查当前服务器是否安装Python scrapy模块
Python
import scrapy
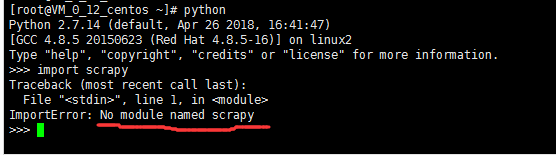
Python版本已升级为:2.7.14
显示:No module named scrapy,没有安装scrapy框架
2)退出Python交互,使用yum安装依赖和scrapy
yum install python-devel

提示:路径不存在
原因:查得可能的原因是Python版本升级混乱造成yum无法使用。
3)修复yum
找到文件/usr/bin/yum
将文件第一行修改为:#!/usr/bin/python2.7
保存修改
yum install python-devel
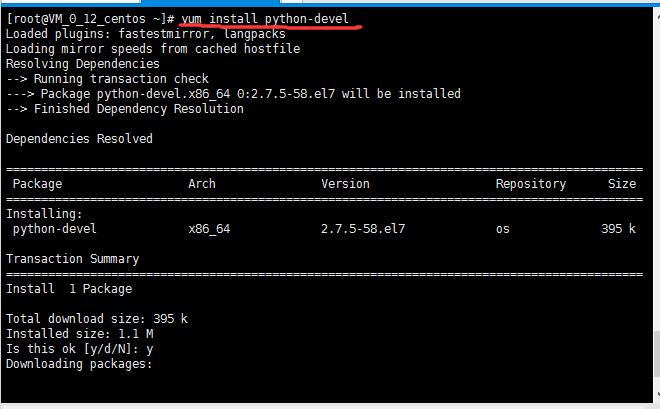
Is this ok:y
安装失败
出现新的错误:找不到路径

找到文件:/usr/libexec/urlgrabber-ext-down
修改文件第一行为:#!/usr/bin/python2.7
保存并退出
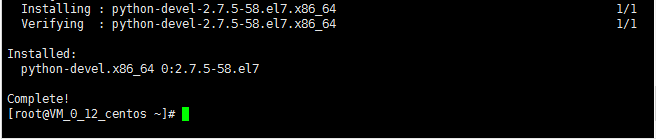
yum install python-devel
y
提示安装成功:
4)安装其他依赖
参考链接:
https://blog.csdn.net/u012375924/article/details/51244485
5)安装scrapy
pip install scrapy
出现错误:Twisted版本不匹配

原因:由于Python版本升级造成的版本不匹配问题。
解决:重新下载安装twisted
参考链接:
https://blog.csdn.net/guanlq/article/details/73388022
https://blog.csdn.net/shudaqi2010/article/details/21303921
https://www.jianshu.com/p/cc420c34ee3c
https://blog.csdn.net/liuzemeeting/article/details/79218734
其他解决办法,参考链接:
http://www.voidcn.com/article/p-hrduztxi-vn.html
https://blog.csdn.net/qq_32783353/article/details/72866685
在重新安装twisted后安装scrapy:
安装成功,由于之前版本升级造成的问题,这里所安装的scrapy不在系统初始设置的环境变量中,以后使用的时候需要注意路径的问题。

6)检查scrapy安装
进入Python交互环境,import scrapy enter,结果如下所示:

引用成功。
查看scrapy版本,测试scrapy:
scrapy version
scrapy bench
7)总结
小组购买的腾讯云9.9元学生套餐云服务器,操作系统:centos7.2,已经默认配置好了Python2.7.5,并且已经安装好了相应的pip和setuptools,yum的使用要依赖系统默认配置的Python版本。在此情况下进行Python的版本升级,会为以后的Python模块的安装造成一系列莫名的问题,增加了操作负担。如果真的需要更高版本的Python,建议重新下载安装Python的更高版本,并进行配置。
当然,如果Linux操作基础比较扎实,可以不使用yum,手动安装配置scrapy。对linux操作不熟悉不推荐使用此方法,可能会因为安装路径和环境变量配置的错误,为后来的使用造成更多困难。
二、测试Python scrapy配置
1)demo学习
实验目的:在服务器上测试scrapy配置,运行爬虫示例
demo功能:爬取四川大学公共管理学院全体教师信息
demo链接:https://blog.csdn.net/qq_38425619/article/details/71814637
跑demo过程中遇到的问题:
问题一:配置问题,缺少requests包
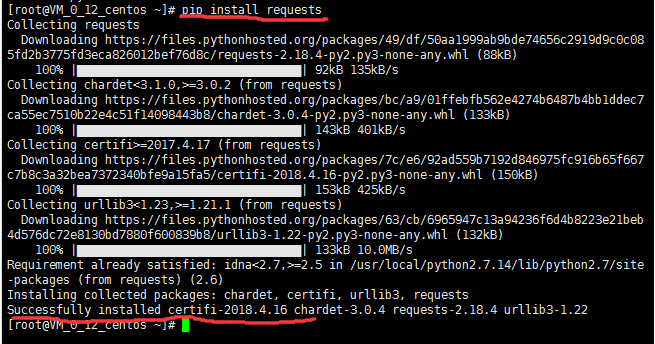
问题二:缺乏sqlite标准库的支持,如下图所示
原因分析:由于Python版本升级造成的问题,在第一次默认安装时标准库已经预编译,升级后新版本的Python认不到
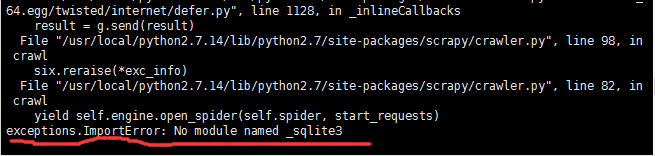
解决:解决标准库无法引用的问题,目前大致有两种思路:1.重新安装编译Python。2.找到已编译的sqlite原文件,将文件复制到升级后的正确路径下。此处选择的第二种方法,具体操作细节可参考以下链接(包括方法一)
参考链接:
https://www.jianshu.com/p/fd632477e7b2
https://blog.csdn.net/jaket5219999/article/details/53512071
https://blog.csdn.net/feifeilyj/article/details/52678011
https://blog.csdn.net/xjmxym/article/details/73621607
https://blog.csdn.net/jaket5219999/article/details/53512071
引用测试结果如下:

成功引用。
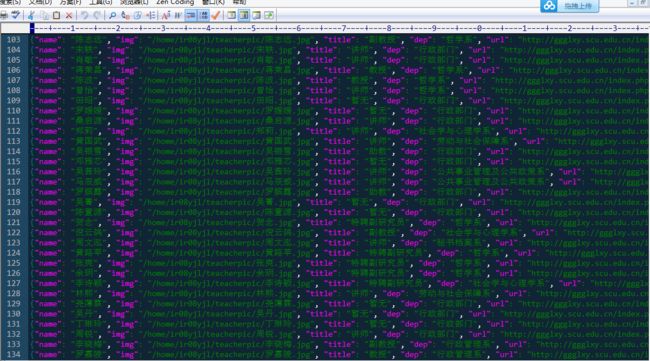
问题三:爬取结果导出json出错,如下图所示


解决:找到文件pipelines.py,添加json引用
重新执行爬虫,导出json成功,下载teacher.json文件到本地,打开结果如下,共134位教师信息,部分截图:
2)demo分析与完善
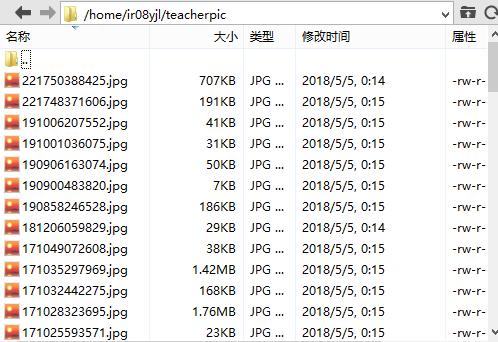
所爬取的数据中,显示的教师图片存放的服务器路径如下:
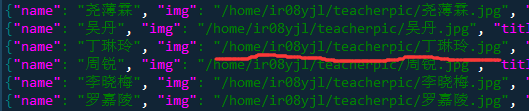

原因一:第32行,正则匹配提取图片地址出错。
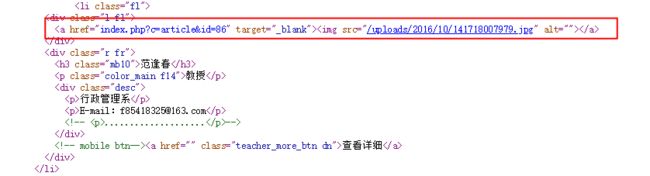
解决:
将原正则表达式:
div[@class='l fl']/img/@src
修改为:
div[@class='l fl']/a/img/@src
原因二:只指定了图片路径,保存在item中,没有执行下载图片操作。
解决:
增添如下语句:
urllib.urlretrieve(img_src,img_path)
其中img_src为图片地址,img_path为图片保存在服务器上的目录路径