
本文内容概要:
- R语言数据结构及实例操作
- Python语言数据结构及实例操作
R语言数据结构及实例解析
接下开始学习R语言的向量、矩阵、数组、数据框、列表这五个数据结构。
1.向量
向量是用于存储数值型、字符型或逻辑型数据的一维数组。函数c()可用来创建向量。单个向量中的数据必须拥有相同的数据类型.
> name <-c('猴子','李四','王五','张三'); #创建一个向量,并且赋值给name
> name
[1] "猴子" "李四" "王五" "张三"'猴子','李四','王五','张三');
查看向量有多少个元素
> length(name)
[1] 4
查找其中的某个元素
> name[1]
[1] "猴子" #得出位置1的元素
> name[2]
[1] "李四" #得出位置2的元素
> name[1:3]
[1] "猴子" "李四" "王五" #得出位置1到3的元素
增加一个元素
> name<-c(name,'小麻子')
> name
[1] "猴子" "李四" "王五" "张三" "小麻子"
2.矩阵
矩阵是一个二维数组,只是每个元素都拥有相同的模式(数值型、字符型或逻辑型) 。可通过函数matrix()创建矩阵。一般使用格式为:
myymatrix <- matrix(vector, nrow=number_of_rows, ncol=number_of_columns,
byrow=logical_value, dimnames=list(
char_vector_rownames, char_vector_colnames))
其中vector包含了矩阵的元素,nrow和ncol用以指定行和列的维数, dimnames包含了可选的、以字符型向量表示的行名和列名。选项byrow则表明矩阵应当按行填充(byrow=TRUE)还是按列填充(byrow=FALSE),默认情况下按列填充。
创建矩阵
> data<-c(1,2,3,4,5,6)
> rnames<-c('r1','r2')
> cnames<-c('c1','c2','c3')
> a<-matrix(data=data,nrow=2,ncol=3,byrow=TRUE,dimnames = list(rnames,cnames))
> a
c1 c2 c3
r1 1 2 3
r2 4 5 6
查找
> a[1,] #得出矩阵的第一行
c1 c2 c3
1 2 3
> a[,1] #得出矩阵的第一列
r1 r2
1 4
> a[1,2] #得出行为1,列为2的元素
[1] 2
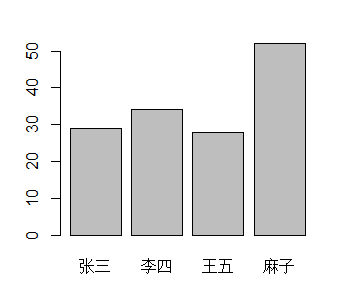
矩阵在绘制条形图中的一个应用
> age<-c(29,34,28,52)
> rname a<-matrix(age,nrow=4,ncol=1,dimnames=list(rnames,cnames))
> a
年龄
张三 29
李四 34
王五 28
麻子 52
> barplot(a[,'年龄'])
可看到年龄分布图如下
3.数组
数组(array)与矩阵类似,但是维度可以大于2。数组可通过array函数创建,形式如下:
myarray <- array(vector, dimensions, dimnames)
其中vector包含了数组中的数据, dimensions是一个数值型向量,给出了各个维度下标的最大值,而dimnames是可选的、各维度名称标签的列表。如下创建了一个三维(2×3×4)数值型数组。
> dim1 <- c("A1", "A2")
> dim2 <- c("B1", "B2", "B3")
> dim3 <- c("C1", "C2", "C3", "C4")
> z <- array(1:24, c(2, 3, 4), dimnames=list(dim1, dim2, dim3))
> z
, , C1
B1 B2 B3
A1 1 3 5
A2 2 4 6
, , C2
B1 B2 B3
A1 7 9 11
A2 8 10 12
, , C3
B1 B2 B3
A1 13 15 17
A2 14 16 18
, , C4
B1 B2 B3
A1 19 21 23
A2 20 22 24
4.数据框
与矩阵不同的是,数据框的不同列可以包含不同模式(数值型、字符型等)的数据。每一列数据的模式必须唯一,但是却可以将多个模式的不同列放到一起组成数据框。数据框可通过函数data.frame()创建:
mydata <- data.frame(col1, col2, col3,...)
其中的列向量col1、 col2、 col3等可为任何类型(如字符型、数值型或逻辑型)。每一列的名称可由函数names指定。
实例如下:
> patientID <- c(1, 2, 3, 4)
> age <- c(25, 34, 28, 52)
> diabetes <- c("Type1", "Type2", "Type1", "Type1")
> status <- c("Poor", "Improved", "Excellent", "Poor")
> patientdata <- data.frame(patientID, age, diabetes, status)
> patientdata
patientID age diabetes status
1 1 25 Type1 Poor
2 2 34 Type2 Improved
3 3 28 Type1 Excellent
4 4 52 Type1 Poor
选取数据框中的元素
> patientdata[1:2] #选取1、2两列
patientID age
1 1 25
2 2 34
3 3 28
4 4 52
---------------
> patientdata[c("diabetes", "status")] #选取特定的'diabetes','status'两列
diabetes status
1 Type1 Poor
2 Type2 Improved
3 Type1 Excellent
4 Type1 Poor
-------------------
> patientdata$age # 其中$是用来选取一个给定数据框中的某个特定变量。
[1] 25 34 28 52
------------------
> type2<-patientdata[patientdata$diabetes=='Type2',] #查找'Type2'型的病人
> type2
patientID age diabetes status
2 2 34 Type2 Improved
----------------------------------
> type2.number<-nrow(type2) #'Type2'型的病人有多少个
> type2.number
[1] 1
数据框的增加
- 增加一行
> patientID<-c(5)
> diabetes<-c('Type2')
> status<-c('poor')
> age<-c(30)
> newpatient<-data.frame(patientID,diabetes,status,age)
> newpatient
patientID diabetes status age
1 5 Type2 poor 30
> patientdata<-rbind(patientdata,newpatient) #rbind是根据行进行合并,就是自动往下面顺延,但要求所有数据列数是相同的才能用rbind.
> patientdata
patientID age diabetes status
1 1 25 Type1 Poor
2 2 34 Type2 Improved
3 3 28 Type1 Excellent
4 4 52 Type1 Poor
5 5 30 Type2 poor
- 增加一列
> intime<-c('1月1日','2月2日','3月3日','4月4日','5月5日')
> patientdata<-cbind(patientdata,intime) #cbind是根据列进行合并,合并的前提是所有数据行数相等。
> patientdata
patientID age diabetes status intime
1 1 25 Type1 Poor 1月1日
2 2 34 Type2 Improved 2月2日
3 3 28 Type1 Excellent 3月3日
4 4 52 Type1 Poor 4月4日
5 5 30 Type2 poor 5月5日
5.列表
一般来说,列表就是一些对象(或成分,component)的有序集合。
列如某个列表中可能是若干向量、矩阵、数据框,甚至其他列表的组合。可以使用函数list()创建列表:
mylist <- list(object1, object2, ...)
还可以为列表中的对象命名:
mylist <- list(name1=object1, name2=object2, ...)
创建一个列表
> g <- "My First List"
> h <- c(25, 26, 18, 39)
> j <- matrix(1:10, nrow=5)
> k <- c("one", "two", "three")
> mylist <- list(title=g, ages=h, j, k)
> mylist
$title
[1] "My First List"
$ages
[1] 25 26 18 39
[[3]]
[,1] [,2]
[1,] 1 6
[2,] 2 7
[3,] 3 8
[4,] 4 9
[5,] 5 10
[[4]]
[1] "one" "two" "three"
> mylist[[2]] #指那个含有四个元素的向量
[1] 25 26 18 39
> mylist[["ages"]] #指那个含有四个元素的向量
[1] 25 26 18 39
Python语言数据结构及实例解析
接下来主要讲解数组、元组、字典三个数据结构
1.列表
列表的数据项不需要具有相同的类型
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可
创建列表

访问列表中的值
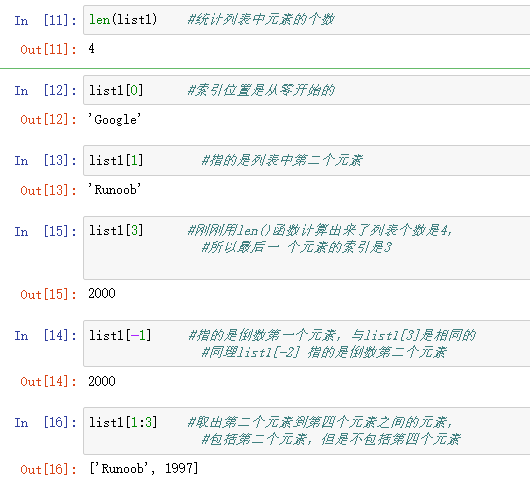
列表的增删查
列表通过insert函数插入,函数的第一个参数表示插入的索引位置,第二个表示插入的值。

或者使用append,直接在列表末尾添加上元素。

如果要删除特定位置的元素,用pop函数。如果函数没有选择数值,默认删除最后一个元素,如果有,则删除数值对应索引的元素。


更改元素其实是不需要用到函数,直接选取元素重新赋值即可。

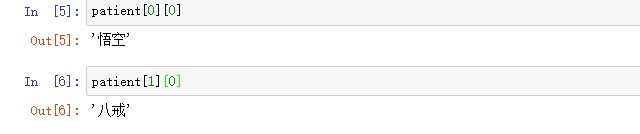
创建多维列表

多维列表中查找

2.元组
元组,它和数列非常相似,但是用圆括号表示。但是它最大的特点是不能修改。
创建元组

查找和列表是相同的

3.字典
字典dict全称dictionary,以键值对key-value的形式存储。所谓键值,就是将key作为索引存储,用大括号表示。
创建字典

通过key索引来查找value值

通过赋值来修改字典

dict中删除key和list一样,通过pop函数。

基础的数据类型差不多就这些了,更多的就交给谷歌吧。