正文
我们平常写程序的时候,一般都是使用一个好用的IDE,然后写好代码,run一下程序就运行起来了,但是不知道大家是不是也思考过程序到底是怎么运行起来的呢?
这其实是一个很复杂的过程,我的了解也是非常的浅显,所以只能简单介绍一下它的大概步骤。
一个典型的程序运行步骤如下:
操作系统在创建进程后,把控制权交到程序的入口,这个入口往往是运行库中的某个入口函数
入口函数对运行库和程序运行环境进行初始化,包括堆、I/O、线程、全局变量的构造
入口函数在完成初始化后,调用main函数,正式开始执行程序主体部分
main函数执行完毕后,返回到入口函数,入口函数进行清理工作,包括全局变量析构、堆销毁、关闭I/O等,然后系统调用结束进程
Build一个程序实际上包含四个步骤:
预处理(Prepression)
编译(Compilation)
汇编(Assembly)
链接(Linking)
下面以最简单的一段C语言程序为例,使用GCC编译过程如下:
#include
int main()
{
printf("Hello World\n");
return 0;
}

预编译:
源代码文件和相关的头文件被预编译器cpp预编译成一个.i文件。
相当于如下命令:
$gcc -E hello,c -o hello.i或者$cpp hello.c > hello.i
预编译过程主要处理那些源代码文件中以”#”开始的预编译指令。如”#include”、”#define”等,处理规则如下:
将所有的"#define"删除,并且展开所有的宏定义
处理所有条件预编译指令,比如"#if"、"#ifdef"、"#elif"、"#else"、"#endif"
处理"#include"预编译指令,将被包含的文件插入到该预处理指令位置。这是一个递归过程,也就是说被包含的文件可能还包含其他文件。
删除所有的注释
添加行号和文件名标识,以便编译时编译器产生调试用的行号信息及用于编译时产生编译错误或警告时能够显示行号
保留所有的#pragma编译器指令,因为编译器需要使用它们
编译:
编译过程就是把预处理完的文件进行一系列词法分析、语法分析、语义分析及优化后生产相应的汇编代码文件,这个过程往往是我们所说的整个程序构建的核心部分,也是复杂的部分之一。
相当于如下命令:
$gcc -S hello.i -o hello.s
预编译和编译两个步骤也可以合并成一个步骤:
$gcc -S hello.c -o hello.s
实际上gcc这个命令只是后台程序的包装,它会根据不同的参数要求去调用预编译编译程序cc1(c++是cc1plus、Objective-C是cclobj)、汇编器as、链接器ld。
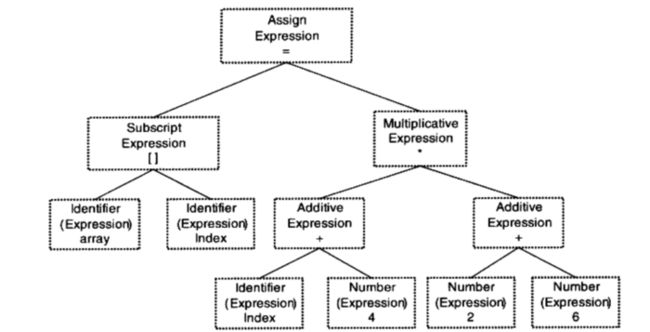
以下面这段代码来分析一下编译器所做的事:
array[index] = (index + 4) * (2 + 6)
词法分析:
词法分析很简单,程序被输入到扫描器,扫描器运用一种类似于有限状态机的算法将源代码的字符序号分割成一系列的记号。
语法分析:
语法分析器对扫描器产生的记号进行语法分析,从而产生语法树。上面这段代码会生成如下的语法树:
语义分析
语法分析仅仅是完成了对表达式的语法层面的分析,但它并不了解这个语句是否真的有意义。比如两个指针做乘法等,语义分析器所能分析的语义是静态语义,静态语义是指在编译期可以确定的语义。静态语义通常包含申明和类型的匹配,类型的转换。上面的例子经过语义分析后会变成以下形式:

可以看到每个表达式都被标识了类型。
中间语言生成
中间语言生成主要就是源码级优化器对源代码进行优化,如上面的例子中,(2 + 6)这个表达式可以被优化成8,由于直接在语法树上作优化比较困难,所以源代码优化器往往将整个语法树转换成中间代码。

目标代码生成与优化
源代码级优化器产生中间代码后的过程都属于编译器后端。编译器后端包括代码生成器和目标代码优化器。代码生成器将中间代码转换成目标机器代码,目标代码优化器对目标代码进行优化,比如选择合适的寻址方式、使用位移来代替乘法运算、删除多余的指令等。
汇编:
汇编是将汇编代码转变成机器可以执行的指令,每一个汇编语句几乎都对应一条机器指令。所以汇编器的汇编过程相对于编译器来讲比较简单,它没有复杂的语法,也没有语义,也不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译就可以了。
$as hello.s -o hello.o或者$gcc -c hello.s -o hello.o
也可以使用gcc命令从C源代码文件开始,经过预编译、编译和汇编直接输出目标文件(Object File):
$gcc -c hello.c -o hello.o
链接:
由于我们一个程序通常包含很多个模块,这些模块之间相互依赖又相互独立,所以我们一般写程序的时候对程序进行了分割,链接就相当于把这些分割的模块拼接在一起,最终生成一个可执行文件。
链接通常是一个让人比较费解的过程,链接包括静态链接和动态链接。
静态链接
最基本的静态链接过程如图所示。每个模块的源代码文件经过编译器编译成目标文件(一般扩展名为.o或者.obj),目标文件和库一起链接形成最终可执行的文件。最常见的库就是运行时库(Runtime Library),它是支持程序运行的基本函数的集合。链接的过程包括符号解析、地址重定位等。

动态链接
静态链接使得不同的程序开发者和部门能够相对独立的开发和测试自己的程序模块,大大促进了程序的开发效率,但是随着程序的增大,很多缺点也暴露了出来,比如浪费内存和磁盘空间、模块更新困难等,由此动态链接的产生就是为了解决这些问题。
为什么说静态链接会造成内存浪费?
举个例子,一个程序内部除了都保留着printf()、scanf()、strlen()等这样的公用函数,还有相当数量的其它库函数以及它们所需要的辅助数据结构,如果我们操作系统运行了很多个程序,而这些程序基本都会使用到C语言的静态库,一般这些常用的静态库至少占1MB以上,如果我们运行了100个这样的程序,那每个程序都会保存一个副本在内存中进行静态链接,那就要浪费100MB内存空间。
模块更新的困难?
同样举个例子。如果一个程序Program1所使用的Lib.o是由一个第三方厂商提供的,当该厂商更新了Lib.o的时候,那个Program1的厂商就需要拿到最新版的Lib.o,然后将其与Program1链接后,将新的Program1整个发布给用户。这样做的缺点就是一旦程序中有任何模块更新,整个程序就要重新链接、发布给用户。这样一旦程序任何位置的一个小改动,都会导致整个程序重新下载。
动态链接就不需要把程序的所有模块的目标文件全都链接在一起后再生成可执行文件了,它是要等到程序运行时才进行链接。也就是说,动态链接就是把链接的过程推迟到了程序运行时再进行。
还是举个例子吧。假如Program1和Program2都用到了库Lib.o,当系统加载Program1程序的时候,系统就会加载Lib.o以及Program1依赖的所有目标文件,Program1依赖的所有文件也都加载到了内存中后,它就会进行链接(和动态链接类似)。然后系统就把控制权交给Program1.o的程序入口,程序就开始运行,=。这个时候,如果再运行Program2,系统就不需要重新加载Lib.o了,而是直接链接。
番外
xcode的编译器经历了三个阶段的发展:
GCC
GCC(GNU Compiler Collection,GNU编译器套装),是一套由 GNU 开发的编程语言编译器,它十分的庞大,可以处理C、C++、Fortran、Pascal、Objective-C、Java, 以及 Ada与其他语言。
LLVM
LLVM是使用GCC作为前端来对用户程序进行语义分析产生IF(Intermidiate Format),然后LLVM使用分析结果完成代码优化和生成。
LLVM compliler(clang)
Clang只支持C,C++和Objective-C三种C家族语言,而前段也由GCC完全替换成了Clang,相对来说效率更高,内存占用也更小。
下面这张图将显示GCC、LLVM-GCC、LLVM Compiler这三个编译选项的不同点:

大家可以进群学习交流,一起分享更多的面试题和精彩的demo QQ:2673218363 QQ群:725611317