先概括一下索引的策略:
1)单列索引
2)前缀索引
3)多列索引
4)选择合适索引顺序
5)聚簇索引
6)覆盖索引
7)索引扫描进行排序
8)压缩索引
9)冗余和重复索引
11)索引和锁
一、单列索引
索引列必须独立,即不能是表达式或函数的一部分
无法正却使用索引:select actor_id from actor where actor_id+1=5;
select ... where TO_DAYS(CURRENT_DATE) - TO_DAYS(date_col)<=10;
二、前缀索引
索引的列很长,导致索引大且慢,只索引列开始的部分(某一列的前面几个字符),节省空间也加快速度,但降低索引的选择性(查出结果变多)。
alter tabel XXX add key (col(7)) 前7位索引
通过left前几位计算相应长度的选择性,越大越好
缺点:mysql无法使用前缀索引做GROUP BY和ORDER BY,也无法使用前缀索引做覆盖扫描。
六、覆盖索引
索引包含(或说覆盖)所有需要查询的字段的值,为覆盖索引。
只需扫描索引就能在索引的叶子节点中获得所有的数据,不需回表查询,提高性能。好处:
(1)减少数据访问量(索引条目通常小于数据行的大小),缓存的负载重要。
(2)IO密集型的范围查找会比随机从磁盘中读取每一行数据的IO要少得多、因为索引是按照列值顺序存储
例1:索引覆盖的查询时,在EXPLAIN的Extra列可以看到Usingi ndex的信息。

例2:索引无法覆盖该查询,有两个原因:
(1)查询所有的列,没有任何索引覆盖了所有的列。
(2)MySQL不能在索引中执行LIKE操作。

例3:解决办法:延迟关联

例4:InnoDB的二级索引的叶子节点:包含了主键的值,可有效地利用这些“额外“主键来覆盖查询。
sakila.actor使用InnoDB存储引擎,并在last_name字段有二级索引,索引不包含主键actor_id,也能覆盖查询:

七、索引扫描进行排序
EXPLAIN出来的type列的值为“index“,则说明MySQL使用索引扫描来做排序(不要和Extra列的“Using index”搞混淆了)
(1)索引列顺序与order by子句顺序完全一致:顺/逆序,满足最左前缀要求
(2)关联多张表,order by字段必须是第一张表
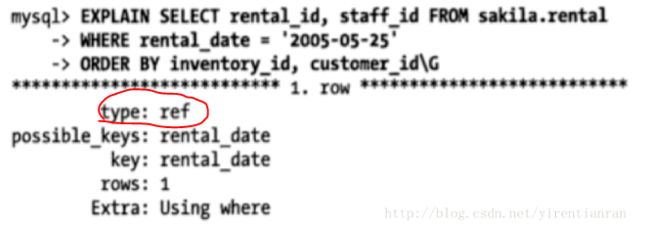
改进:WHERE rental_date = ‘2005-05-25’ ORDER BY inventory_id DESC; 使用第二列进行排序,将两列组合在一起
WHERE rental_date > ‘2005-05-25’ ORDER BY rental_date, inventory_id;
错误:
排序不同:WHERE rental_date = ‘2005-05-25’ ORDER BY inventory_id DESC , customer_id ASC;
引用不在索引中的列:WHERE rental_date = ‘2005-05-25’ ORDER BY inventory_id , staff_id;
无法组合成索引的最左前缀: WHERE rental_date = ‘2005-05-25’ ORDER BY customer_id;
范围条件,无法使用索引的其余列:WHERE rental_date = ‘2005-05-25’ ORDER BY inventory_id , customer_id;
WHERE rental_date = ‘2005-05-25’ AND inventory_id IN(1,2) ORDER BY customer_id;
关联的第二张表:

八、压缩索引
虽然节省空间,但遍历花很多时间
方法:完全保存第一个值,其他值和第一个值进行比较得不同后缀部分,例:第一个“perform“,第二个”performance“,”7,ance“这样的形式。
无法二分查找,只能从头开始。正序扫描速度还不错,倒序ORDER BY DESC不好
适用:I/O密集型应用;对于CPU密集型更慢(压缩索引需要在CPU内存资源与磁盘之间做权衡)
CREATE TABLE语句中指定PACK_KEYS参数来控制索引压缩的方式。
九、冗余和重复索引
相同列上创建多个索引,影响性能。三个重复的索引:
CREATE TABLE test(
ID INT NOT NULL PRIMARY KEY, //主键限制
A INT NOT NULL,
B INT NOT NULL,
UNIQUE(ID), //唯一限制
INDEX(ID) //索引
) ENGINE=InnoDB;
1.冗余索引:(1)索引(A,B),再创建索引(A)就是,
(2)(A,ID),ID是主键,因为InnoDB来说主键列已经包含在二级索引中了
2.不是冗余索引:创建索引(B,A),索引(B)也不是,不是索引(A,B)的最左前缀。或不同类型的索引
3.例:userinfo表。1000000行,每个state_id值大概有20000条记录。state_id列有一个索引对下面的查询有用:
Q1:SELECT count(*) FROM userinfo WHERE state_Id=5; 115次(QPS)
Q2:SELECT state_id,city,address FROM userinfo WHERE state_id=5; QPS小于10
扩展索引为(state_id,city,address),覆盖查询:
ALTER TABLE userinfo DROP KEY state_id, ADD KEY state_id_2(state_id,city,address);
Q2得更快了,Q1却变慢了
4.大多数情况下不需要冗余索引,删除掉,尽量扩展不是创建新索引,增加新索引将会导致INSERT、UPDATE、DELETE等操作的速度变慢
十一、索引和锁
锁定超过需要的行会增加锁争用并减少并发性。
InnoDB只访问行才加锁

获取了1~4之间的行的排他锁。InnoDB锁住第1行

EXPLAIN的Extra列出现了”Using where“,表示MySQL服务器将存储引擎返回行以后再应用WHERE过滤条件。

这个查询挂起,直到释放第1行的锁。
InnoDB、索引和锁有一些很少有人知道的细节:InnoDB在二级索引上使用共享(读)锁,但访问主键索引需要排他(写)锁。消除了使用覆盖索引的可能性,使SELECT FOR UPDATE比LOCK IN SHARE MODE或非锁定查询要慢得多。