(一)、查看ceph的守护进程
$:systemctl list-unit-files | grep ceph
[email protected] static
[email protected] disabled
[email protected] disabled
[email protected] disabled
[email protected] disabled
[email protected] disabled
ceph_exporter.service static
ceph-mds.target enabled
ceph-mgr.target enabled
ceph-mon.target enabled
ceph-osd.target enabled
ceph-radosgw.target enabled
ceph.target enabled
(二)、按照类型在ceph节点上启动特定类型的所有守护进程
$:systemctl start/restart/stop ceph-osd.target
$:systemctl start/restart/stop ceph-mon.target
$:systemctl start/restart/stop ceph-mds.target
(三)、停止ceph节点上所有守护进程,不区分类型
$:systemctl stop ceph \*.service ceph\*.target (不建议执行)
(四)、按照类型停⽌节点上特定类型的所有守护进程
$:systemctl stop ceph-mon \*.service ceph-mon.target (不建议)
(五)、ceph 节点上启动特定的守护进程实例
systemctl start/status/restart/stop ceph-osd@{id}
systemctl start/status/restart/stop ceph-mon@{hostname}
systemctl start/status/restart/stop ceph-msd@{hostname}
(六)、mon 监控状态检查
$:ceph -s
$:ceph
ceph> health
HEALTH_ERR 64 pgs are stuck inactive for more than 300 seconds; 64 pgs degraded; 64 pgs stuck degraded; 64 pgs stuck inactive; 64 pgs stuck unclean; 64 pgs stuck undersized; 64 pgs undersized; mon.x86-131 low disk space
ceph> status
cluster 98593daf-5c1f-4bbe-aa74-da45291f8915
health HEALTH_ERR
64 pgs are stuck inactive for more than 300 seconds
64 pgs degraded
64 pgs stuck degraded
64 pgs stuck inactive
64 pgs stuck unclean
64 pgs stuck undersized
64 pgs undersized
mon.x86-131 low disk space
monmap e2: 1 mons at {x86-131=10.2.151.131:6789/0}
election epoch 4, quorum 0 x86-131
mgr no daemons active
osdmap e5: 1 osds: 1 up, 1 in
flags sortbitwise,require_jewel_osds,require_kraken_osds
pgmap v8: 64 pgs, 1 pools, 0 bytes data, 0 objects
34008 kB used, 367 GB / 367 GB avail
64 undersized+degraded+peered
ceph> mon_status
{"name":"x86-131","rank":0,"state":"leader","election_epoch":4,"quorum":[0],"features":{"required_con":"9025616074522624","required_mon":["kraken"],"quorum_con":"1152921504336314367","quorum_mon":["kraken"]},"outside_quorum":[],"extra_probe_peers":[],"sync_provider":[],"monmap":{"epoch":2,"fsid":"98593daf-5c1f-4bbe-aa74-da45291f8915","modified":"2018-11-24 15:40:34.379153","created":"2018-11-24 15:40:33.765968","features":{"persistent":["kraken"],"optional":[]},"mons":[{"rank":0,"name":"x86-131","addr":"10.2.151.131:6789\/0","public_addr":"10.2.151.131:6789\/0"}]}}
ceph> exit
$: ceph status
(七)、ceph 日志记录
ceph 日志默认的位置保存在节点/var/log/ceph/ceph.log 里面
可以使用 ceph -w 查看实时的日志记录情况
$:ceph -w
ceph mon 也在不断的对自⼰状态进⾏各种检查,检查失败的时候会将自己的信息写到集群日志中去
$: ceph mon stat
检查 osd
$:ceph osd stat
$: ceph osd tree
检查 pool 的大小以及可用状态
$: ceph df
(八)、ceph用户管理
在ceph启用身份验证的时候,必须指定用户名以及密码或者是秘钥环如openstack 使用
ceph做后端存储
1、列出系统默认存在的用户
$: ceph auth list
权限解释
class-read 给用户能够调用类的读⽅法
class-write 给用户能够调用类 写的⽅法
*.all 给用户特定的pool读写的权限 ,以及执⾏管理命令的权限
profile osd (monitor only)
授予用户作为 OSD 连接到其他 OSD 或监视集群状态的权限,授予 OSD 能够处理复
制⼼跳流量和状态报告
profile mds (Monitor only)
给予用户连接mds 的权限
profile bootstrap-osd (Monitor only)
给与用户引导启动 osd 权限,列如批量管理⼯具,如 ceph-volume, ceph-deploy
profile rbd-read-only (OSD only)
给予用户对 rdb 镜像只有读的权限
profile bootstrap-mds (Monitor only)
给予用户只有引导启动⼀个元数据服务的权限
2、获取一个用户的权限信息以及 key
$: ceph auth get client.admin
$: ceph auth export client.admin
3、添加一个用户的方法
ceph auth add //创建用户,并且生成秘钥,可以添加相关的权限
$:ceph auth get-or-create client.li mon 'allow r' osd 'allow rw pool=disk'
参数解释:
ceph auth get-or-create 创建用户,并且返回一个秘钥文件格式,包括用户和密码如果用户已经存在,则仅仅返回秘钥文件格式的用户名和密码。同时也可可以添加一个 -o 可
以将输出保存到特定的文件里面去。
$ceph auth get-or-create client.xxxx mon 'allow r' osd 'allow rw pool=test ' -o test.keyring
ceph auth get-or-create-key client.ringo mon 'allow r' osd 'allow rw pool=test' -o ringo.key //对于需要秘钥的客户端特别适用,如果用户存在,则此命令只返回秘钥。
将创建的秘钥传送到其他的节点上去,可以按照自⼰的需求进行传递
ceph auth get-or-create client.cinder |ssh xxx (主机)tee /ect/ceph/ceph.client.keyring
这个命令是将创建的 cinder 用户的秘钥传送到特定的主机上。
然后在传送的主机的上 修改秘钥的属组属主
4、修改用户的权限
ceph auth caps client.tom 'allow rw ' mon
移除一个用户的权限
ceph auth caps client.tom mon ' ' osd ' '
移除用户权限
ceph auth caps client.li mon ' ' osd ' '
删除一个 ceph 用户
ceph auth del tom
查看一个用户的 key
ceph auth print-key client.t
5、ceph pool 管理
pool 是由逻辑组组成,用来存储数据,池用来管理组的数量,副本的梳理以及池的crush ,如果要使用池来管理数据,需要提供身份信息用于验证是否有权限使用池。
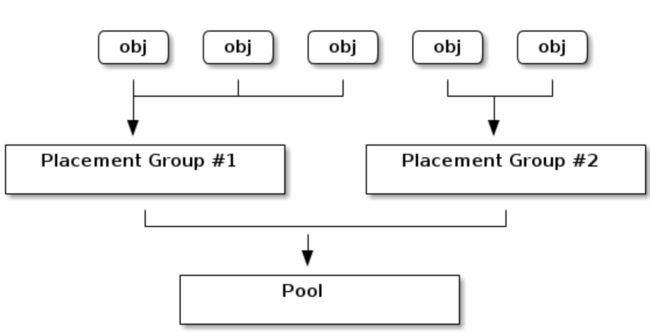
Placement Groups
当 ceph 集群接收到数据存储请求时,它本分散到各个 PG 中,根据 ceph 复制级
别,每个 pg 的数据会被复制并分发到 ceph 集群的多个 osd ,可以将 PG 看作一个逻
辑容器,这个容器里包含多个对象,这个逻辑容器将被映射到多个 osd 上面去。
从右到左 pool-pg-osd-disk
创建 pool 如何设置 pg?
建议:少于 5 个 osds 128
5-10 osds 512
10-50 osds 1024
设置 pool 里面的 pg 个数
ceph osd pool set {pool-name} pg_num {pg_num}
$: ceph osd pool set vms pg_num 256
查看 pool 的 pg 个数
ceph osd pool get {pool_name} pg_num
CRUSH maps CRUSH 是允许 Ceph 在没有性能瓶颈的情况下扩展的重要组成部分,不
受可扩展性的限制,并且没有单点故障。CRUSH 映射将群集的物理拓扑结构提供给
CRUSH 算法,以确定应存储对象及其副本的数据的位置
查看集群中 pool
ceph osd pool ls
ceph --help 查看帮助手册
创建 pool 参数讲解
pool-name 创建池的名字
pg-num 一个池下面有多少个 PG 默认 8 个 不适用
pgp-num 这个默认也是 8 个 ⼀般和 pg-num 保持⼀致
replicated |erasure 创建池的类型,有个是复制,另⼀个是擦除池。
ceph osd crush rule list 池的类型
crush-rule-name 池的 crush 的名字
设置 pool 配额
可以设置每一个池最大的存储字节,同时你也可以设置最大的 objects
ceph osd pool set-quota data (poolname) max_obejcts 200
ceph osd pool set-quota test max_bytes 1000000
查看某一个 pool 配额
ceph osd pool set-quota vm
删除一个池的操作
cph osd pool delete vm vm --yes-i-really-really-mean-it
修改 pool
ceph osd pool rename dddd bb
查看一个 pool 状态
rados df
pool 创建一个快照
ceph osd pool mksnap test test-snap
删除一个 pool 快照
ceph osd pool rmsnap test -test-snap
获取一个 pool 的相关信息
ceph osd pool get {xxxx} {key}
{key}=pg_num,size min_size
设置一个 pool 的副本数量
ceph osd pool set test size 2 个副本
ceph osd pool get test size 获取 test pool 的副本数量