译者: 刘超(君临天下) 审校:梁君(君儿)
介绍
本周,我们收到了一篇来自Sebastian Aaltonen的客座文章,他是Second Order有限公司的联合创始人并且曾经作为Ubisoft公司的高级渲染工程师。Second Order最近宣布了它们的第一个游戏Claybook!该游戏看起来非常的棒,它的渲染器十分有新意,使用GPU用非传统的方法达到该效果。请看Claybook。
Sebastian将会解决他在开发Claybook时遇到的一些有趣的问题:你如何在使用大线程组的情况下优化GPU占用率和考虑着色器的资源使用问题。
大线程组下的GPU占用率和资源使用优化
当使用一个计算着色器时,考虑线程组的大小对性能的影响是非常重要的。有限的寄存器空间,存储延迟和SIMD占用率,每一个都以不同的方式影响着色器的性能。本文将会讨论潜在的性能问题,以及如何正确的使用相关技术和优化来显著的提高着色性能。本文将集中关注大线程组的问题,但是这些提示和技巧对于一般的问题也是有所帮助的。
背景
DirectX®11渲染引擎5的计算着色器规范(2009)要求每一个线程组允许的最大内存大小是32KB,并且最大的线程组包含1024个线程。对于最大的寄存器计数并没有指定,如果寄存器存在一定的压力需求,编译器将会从寄存器溢出到内存中。然而,由于存储延迟,溢出将会对性能产生显著的负面影响,这些问题应该在代码中被避免。
AMD GPU允许在单个计算单元(CU)上同时执行两组包含1024个线程的线程组。然而,为了占有率最大化,着色器必须最小化寄存器和LDS的使用,以便所有线程的资源请求在计算单元上是合适的。
AMD GCN计算单元(CU)
以下是一个GCN计算单元的架构:
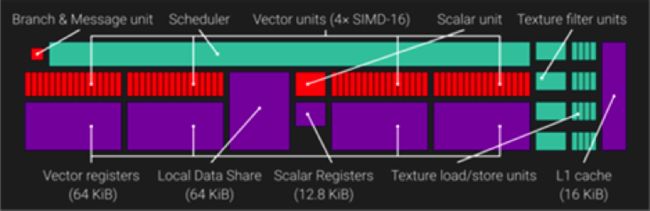
一个GCN计算单元(CU)包含四个SIMDs(单指令流多数据流),每一个包含一个包含32位的VGPRs(矢量通用寄存器)的64KB寄存器文件,对于每一个计算单元(CU)总共拥有65536个VGPRs。每一个计算单元(CU)同时还包含一个32位的SGPRs(标量通用寄存器)寄存器文件。直到GCN3,每一个计算单元(CU)包含512个SGPRs,从GCN3开始,该数字激增到800。每一个计算单元(CU)能够包含3200个SGPRs,或者12.5KB的寄存器文件。
用于计算单元运行的预定任务的最小单元称之为wave,每一个wave包含64个线程。计算单元上的四个SIMDs的每一个可以最大调度10个并发wave。在等待完成内存操作时,计算单元可能会挂起一个wave,来执行另外一个wave。这会有助于隐藏延迟,以及最大限度的利用计算单元的计算资源。
SIMD的VGPR的文件大小引入了一个重要的限制:SIMD的VGPRs被均匀的分配到了已经激活的wave的线程中。如果一个着色器需要用到比实际更多的VGPRs,SIMD将不会执行最优的wave数量。占有率(occupancy):GPU在给定时间能够执行并行工作的数目,其结果会受到影响。
每一个GCN计算单元具有64KB本地数据共享(LDS)。LDS用来存储计算着色器的线程组的共享数据。Direct3D限制了单个线程组的共享数据数量为32KB。因此,为了充分的利用LDS,我们需要在每个计算单元上至少运行两个线程组。
大线程组资源目标
本文使用的着色器的例子是一个线程组大小为1024KB的复杂GPGPU物理解算器。该着色器使用最大线程组和最大规模的线程组共享内存。得益于大规模的线程组,因为它解决了在多个处理过程中使用共享内存作为临时存储空间的物理约束问题。越大的线程组尺寸意味着可以处理更大的数据,而不再需要将临时结果写入到全局内存中。
现在,让我们讨论一下有效的运行1024KB线程组时必须面对的资源目标:
寄存器:为了使GPU饱和,每一个计算单元必须被分配到两个大小为1024KB的线程组。对于整个计算单元提供的65536个可用的的VGPRs,每一个线程在任意时刻能够最多请求32个VGPRs。
组间共享内存:GCN拥有大小为64KB的LDS。我们能够使用全部的32KB组间共享内存,来适应每个计算单元的两个线程组。
如果着色器超出了这些限制,在计算单元上将没有足够的资源来同时运行两个线程组。32个VGPR的目标是很难达到的。我们将首先讨论如果你无法达到这个目标将面临的问题,然后,共同探讨解决该问题的办法以及如何去避免这个问题。
问题:每一个计算单元采用单线程组
考虑以下情况,一个应用程序使用最大为1024KB的线程组,但是着色器需要40个VGPRs。在这种情况下,每一个计算单元同时只能执行一个线程组。如果运行两个线程组,或者是2048个线程,将会需要81920个VGPRs,远远超过目前在计算单元上的可使用的65536个VGPRs。
1024个线程将会产生16个包含64个线程的waves,这些waves被均匀的分配给SIMDs,每一个SIMD包含4个waves。我们之前了解到,最佳的占用率和延迟隐藏需要10个waves,因此,4个waves只有40%的占有率。这显著的降低了GPU的潜在的延迟隐藏能力,从而降低了SIMD的利用率。
假设你使用的1024KB的线程使用最大为32KB的LDS。当仅有一个线程组运行时,50%的LDS没有被利用,它被留给第二个线程组使用,由于寄存器的压力该线程组并不存在。对于总共40960个VGPRs,或者160KB,每一个线程只有40个VGPRs被寄存器文件使用。因此,每一个计算单元上有96KB(37.5%)的寄存器文件被浪费。
如你所见,由于我们超出了VGPR的使用范围,如果每个计算单元仅有一个合适的线程组,使用最大线程组会轻易的导致GPU资源利用率的下降。
当评估潜在的线程组的大小配置时,考虑GPU的资源生命周期是非常重要的。
GPU同时为一个线程组分配和释放所有的资源。寄存器,LDS,wave必须在线程组执行之前被分配好,并且当线程组的最后一个wave执行结束时,所有的线程组资源将被释放。因此,如果计算单元上仅有一个合适的线程组,由于每一个线程组必须等待之前的线程组结束之后才能启动,导致分配和释放之间不会发生重叠现象。由于内存延迟是无法预测的,因此线程组中的waves将会在不同的时间内结束。由于在下一个线程组中的waves在上一个线程组中的所有waves没有完成之前无法启动,因此导致占用率下降。
大的线程组倾向于使用大量的LDS。LDS的访问与壁垒(barriers)是同步的(GroupMemoryBarrierWithGroupSync,HLSL中的link)。直到同一个线程组里的所有的waves完成之前,每一个壁垒会阻止其它程序继续执行。理想情况下,计算单元在等待壁垒时,能够执行别的线程组。
不幸的是,在我们的示例中,我们只有一个线程组在运行。当在计算单元上只有一个线程组运行时,壁垒将所有的waves限制在同一个着色器指令集上。该指令集在两个壁垒之间常常是单调的,因此在线程组里的所有的waves将会倾向于同时加载内存。因为壁垒阻碍了后续着色器独立部分的进行,因此没有机会使用计算单来进行有效的能够隐藏存储延迟的ALU工作。
解决方案:每个计算单元使用两个线程组
如果每一个计算单元拥有2个线程组,将会显著的减少这些问题。所有的线程组趋向于在不同的时间完成任务,在不同的时间遇到不同的障碍,改善指令集并降低占用率下降的问题。SIMDs会被更好的利用,将会为延迟隐藏提供更多的机会。
我最近优化了一个1024线程组的着色器。最开始它使用48个VGPRs,因此只有一个线程组运行在每个计算单元上。将VGPR使用率降低至32个,不需要别的任何优化,平台性能提升了50%。
每个计算单元使用两个线程组是最大化线程组个数的最佳情况。然而,及时使用两个线程组,占有率的波动也无法彻底消除。在选择大型线程组之前,分析其优势和劣势十分重要。
大线程组应该何时使用
解决该问题最简单的方法是完全避免该问题的出现。我提到的许多问题可以通过使用小的线程来解决。如果你的着色器不需要LDS,则根本不需要使用大的线程组。
当不需要LDS时,你应当选择大小在64-256个线程之间的线程组。AMD推荐大小为256的线程组作为默认选择,因为其最适合分布算法。单个wave,64个线程,线程组同样有他们的作用:GPU能够在wave结束之后尽快的释放资源,当所有的wave确保在锁定状态进行时,AMDs的着色器编译器将会释放所有的内存壁垒。具有高波动的工作负载,从单个wave工作线程组中收获很多,例如渲染我们的游戏Claybook时用到的球面跟踪算法。
然而,LDS是其它着色阶段所缺失的,但是在计算着色器中引人注目的、非常有用的一个特性。当正确的使用时,它能够更大的提升性能。将公共数据一次加载到LDS中——而不是每一个线程执行单独的加载——减少了冗余内存的访问。高效的使用LDS能够降低L1高速缓存的失败和废弃,同样对存储延迟和渲染管线的推迟也有帮助。
当线程组的尺寸降低时,1024线程组所遇到的问题也会显著减少。大小为512的线程组会好很多:每一个计算单元最多有5个线程组。但是你仍需要遵守32个VGPR的限制用来达到良好的占有率。
邻域处理
许多通用的后置处理器(例如:抗锯齿、模糊、腐蚀和重建)需要该元素附近的邻域信息。通过使用LDS消除冗余的内存访问将会显著的提高这些滤波器的性能(某些情况可达到30%)。
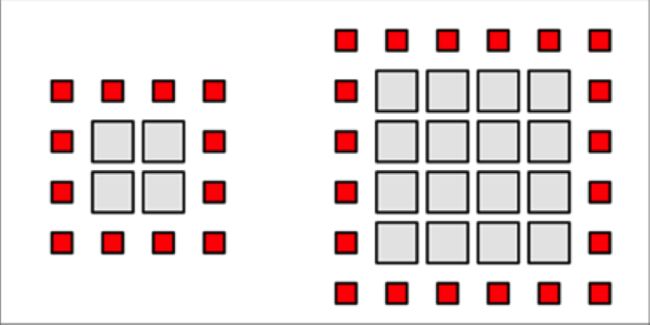
假设我们有一个2D输入,每一个线程负责单独像素的渲染,我们可以看到每一个线程必须检索它的初始值以及相邻的八个像素。而每一个邻域像素也需要检索线程的初始值。此外,每一个邻域线程需要中心值。这导致了许多冗余的加载操作。在一般情况下,每一个像素将会被9个不同的线程访问。如果没有LDS,每一个像素需要被加载9次——每一个线程都需要加载一次。
通过首先将所需要的数据载入LDS,并且后续的内存加载操作全部使用LDS加载来代替,这样可以显著的减少全局设备内存的访问次数以及潜在的缓存超载问题。
当在一个线程组里有大量的共享数据时,LDS是最有效的。越大的邻域导致越大的线程组尺寸,导致存在更多的可被共享的有效数据,会更进一步减少冗余加载。
让我们假设1邻域和一个矩形的2维线程组。线程组应当加载所有的像素到线程组区域内,并在1邻域的边界处满足边界条件。一个长度为X的矩形区域需要X^2个内部像素和4X 4个边界像素。内部有效载荷成二次平方增长,边界像素是只读的,为线性增长。
具有单像素边界的一个8X8的线程组包含64个内部像素和36个边界像素,总共有100个负载。这需要56%的额外开销。
现在考虑一个16X16的线程组。有效载荷包含256个像素,还包含额外的68个边界像素。尽管有效载荷的尺寸是额外载荷的四倍,额外载荷仅68个像素,占了27%。如果将线程组的大小增加一倍,我们能够显著的减少额外开销。在可能的最大的线程组包含1024个线程——一个32X32的矩形区域,对于读取132个边界像素的额外开销仅占负载的13%。
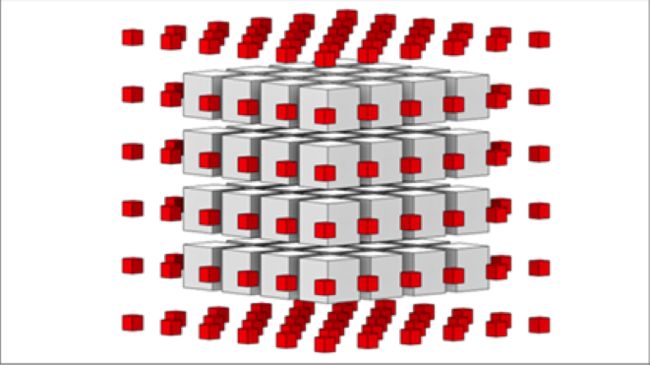
3维线程组效果更好,因为线程组体积的增长要比边界的增长快很多。对于一个小的4X4X4的线程组,有效载荷包含64个元素。一个空的6X6X6的立方体,需要216个元素,额外开销占到了70%。然而,一个8X8X8的线程组包含512个内部像素和488个边界像素,额外开销占到48%。对于小的线程组,邻域的额外开销是巨大的,但是随着线程组尺寸的增加,性能会提高。很明显,大线程组有其用途。
使用LDS的多个处理过程
有许多算法需要多次处理。简单的存储在全局内存中,会显著的消耗内存带宽。
有时候每一个独立的部分,或者是很小的“孤岛”问题,通过将中间结果存储在LDS中,将它分解为多个步骤或多个处理过程。单个计算着色器执行所有的所需要的步骤并将每个步骤的中间值写入到LDS中。仅将结果写入到内存中。
物理求解器是应用该方法的一个很好的应用。向Gauss-Seidel这种迭代技术需要多个步骤来得到满足所有约束条件的稳定结果。该问题能够被分解为多个“孤岛”问题:单个连接体的所有粒子被分配到同一个线程组,并且独立求解。之后的处理过程可能会涉及到内部物体的交互作用,可以采用之前处理过程的中间结果进行计算。
VGPR的使用优化
具有大线程组的着色器变得越来越复杂。达到32个VGPRs的目标是很难的。以下是过去几年我所学到的一些技巧:
标量数据
GCN设备既有用于维持wave中每个线程的不同状态的向量(SIMD)单元,又有包含wave中所有线程的单个状态的标量单元。对于每一个SIMDwave,有一个自身拥有SGPR文件的额外的标量单元在运行。标量寄存器包含一个用于所有wave的单个值。因此,SGPRs有着低于64倍的片上存储消耗。
GCN着色编译器会自动发出标量加载指令。如果在编译时知道加载地址不随着wave发生变化(意思是该wave中的所有的64个线程有着同样的地址,非时移wave),编译器发送一个标量加载的信号,而不是每一个wave独立的加载数据。对于非时移wave最常用的来源是固定缓存和迭代变量。由于标量单元拥有一个完整的整数指令集,因此在所有非时移wave中计算得到的整数结果同样也是非时移的wave。这些标量指令与矢量指令SIMD同步发出,而且在执行方面几乎是不消耗时间的。
计算着色器的内置输入变量,SV_GroupID同样也是非时移wave。这是非常重要的,因为它允许离线加载线程组的指定数据到标量寄存器中,从而降低了线程的VGPR压力。
标量加载指令不支持类型缓存或纹理。如果你想要编译器加载你的数据到SGPR而不是VGPR,你需要将你的数据从ByteAddressBuffer加载至StructuredBuffer。不要使用类型缓存和纹理来存储线程组的通用数据。如果你想要从2维/3维数据结构中执行标量数据的加载,你需要自定义地址计算。幸运的是地址计算与标量单元一样具有完整的整数指令集。
在SGPRs之外运行也是可能的,但是希望渺茫。最常用的方法是通过过多的纹理和采样器来执行超出SGPR的那部分。纹理可支持8个SGPRs,采样器可以支持4个SGPRs。DirectX11允许使用单个采样器和多个纹理。一般的,使用单个采样器就足够了。缓存只支持4个SGPRs。缓存和纹理加载指令不需要采样器,它们应当在不需要滤波器时使用。
示例:每一个线程组通过非时移wave矩阵进行位置变换,例如观察矩阵或投影矩阵。可以使用4个类型加载指令从缓存区加载4X4的矩阵。然后数据被存储在16个VGPRs中。这已经消耗了一半的VGPR。取而代之的时,你应当从ByteAddressBuffer中进行4次加载操作。编译器将生成标量加载,将这些数据存储在SGPRs中而不是VGPRs。这样将没有浪费任何VGPRs。
不需要的数据
在3D图形学中会经常用到齐次坐标系。在大多数情况下,齐次坐标中的W值不是0就是1。在这种情况下,不要加载或者使用W值。它将在每一个线程中浪费一个VGPR并且生成更多的ALU指令。
同样地,如果一个4X4的矩阵需要进行投影操作。所有的仿射变换最多需要一个4X3的矩阵。最后一列是(0,0,0,1)。相对于一个完整的4X4的矩阵,一个4X3的矩阵将会节省4个VGPRs/SGPRs。
按位存储
按位存储对于节省内存是非常有效的方式。VGPRs是非常宝贵的内存资源——他们运算非常快。幸运的是,GCN提供了快速的,单循环的位提取和位插入算法。采用这些操作,你能够将更多的数据高效的存储在一个32位的VGPR中。
例如,2D整数坐标系可以按照16b 16b的方式进行存储。HLSL同样有将2个16位的浮点数存储或者提取到32位的VGPR的指令(f16tof32
& f32tof16)。这些操作在GCN上是全速率的。
如果你的数据已经按位存储在内存中,在使用之前不要提取它,而是通过一个uint寄存器或者LDS直接进行加载。
布尔变量
GCN编译器将布尔变量存储在一个64位的SGPR中。在wave中每一个通道包含1位。没有浪费VGPR。不要采用整数或者浮点数来替代布尔变量,这些优化不会起到任何作用。
如果在SGPRs中有更多的布尔变量要存储,可以考虑采用按位存储将32位的布尔值存储在一个VGPR中。GCN有着单循环位提取和位插入操作,能够快速的进行位操作。此外,你还可以使用countbits()和firstbithigh()/firstbitlow()来进行位缩减和搜索操作。二进制首部求和可以通过countbits()有效的实现,通过对首部位进行掩码操作,然后求和。
布尔值同样可以存储在总是正浮点数的符号位中。abs()和saturate()是GCN上的自由函数。它们作为简单的输入/输出描述符,可以同调用他们的函数一起执行。因此,在符号位中检索布尔变量几乎是不消耗时间的。不要使用HLSL中的sign()函数,这会造成编译器的输出不是最优的。同样可以快速的通过测试一个值是否是非负的来决定该符号位的值。
分支和循环
编译器尝试将数据从加载到使用之间的代码距离最大化,以便可以通过它们之间的指令来实现存储延迟的隐藏。不幸的是,数据在加载和使用之间必须保存在VGPRs中。
可以使用动态循环来降低VGPR的生命周期。依赖循环计数的加载指令无法移动至循环之外。VGPR的生命周期被限制在循环的内部。
使用HLSL中的[loop]属性强制实现循环。不幸的是,[loop]属性并非是完全万无一失的。如果在编译时请求的迭代次数是已知的,着色编译器仍然能够展开该循环。
16位寄存器
GCN3引入了16位寄存器的支持。Vega通过以双倍速率执行16位的数学运算对其进行扩展。整数和浮点数全部支持。2个16位的寄存器将会被存储在一个VGPR中。当不需要完整的32位精度时,这是一个简单的节省VGPR空间的方法。对于2D/3D的地址计算,16位整数是非常适合的(资源加载/存储和LDS数组)。16位浮点数在后置处理中是非常有用的,尤其是当你处理LDR或者进行后置色调数据映射时。
LDS
当在线程组里有多个线程加载同样的数据时,你应当考虑将数据加载至LDS中。这将会大大的降低加载指令的数量以及VGPRs的数量。
当LDS不是立刻需要时,可以将其用作临时寄存器使用。例如:在开始阶段着色器需要加载和使用一段数据,在结束时同样需要使用这个数据。然而,VGPR的峰值出现在着色器的中间。你可以将这些数据临时存储在LDS中,并且稍后当你需要时进行加载。重要的是,这会在峰值期间降低VGPR的使用。
结论
上述是今天的客座文章——非常感谢诸位的阅读并且非常感谢Sebastian的撰写。如果您有任何疑问,可以直接评论或者和作者在Twitter上进行直接联系@SebAaltonen,记得查看Claybook。