上文:关于php的共享内存的使用和研究之由起
下文:
关于php的共享内存的使用和研究之深入剖析swoole table
上文中提到了针对php的共享内存方案的尝试,最终发现它并不适用于我的场景,如果想要兼容多进程或多线程并发读写的情况下可靠,一定要有适当的机制来保证资源的唯一性。
加锁肯定是想到的第一选择,对于每次共享内存的时候,先获取一个锁,只有获取成功了之后才允许进行读和写,这应该是最简单的方案,但是同步锁对性能的损耗也是比较大的。APC的user data cache的存储机制对数据要求严格正确,锁比较多,它的效率与本地的memcache相当。既然这样,不如把眼光投向业界,看看大牛们使用什么样的方案来解决这个问题。
YAC
原文链接:http://www.laruence.com/2013/03/18/2846.html
laurance为了解决如下的两个问题,设计出了这个cache:
- 想让PHP进程之间共享一些简单的数据
- 希望非常高效的缓存一些页面
同时也是基于如下的经验假设:
- 对于一个应用来说, 同名的Cache键, 对应的Value, 大小几乎相当.
- 不同的键名的个数是有限的.
- Cache的读的次数, 远远大于写的次数.
- Cache不是数据库, 即使Cache失效也不会带来致命错误.
实现这个cache,关键是无锁化的设计. 根据laurance的说法,他解决读锁的方式是通过不加锁的读,然后CRC校验。
看了一下他代码的实现,是对key中存储的固定size的值进行了CRC的计算,然后把key中附带存储的crc信息和内容计算出来的crc信息进行校验。如果校验成功了,那么认为查询成功,如果校验失败了,那么认为查询失败。其实本质上这是一种使用CPU来换锁的方式,大部分的服务器是多核的,一旦加锁,对CPU是很大的浪费。下面这张图形象的表明了这一点:
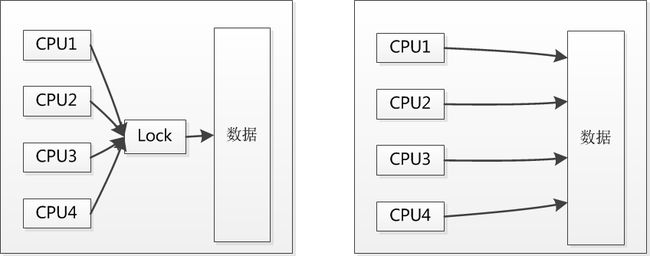
这个是个不错的trick,能够解决的问题就是在多个进程频繁的写入的时候,可能导致的读出错不会带来错误的结果,因为一旦crc校验不通过,那么读出来的结果就是失效了。这显然比上一篇文章中的共享内存的读的方式要高明一些。不过根据我的观察,使用共享内存的方式,由于一直是向后不停的写入,出现被覆盖的概率几乎没有,而laurance这里之所以要校验,则是因为他会进行内存的回收和循环写入,这点在下文中会继续说明。
现在重点说说这个YAC的写入的问题,首先启动的时候key空间大小确定,可以通过配置来调整分配给存储key的大小,从而扩展key的个数。4M基本上相当于32768个Cache值。首先第一个很重要的点就是如何设计哈希方法来避免写入冲突,这里他使用的是双散列法的
MurmurHash.
对于小于4M的内存块的操作由于key不同,根据哈希出来的起始位置也不同。不同key之间冲突的概率,等同于哈希算法冲突的概率,这个还是比较低的。对于大的内存块,这里使用了segment->pos指针来控制内存的分块。和共享内存扩展的实现方式还是比较类似了,反正就是一个pos指针,找得到就update,找不到就向后写。
那么如果发生冲突呢,laurance给出了一个例子:
比如A进程申请了40字节, B进程申请了60字节, 但是Pos只增加了60字节. 这个时候有如下几种情况:
- A写完了数据, 返回成功, 但是B进程又写完了数据返回成功, 最终B进程的Cache种上了, 而A进程的被踢出了.
- B进程写完了数据, 返回成功, A进程又写完了数据返回成功, 最终A进程的Cache种上了, B进程的被踢出.
- A进程写一半, B进程写一半, 然后A进程又写一半, B进程又写一半, 都返回成功, 但最终, 缓存都失效.
可见, 最严重的错误, 就是A和B的缓存都失效, 但是Yac不会把错误数据返回给用户, 当下一次来查询Cache的时候, 因为存在crc校验, 所以都miss.
看到这儿终于明白了,并没有解决多进程写的问题,多进程的写还是可能会有冲突,不仅仅是单key的冲突,不同key之间也可能会有冲突。但是冲突了不怕,会通过校验的方式确保client端能够判断出来自己冲突了,这点对应用程序确实非常重要,因为这不是cache error,而仅仅是cache miss而已,这两种情况的严重程度和处理机制的确完全不同。
另外还有一个亮点是内存的循环分配,如果一个内存块用完了,那么可以重置pos,从而从头开始分配,有了这种机制,即使并发写导致pos一直后移,也不会出现内存耗尽的情况了,这确实是个不错的特性。
总结来看,yac两个不错的特性:
- 读的CRC校验,保证最严重是cache miss
- 写的pos重置,保证内存不被写满
但是针对我的使用场景,多并发情况下的同key的多写多读,它并没有很好的解决这个问题,而是比较适用于低频的用户数据的缓存,比如登陆用户的头像、昵称这类信息。拉取频次不高,miss了也能向后端请求。所以怎么办呢,只能继续进行求索。
ps:laurance在文章开头群嘲了一下APC的性能,相当于本地的memcache,结果文末贴出的性能对比,yac完全比不上apc。。有点莫名
Swoole table
接下来说说这两年在社区里面比较火,最近刚刚发布了内置协程2.0版本的swoole. github地址:https://github.com/swoole/swoole-src
swoole table是swoole中的一个基于共享内存和锁实现的超高性能的并发数据结构,用来解决多进程、多线程数据共享和同步加锁的问题。这不就是我们苦苦寻觅的解决方案么?
先来看一下swoole table的常见的使用方式,首先它支持三种基本的类型:
-
swoole_table::TYPE_INT整形字段 -
swoole_table::TYPE_FLOAT浮点字段 -
swoole_table::TYPE_STRING字符串字段
如果想要在各个进程之间共享高性能的本地数据,那么使用的范例如下:
// 新建swoole table,并且指定类型
$table = new swoole_table(1024);
$table->column('id', swoole_table::TYPE_INT, 4); //1,2,4,8
$table->column('name', swoole_table::TYPE_STRING, 64);
$table->column('num', swoole_table::TYPE_FLOAT);
$table->create();
// 新建swoole的server
$serv = new swoole_server('127.0.0.1', 9501);
//将table保存在serv对象上
$serv->table = $table;
$serv->on('receive', function ($serv, $fd, $from_id, $data) {
// 使用swoole table存储全局的数据
$ret = $serv->table->set($key, array('from_id' => $data, 'fd' => $fd, 'data' => $data));
});
// 这里需要注意的就是一定要在server启动之前创建swoole table,从而保证它能够被全局共享
$serv->start();
如果只是你自己的一个进程在不同的请求之间共享高性能的本地数据,那么使用的范例如下:
class LocalSwooleTable {
private static $_swooleTable;// 静态变量,单个进程内共享
const SWOOLE_TABLE_SET_FAILED = -1001;
const SWOOLE_TABLE_GET_FAILED = -1002;
// swoole table初始化
private function __construct() {
//预估数据量 100个服务,每个长度30 需要3000个字节,这里申请64k
self::$_swooleTable = new \swoole_table(65536);
self::$_swooleTable->column('ip',\swoole_table::TYPE_STRING, 64);
self::$_swooleTable->column('port',\swoole_table::TYPE_INT, 4);
self::$_swooleTable->column('timestamp',\swoole_table::TYPE_INT, 4);
self::$_swooleTable->column('bTcp',\swoole_table::TYPE_INT, 4);
self::$_swooleTable->create();
}
// 获取单个swoole的实例
public static function getInstance() {
if(self::$_swooleTable) {
return self::$_swooleTable;
}
else {
new LocalSwooleTable();
return self::$_swooleTable;
}
}
}
// 获取唯一的实例
$swooleTableIns = LocalSwooleTable::getInstance();
$key = "sample";
$routeInfo['timestamp'] = time();
$routeInfo['ip'] = '10.25.22.33';
$routeInfo['port'] = 1000;
$routeInfo['bTcp'] = 1;
// 设置swoole table中的内容
$flag = $swooleTableIns->set($key,$routeInfo);
// 获取swoole table中的内容
$routeInfo = $swooleTableIns->get($key);
本来,第一种方式应该是我们最好的选择,但是因为我们使用了TSF框架(或者任何不是自己从头裸写swoole的框架),都不会把创建server这一步暴露到业务代码中,这就给我们使用全局的swoole的table带来了很大的难度。换句话说,知道好用,但是就是业务用起来非常的不方便,不具备业务扩展性。
所以无奈之下,我们还是选取了第二种方案,从性能上面来讲的话,确实是有提升的,不好的地方就是存储资源浪费了一些,每个进程都用了专属自己的swoole table,这当然是无奈之举。还是希望能够之后通过一些改造,把全局的swoole table这种能力能够开放出来。
基本上访问一次是0.03ms,这个性能还是比较突出的。