这一部分介绍的是全文搜索引擎,允许我们在大量的文档中搜索一系列的单词,并且根据文档与这些单词的相关程度对我们的结果进行排序。Google能从一个研究型项目变为现在的全世界最受欢迎的搜索引擎,很大程度上归功于它的PageRank算法。在这一部分的重点是学到如何检索网页(crawl),建立索引,对网页进行搜索以及用不同的方式对搜索到的结果进行排序。我们一步一步来完成这一个实验。
我们建立一个Python的模块,取名为searchengine.py,其中包含了两个类,一个用于检索网页和创建数据库;另外一个通过查询数据库进行全文搜索。因为我们只是模拟全文搜索,所以在这个实验当中,我们采用了SQLite数据库,这个数据库的特点就是它是一个嵌入式的数据库,是将整个数据库存入到一个文件当中。SQLite的安装很简单,网上也有相应的教程,这里不赘述了。
Talk is cheap,show me the code.
首先先定义一个crawler这一个类,它的作用是检索网页,创建数据库,以及建立索引。要实现这个类我们要完善以下这些方法和步骤:
1:实现一个简单的爬虫程序:
1.1使用urllib2
urllib2是一个绑定在Python的库,它的作用就是方便网页的下载,我们只需要提供一个URL。
1.2爬虫程序的代码
爬虫程序会用到Beautiful Soup PI,这是一个可以为网页建立结构化表现形式的优秀数据库。对于HTML语法不是很规范的Web页面,它有很好的容错性,这对我们的爬虫软件大有裨益。
利用urllib和Beautiful Soup,我们可以建立一个爬虫程序,接受一个等待建立索引的URL列表,检索网页链接,并且找出其他需要建立索引的网页。
def crawl(self,pages,depth=2):
for i in range(depth):
newpages=set()
for page in pages:#进行广度优先遍历
try:
c=urllib2.urlopen(page)
except:
print "Can not open %s"%page
continue
soup=BeautifulSoup(c.read())
self.addtoindex(page,soup)
links=soup('a')
for link in links:
if('href' in dict(link.attrs)):
url =urljoin(page,link['href'])
if url.find("'") != -1: continue
url = url.split('#')[0]
if url[0:4] == 'http' and not self.isindexed(url):
newpages.add(url)
linkText = self.gettextonly(link)
self.addlinkref(page, url, linkText)
self.dbcommit()
pages = newpages
上面这一个过程,类似于广度优先搜索。网络爬虫使用BFS还是DFS这也是很有讲究的。一般现在主要是使用BFS。
命令行输入:
>>import searchengine
>>pagelist=['http://baike.baidu.com/link?url=ICqPXFlgZGKnOb6hDWv25UesDr1LEpGa0aVgP6tURdYUDV0EyOBrGHdhVZc801mbFFohB18AdEkqZpU04ycn9K']
>> crawler=searchengine.crawler('')
>> crawler.crawl(pagelist)
运行结果:
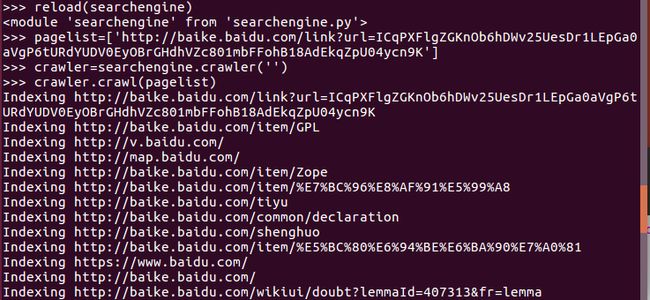 爬虫结果.png
爬虫结果.png
2、建立索引
接下来,我们需要为全文索引建立数据库。索引对应于一个列表,其中包含了所有不同的单词、这些单词所在的文档,以及单词在文档中出现的位置。我们采用了SQLite数据库,这个数据库的特点就是它是一个嵌入式的数据库,是将整个数据库存入到一个文件当中。
修改____init__,del,以及dbcommit方法,以便打开和关闭数据库:
#初始化crawler并传入数据库名字
def __init__(self,dbname):
self.con=sqlite.connect(dbname)
def __del__(self):
self.con.close()
def dbcommit(self):
self.con.commit()
2.1建立数据库Schema
urllist保存的是已经过索引的URL列表,wordlist保存的是单词列表,wordlocation保存的是单词在文档当中的位置列表,link保存两个URLID,指明从一张表格到另一张表格的链接关系
#2:创建数据库表
def createindextables(self):
self.con.execute('create table urllist(url)') self.con.execute('create table wordlist(word)') self.con.execute('create table wordlocation(urlid,wordid,location)')
self.con.execute('create table link(fromid integer,toid integer)')
self.con.execute('create table linkwords(wordid,linkid)')
self.con.execute('create index wordidx on wordlist(word)')#建立这些index的目的是为了加快索引速度
self.con.execute('create index urlidx on urllist(url)')
self.con.execute('create index wordurlidx on wordlocation(wordid)')
self.con.execute('create index urltoidx on link(toid)')
self.con.execute('create index urlfromidx on link(fromid)')
self.dbcommit()
这些函数为用到的表建立schema,并建立一些可以加快检索速度的索引。
3、在网页中查找单词
从网上下载下来的文件都是HTML格式的,其中包含大量的标签,属性,以及不在检索范围的内容,所以我们需要从网页中提取出所有的文字部分。
3.1补充gettextonly函数:
#3:从一个Html网页中提取文字(不带标签的)
def gettextonly(self,soup):
v = soup.string
if v == None:
c = soup.contents
resulttext = ''
for t in c:
subtext = self.gettextonly(t)
resulttext += subtext + '\n'
return resulttext
else:
return v.strip()
3.2接下去是separatewords函数:
这里我们不按照书本,因为书本是用于英文的分词,不大适合中文分词,我们用的是jieba分词这一神器。
#根据任何非空白字符进行分词处理
def separatewords(self,text):
text = text.strip()
content_seg = jieba.cut(text)
return [" ".join(content_seg)]
4.1、加入索引
我们补充一个addtoindex方法,这个方法会得到一个出现在网页中的单词的列表,以下是addtoindex的代码:
#4:加入索引
def addtoindex(self,url,soup):
if self.isindexed(url): return
print 'Indexing ' + url
#获取每个单词
text = self.gettextonly(soup)
words = self.separatewords(text)
# 获取URL的id
urlid = self.getentryid('urllist', 'url', url)
# 将每一个单词和URL关联
for i in range(len(words)):
word = words[i]
if word in ignorewords: continue
wordid = self.getentryid('wordlist', 'word', word)
self.con.execute("insert into wordlocation(urlid,wordid,location) values (%d,%d,%d)" % (urlid, wordid, i))
这里我们还需要更新函数getentryid。这函数的作用是返回某一条目的ID。如果条目不存在,则程序会在数据库中新建一条记录,并且将ID返回:
#4.2该函数的作用是返回某一条条目的ID,如果这一个条目不存在,程序就在数据库创建一条记录,将ID返回
def getentryid(self,table,field,value,createnew=True):
cur = self.con.execute(
"select rowid from %s where %s = '%s'" % (table, field, value))
res = cur.fetchone()
if res == None:
cur = self.con.execute(
"insert into %s (%s) values ('%s')" % (table, field, value))
return cur.lastrowid
else:
return res[0]
最后,我们还需要实现isindexed函数,这个函数的作用是判断网页是否已经存在数据库,如果村咋,则判断是否和任何单词与之关联:
#4.3如果url已经建过索引,返回true
def isindexed(self,url):
u = self.con.execute("select rowid from urllist where url ='%s'"%url).fetchone()
if u !=None:
#检查它是否已经被检索过
v=self.con.execute('select * from wordlocation where urlid=%d'%u[0]).fetchone()
if v!=None:return True
return False
到目前为止,我们再一次执行crawler,程序在运行期间会为网页建立索引。
运行结果报错:
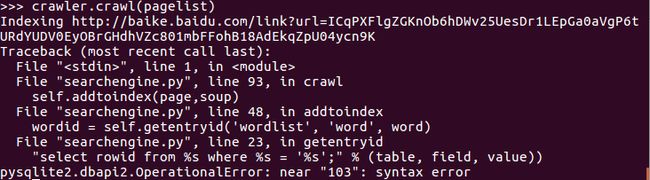 数据库语法错误.png
数据库语法错误.png
我现在被卡在这个问题上了,明天继续解决~
完整代码↓:
Github:https://github.com/GreenGitHuber/Programming-Collective-Intelligence/tree/master/chapter4_Search-Rank