前言
首先,我要承认这是标题党。
这其实是一篇关于python数据挖掘/机器学习的文章,分析的是葡萄牙某银行某次电话营销的数据,数据来自这里。(更多数据请看UCI Machine Learning Repository。)
我本来想玩玩UCI这个数据库里关于Dota2的那个数据,但一来我不熟悉Dota2,且这个数据集包含的特征太少(所以可能不能得到很有趣的insights),二来我的主要目的是想练习用python做数据挖掘,所以还是选择相对更好操作的数据集。对Dota2感兴趣的朋友可以试试:)
这次的分析分为两部分,第一部分包括探索性数据分析(Exploratory Data Analysis,EDA)和简单建模,第二部分重点谈建模。这篇文章为第一部分。
整个分析通过python3实现,涉及的package主要有numpy,pandas,matplotlib,seaborn,sklearn,xgboost。
这次的数据比较简单,分析内容也比较基础,主要目的还是为了熟悉python(当然,也有学到很多新东西),所以请各位轻拍。
最后,全篇内容较多,篇幅较长,不感兴趣的朋友看到这里就可以右上角关闭页面出门玩耍了,感兴趣的朋友欢迎交流。祝大家早安、午安、晚安。
这个数据集长什么样,以及到底要分析啥
因为懒,这部分我就直接复制粘贴了。
Q:这是什么数据?
The data is related to direct marketing campaigns (phone calls) of a Portuguese banking institution.
Q:这个数据集包含了啥?
41188 examples and 20 inputs, ordered by date (from May 2008 to November 2010).
(因为篇幅问题,特征我就不具体列举了,后面的EDA部分会都谈到。)
Q:分析目的是什么?
The classification goal is to predict if the client will subscribe (yes/no) a term deposit (variable y).
即,银行想知道:如果我打电话给你,你会购买我们的定存产品吗?(没错,这是一个二元分类问题。)
EDA
这一部分会通过图表的形式,具体分析每一个变量,包括它们的分布、相互关系等。EDA的目的是:理解数据、处理数据、为建模做准备。
每个变量都会有一个对应的小标题,小标题由其在数据集中的变量名和/或其中文含义构成。
1. 目标变量 y
先来看看目标变量。
目标变量,即要预测的变量:在此次营销活动中,某用户是否订购了银行的定存产品?
y: has the client subscribed a term deposit? (binary)

在这个数据集的41188个记录里,绝大部分的客户没有订购产品(y = no),只有少量客户说了yes(11.27%)。
这是比较符合现实的,毕竟我们大多数人在接到推销电话的时候,第一反应是拒绝的。
需要注意的是,这个目标变量里,yes和no的比例非常不平衡(imbalanced)。这种情况需要考虑两个问题:1. 构建模型时,选择的算法能不能解决非平衡问题; 2. 做模型评估时,选择的metrics能不能相对无偏地评估模型性能。(具体的会在建模篇细谈。)
接下来会具体分析另外的19个特征(Xs)
2. 年龄 age
第一个x特征是年龄。
先来看看在这个营销活动中,这个银行的目标客户都age (numeric)
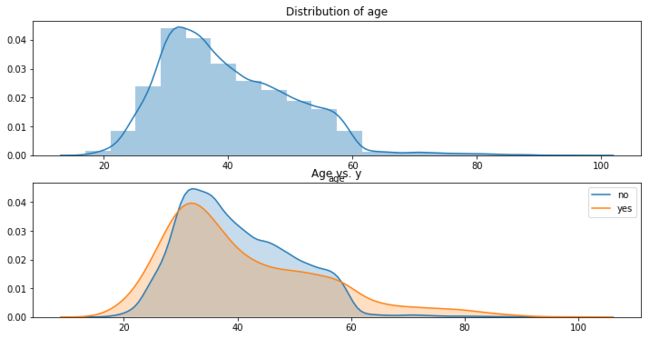
分布在什么年龄段。
从图上可以看到,年龄的分布是正偏态分布,即高峰向左偏移,长尾向右侧延伸。大部分客户处于30到40岁之间(median = 38),另外有少部分客户年龄大于60。
根据 y = yes(橙色)和 y = no(蓝色)的情况分别做密度图,可以看到,年轻客户(小于30岁)和年长客户(大于60岁)相对来说更容易说yes。嗯,果然小朋友和大朋友都比较好哄……
3. 工作 job
接下来看看客户们都在做什么类型的工作。
job: type of job (categorical)

数据集里一共列有12个不同类型的工作(其中一个是unknown项)。
从数量上来看(左图),行政人员、蓝领和技术人员占比最高。从订购产品(y = yes)的角度来看(右图),学生和退休人员的比例最高。和年龄传达出的信息一样:年轻人和老年人最好说话。(传说中的人傻钱多速来(划掉
4. 婚姻状况 marital
marital: marital status (categorical)

在数量方面(左图),大多数客户已婚,单身汪数量也不少,还有少部分客户不愿透露婚姻状况。(我比较好奇的是,非单身又没结婚的人该选哪一项=。=)
右图则说明,单身汪比已婚人士们更容易say yes,一种可能的原因是,单身汪里年轻人比较多,而年轻人就是很好说话啊!(误
需要注意的是虽然统计结果显示unknown人群里 y = yes 的比例相对较高,但这部分人群数量较少(80),不能轻易下结论。
5. 受教育情况 education
education (categorical)
来看看客户们的受教育情况吧。
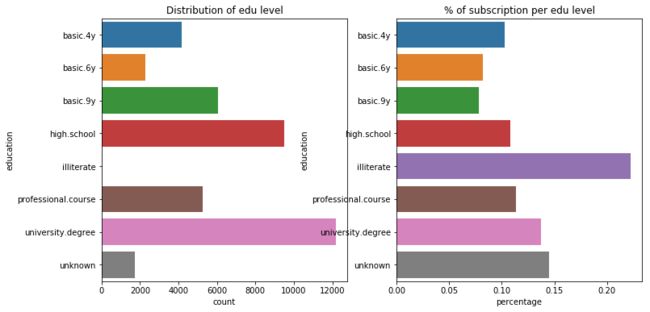
数据集里一共有8类不同的受教育情况(其中一个是unknown项)。
从数量上来说(左图),最高学位为大学学位和高中学位的客户占比较大。从订购产品(y = yes)的角度来看(右图),大学生和unknown群体比例最高。
注意,虽然右图显示文盲群体有很高的订购比例,但这部分群体的数量极少(18),所以不能轻易下结论。
6. 信用违约情况 default
default: has credit in default? (categorical)
咳,因为不确定credit在银行体系里除了"信用”之外还有没有别的含义,所以我根据百度翻译对上面这句话的翻译结果(“有信用违约吗?”)将其理解为“信用违约情况”。 如果我理解错误,还请纠正。
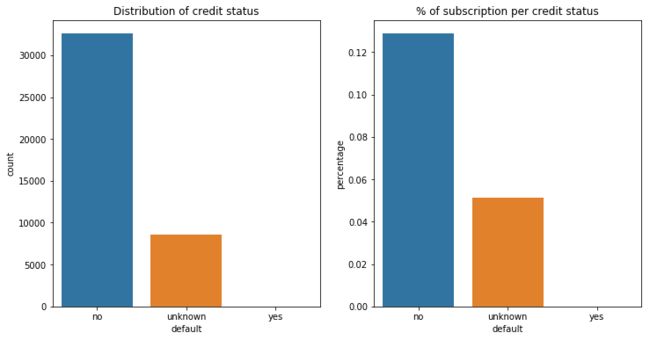
绝大部分客户没有信用违约情况,还有一部分客户的信用违约情况未知,且无信用违约情况的客户中,订购产品的比例相对更高。
7. 房贷情况 housing
housing: has housing loan? (categorical)
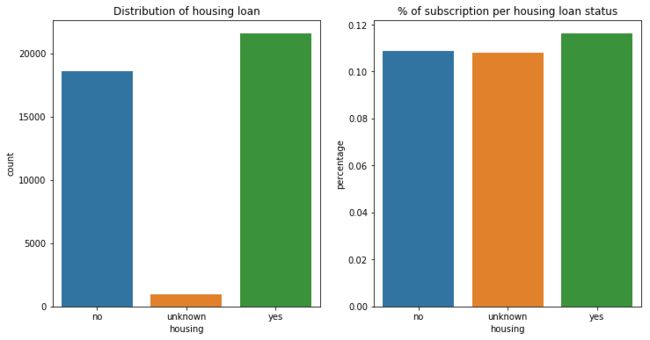
有房贷的客户比例略高于无房贷的客户(左图),果然无论在哪个国家,都少不了贷款买房。
此外,无论是有房贷的客户,还是无房贷的客户,还是情况未知的客户,订购产品的比例(右图)都差不多,前者比例略高于其余二者。
8. 个人贷款情况 loan
loan: has personal loan? (categorical)

绝大部分客户没有个人贷款(左图),嗯,毕竟也不好贷。而订购产品方面,三种类型下的比例都很接近(右图)。
9. 客户联系途径 contact
contact: contact communication type (categorical)
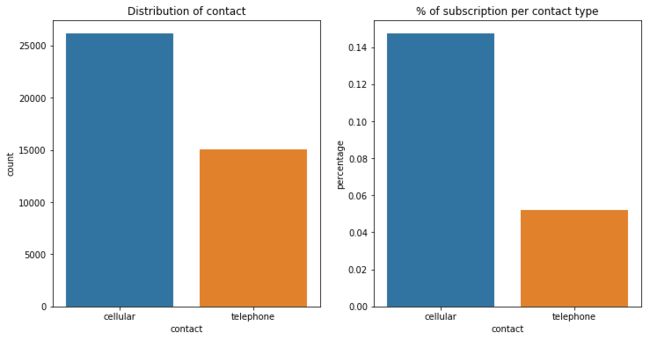
客户联系途径有手机和座机两种,大约三分之二的客户通过手机联系的(左图),且通过手机联系的客户,产品的订购比例要明显高于后者(右图)。
10. 客户联系月份 month
month: last contact month of year (categorical)
银行都是在哪些月份中给客户打的电话呢?
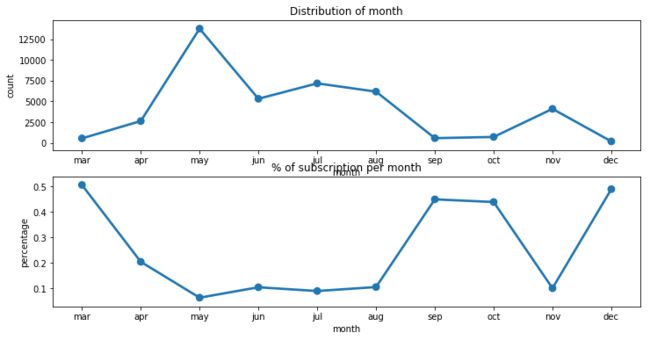
除了一月和二月,其他月份都有在打电话。其中五月的电话数要明显高于其他月份。
一个有趣的现象是,电话数多的月份,产品订购比例小,相反,电话数少的月份,产品订购比例大。我没弄明白这是为什么,我觉得这应该是某种因素的影响,但我没有额外的信息可以探究这个因素到底是什么。
11. day of week
(关于标题,我实在不知道怎么简洁地翻译出来……)
day_of_week: last contact day of the week (categorical)
除去月份,银行是在星期几打电话给客户的呢?

很好,这家银行没有在周末给客户打电话,业界良心。
星期一的电话数不小,而产品订购比例却最低,果然星期一永远很迷。
周五的产品订购比例也相对较小,此外周五连银行打电话的数量都明显减少了,看来周五大家都急迫地想要放飞自我,无心工作。
有时候结合星期和月份来看数据,可以挖掘一些有趣的比列。下图是结合了星期和月份的产品订购率。
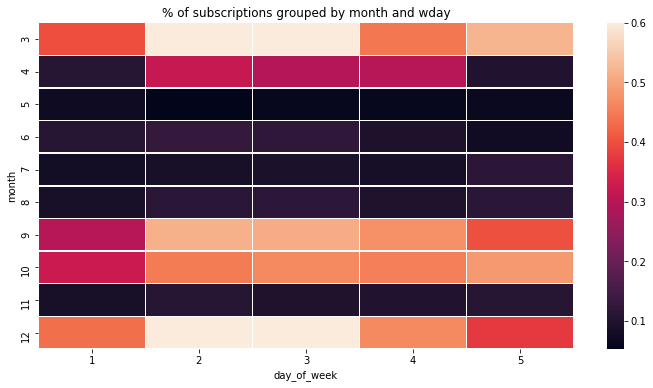
嗯……没有什么特别有趣的规律。
但总的来说,夏天的产品订购率要低于其他季节(除了11月),且周二周三的订购率普遍高于周一周四和周五。迷一般的11月……
12. 电话持续时间 duration
duration: last contact duration, in seconds (numeric)
银行给客户打电话打多久呢?
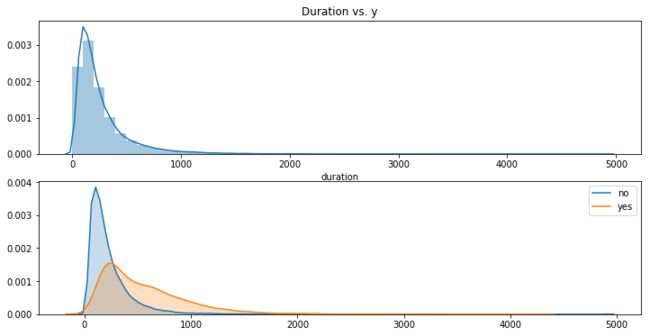
又是一个正偏态分布(median = 180s,即3分钟)。银行和绝大部分客户打电话的时间在1000秒(约15分钟)以内,此外有5个客户的打电话时间超过1小时(3600秒)。
给订购(橙色)和不订购(蓝色)产品的客户分别做密度图可以发现,如果一个客户打算订购产品,那么TA会比较愿意和银行聊聊久一点。
13. 客户联系次数 campaign
campaign: number of contacts performed during this campaign and for this client (numeric, includes last contact)
在这次的营销活动中,银行给每个用户一共打了多少次电话呢?

绝大部分都在10次以内(median = 2)。
有33位客户的联系次数在30以上,我个人觉得这很夸张(聊什么能聊得这么high=。=),但因为没有其他的信息显示这是异常值(outlier),而且和4万多条数据相比,33不是个大数目,所以暂且不对这些数据做进一步处理。
为了对这个变量有更好的理解,我把超过5次的数值都归为一类,且赋予数值6。
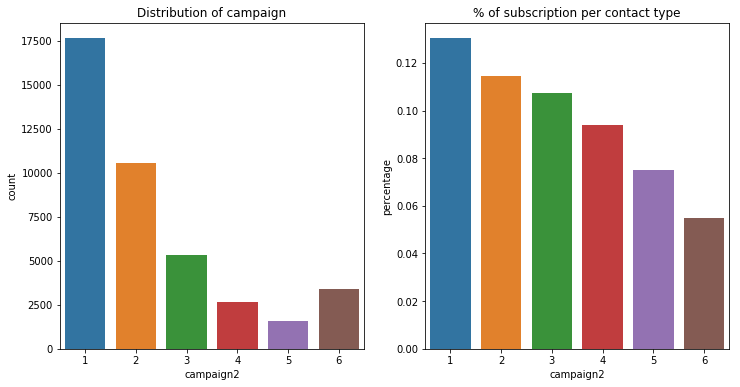
可以看到,对于大部分客户来说,银行只给他们打过1到2次电话,而且银行打电话的次数越多,客户的产品订购率其实是越低的。所以啊,死缠烂打真的不可以,请贯彻素质三连的良好方针政策(误。
14. 联系间隔天数 pdays
pdays: number of days that passed by after the client was last contacted from a previous campaign (numeric; 999 means client was not previously contacted)
这个变量记录的是某位客户在上一次营销活动和这一次营销活动中被联系的间隔天数。如果这位用户在上一次营销活动中并没有被银行联系到,那么这个变量下其对应的数据值为999。
先新建一个变量(pre_contacted)看看参与了上一次营销活动和没参与的客户的区别。
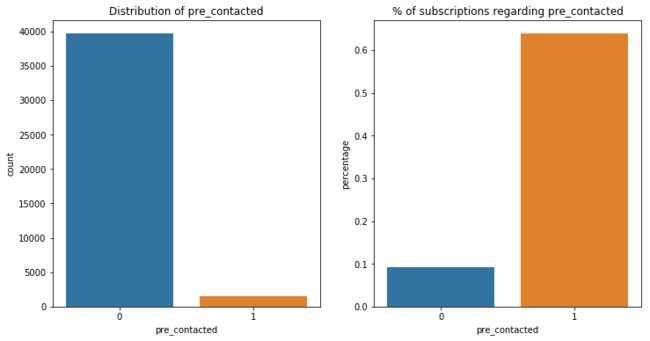
很明显,参与了此次营销活动的客户绝大部分都是新客户,而新客户的产品订购率远小于老客户。所以说,发展长期客户才是正紧事啊!
现在除去那些新客户,来看看老客户们被联系的间隔天数。
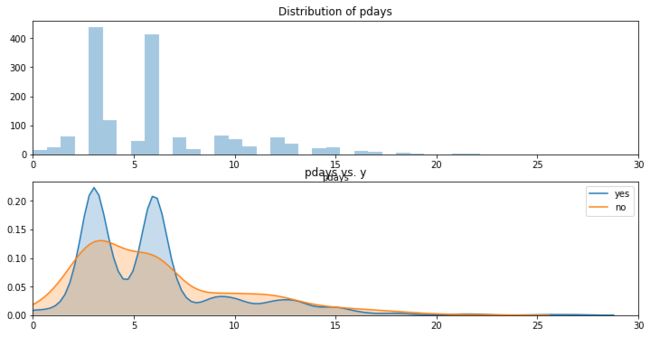
图上有一些等距间隔,这大概对应的是周六周日,毕竟周末银行休息,不打电话。
除去这些间隔,可以大概看到,大多数老客户(在上一次和这一次营销活动中的)的联系间隔为一周左右(median = 6),且此时的产品订购率要相对较高(见图中的峰值部分)。
15. 客户历史联系次数 previous
previous: number of contacts performed before this campaign and for this client (numeric)
这个变量记录的是在此次营销活动之前,某客户的联系次数。
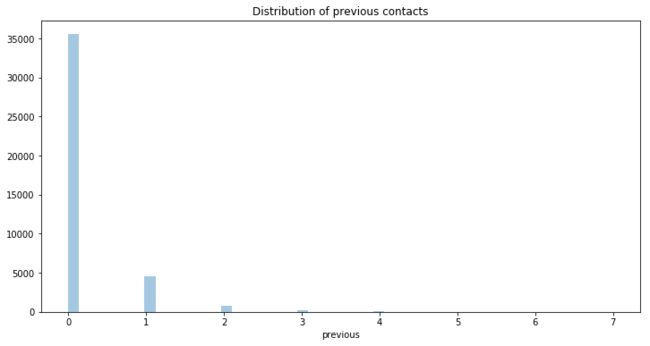
绝大多数客户的历史联系次数为0次,最多不超过7次。
事实上超过4次的客户比例相当小,为了便于分析,我把次数大于3的数据结合为一组,并赋予数值4。

可以看到,历史联系次数超过3次的客户(4对应的柱子)非常少。此外,先前有过联系的客户,其产品订购率明显高于新客户,还是那句话,发展长期客户才是王道。
16. 客户历史订购情况 poutcome
poutcome: outcome of the previous marketing campaign (categorical)
此次营销活动的客户,在上一次营销活动中是否订购了银行的产品呢?

Make sense,绝大多数客户没有历史订购情况,毕竟绝大多数客户都是新客户。另一方面,有过订购行为的老客户比其他客户的产品订购率要高得多。
17. 宏观社会经济变量 social and economic attributes
- emp.var.rate: employment variation rate - quarterly indicator (numeric)
- cons.price.idx: consumer price index - monthly indicator (numeric)
- cons.conf.idx: consumer confidence index - monthly indicator (numeric)
- euribor3m: euribor 3 month rate - daily indicator (numeric)
- nr.employed: number of employees - quarterly indicator (numeric)
这个数据集里面包含了5个宏观变量:
- Employment variation rate:就业变动率(季度)
- Consumer Price Index:消费者物价指数(月度)
- Consumer Confidence Index:消费者信心指数(月度)
- euribor 3 month rate:欧元银行三个月同业拆借利率(日)
- number of employees:就业人数(季度)
因为这些变量之间有相似性,我把它们放一起来说。
先看看这个5个变量在时间上的走势。注意,这个数据集是按时间进行记录的,但并没有具体的时间变量(虽然它包含了月份和星期数),所以下图并不是严格意义上的时间序列图,而是按数据的先后顺序做的线型图(x轴可以理解为数据所在的行数)。
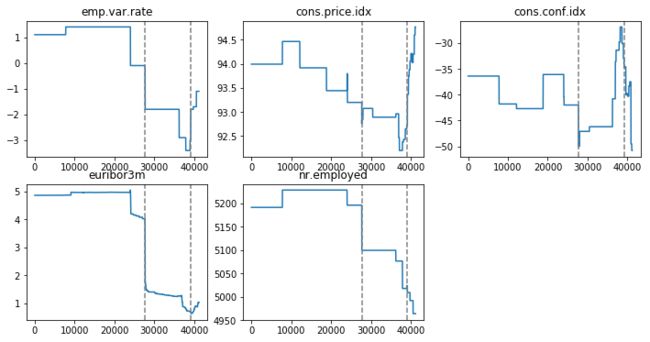
图中的虚线代表不同年份数据的交界点(这个数据集记录的是从2008年5月到2010年11月的数据)。换句话说,每个图里的最左区域、中间区域和最右区域分别代表2008年数据、2009年数据和2010年数据。
可以看到,在每个虚线位置的左右,数据在数值上有很大的变化。数值变动如此跳跃的原因是,这个数据集里没有一二月份的数据(见图10),即12月份的数据后边紧接着的是次年3月的数据,所以在这个位置上的数据是断层的。
来看一下订购和未订购产品的客户,其对应的这些宏观变量,在数值上有什么不同。下图是基于y分组的各宏观变量平均值

可以看到,客户订购银行的定存产品时,平均就业变动率、平均消费者物价指数、平均银行同业拆借率、平均就业人数比客户不订购产品时的要低(平均消费者信息指数则相反)。
大体上来说就是,社会经济情况好的时候,客户更愿意订购银行的理财产品。(这其中进一步分析,应该会得出更有趣的信息,作为门外汉的我就不献丑了。)
18. 客户联系年份 year
从图21可以看到,不同年份下的各个宏观变量在数值上变动很大(有些年份整体数值很高,有些年份整体数值很低),而从图22可以知道,在不同经济情况下,客户的金融产品订购意愿是不一样的,所以我推测2008、2009、2010这三年的整体订购率是不同的。
基于此,我构建了客户联系年份(year)这个变量,来反应每个客户在参与营销活动时对应的年份。
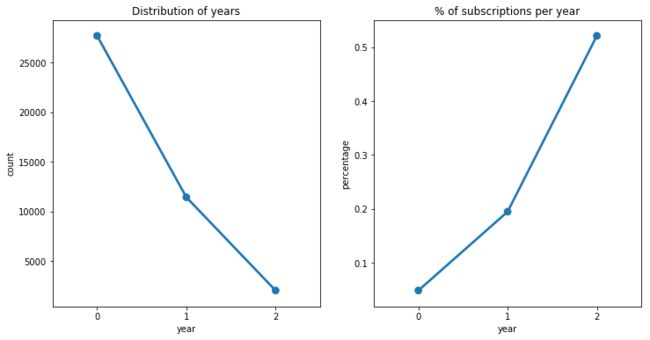
0:2008年;1:2009年,2:2010年。
可以看到,银行打电话数是逐年下降的,一个可能的原因是随着时间的推移,营销活动逐渐走向尾声,从而参与的客户数越来越少;二个可能的原因是随着时间的推移,技术不断进步,电话营销逐渐被其他形式的营销取代。
而有趣的是,另一方面,客户的产品订购率逐年上升,也许这和经济环境的改变有关,又也许是因为随着时间的推移,银行越来越能够把握和发展潜在购买客户,从而减少了不必要的联系。
现在,具体看看产品订购率逐年上升是不是和宏观经济变化相关。下图是各年份下基于y分组的各宏观变量平均值。

总体而言,客户订购银行的理财产品时,平均就业变动率、平均消费者物价指数、平均银行同业拆借率、平均就业人数相对较低,而平均消费者信息指数相对较高。这个变化在2009年最大。
结合图23和图24,问题来了:为什么2009年的两个组(y = yes 和 y = no)平均值差异最大,但2010年之后的平均订购率却比09-10年的增速大?一个可能的原因是经济活动的滞后性……
19. 数值型变量的相关系数矩阵
结束EDA这部分之前,最后再来看看各个数值型变量(numeric variable)之间的相关系数图。

图中红色代表正相关,蓝色代表负相关,颜色越深表明相关性越大。
可以看到,5个宏观经济变量之间有很强的相关性(从图21中也可以看到,各个变量的走势有相似之处),而其他的变量相互之间相关性都比较弱。
Benchmark模型
taaadaaa,终于可以开始建模部分了,这一部分谈一下我的benchmark模型。
本来呢,建模之前还有很多环节,比如处理缺失值啦,处理异常值啦,构造新特征或者特征降维啦,但是这个数据集实在是在理想了,没有什么额外的需要我做,所以就直接建模啦。
这个benchmark模型用到的是xgboost,模型参数的确立只是写了个简单的for循环,没有用到grid research,模型评估用的是ROC曲线的AUC值。此外,数据没有scaling,也没有做one-hot encoding,也没有处理imbalanced class问题。(真的是相当benchmark了。)
在跑模型之前,我删掉了2个变量:
- duration:这个变量其实是一个结果变量,毕竟只有打了电话之后才会知道电话打了多久。是否使用这个变量,取决于我们是想做interpretation还是prediction。我本来是想做interpretation的,但这个变量对模型性能的影响实在是太大了,加入之后模型的auc高达0.94,光是一个banchmark模型性能就这个好,那之后就没有什么好做的了=。=
- pdays:那个999我实在不知道怎么处理,况且我在这个变量之上有创建一个新的变量pre_contacted,所以就删掉了,如果有知道怎么处理这种情况的朋友,请告诉我,谢谢!
整个数据集,70%用于建模,30%用于测试(test set)。建模的数据中,80%是训练集(training set),20%是验证集(validation set)。
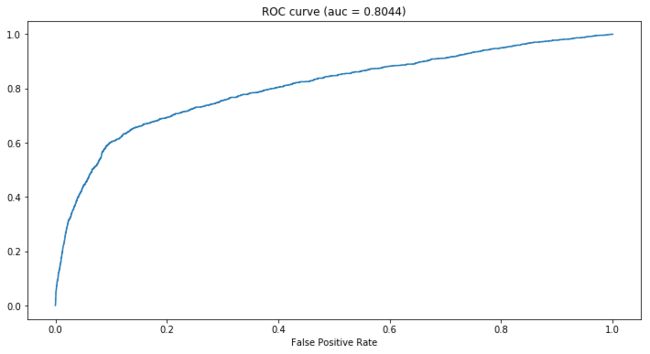
taaadaaa,benchmark模型的ROC曲线如上图所示,对应的AUC值为0.8044,表现很不错,果然数据非常理想:)
但值得注意的是,低假阳性率(False Positive Rate,FPR)对应的真阳性率(True Positive Rate,TPR)并不是很高,比如FPR为0.1时TPR只有0.6,之后我会看看能不能提高、怎么提高这部分的性能。
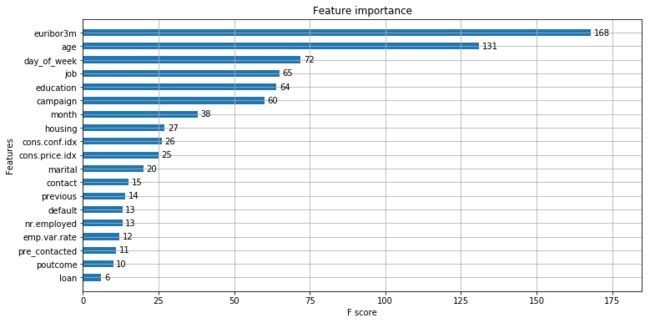
最后,看一下xgboost模型返回的特征重要性排序吧。
排在第一位的是银行拆借率,看来经济情况真的是一个很重要的指标。排在第二的是年龄,果然无聊的中年人真的比年轻人和老年人要难骗啊。(误
最后要提一下,5个经济变量中,只有银行拆借率排在前列,并不是说其余4个都不重要,而是很有可能因为这些变量之间的相关性太强,模型只需要用到其中的1个或几个,从而导致其它变量的相对重要性(建模时的使用程度)相对较低。
以上。看到底的都是勇士:)