摘要:CNN在sentence modeling和分类取得了state-of-the-art的结果,但是这些都是处理词向量sequentially并且忽略long-distance依赖。为了结合深度学习和句子结构,本文提出了一种dependency-based convolution approach,使用tree-based n-grams而不是surface ones,因此使用non-local interactions with words。
CNNs被使用在NLP的问题上,例如sequence labeling(Collober et al, 2011),semantic parsing(Yin et al. 2014) 和search query retrieval(Shen et al., 2014)。更近的是sentence modeling(Kalchbrenner et al. 2014, Kim, 2014)在很多分类问题上,例如sentiment,subjectivity和question-type classification。然而,有一个问题,CNN是基于像素矩阵的方法,只考虑连续的sequential n-grams而忽视长期以来,例如negation否定,subordination主从关系,和wh-extraction。
sentiment分析中,researchers结合了来自syntactic parse tree的long-distance information,一些说有small improvements,另一些说并没有。。。
本文作者怀疑是因为data sparsity,根据他们的实验,tree n-gram比surface n-gram会稀疏很多。但是这个问题被word embedding减轻了。
Dependency-based Convolution:
第i个词和第(i+j)词的级联操作
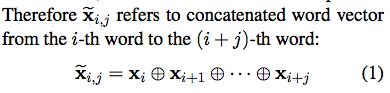
然而这个操作不能获取long-distance relationships,除非增大窗口大小,但是会造成数据稀疏问题。
Convolution on Ancestor Paths:

生成一个句子的feature map:


Max-Over-Tree Pooling and Dropout:
公式4可以当做pattern detection:only the most similar pattern between the words and the filter could return the maximum activation。
在sequential CNNs中,max-over-time polling(Collobert et al.2011, Kim,2014) 在feature map上操作获得最大的activation代表整个feature map
本文的DCNNs也pool the maximum activation from feature map.
为了获取足够多的variations,随机设置filters来detect different structure patterns。
每个filter的高度是numbers of words,宽度是word representation的维度d
each filter will be represented by only one feature after max-over-tree pooling,after a series of convolution with different filter with different height,multiple features carry different structural information become the final representation of the input sentence。
Then, this sentence representation is passed to a fully connected soft-max layer and outputs a distribution over different label.
Convolution on Siblings:
ancestor paths不能获取足够的linguistic phenomena,例如conjunction连接词, Inspired by higher-order dependency parsing(Mc-Donald and Pereira,2006; Koo and Collins, 2010)
Combined Model:
结构信息不能fully cover sequential information。并且parsing errors直接影响DCNN的performance while sequential n-grams are always correctly observed。
最简单的结合的方法是concatenate these representations together,then feed into fully connected soft-max neural networks。

实验结果:
