来源:Yanfang Ye, Tao Li, Donald Adjeroh, and S. Sitharama Iyengar. 2017. A survey on malware detection using data mining techniques. ACM Comput. Surv. 50, 3, Article 41 (June 2017), 40 pages.
一、背景
随着电脑和互联网的普及,互联网在日常生活中变得不可或缺。ITU(国际电信联盟)报告称,世界各地的互联网用户,如电子银行、电子商务、即时通讯、教育和娱乐等互联网服务,2014年(2014年)已达到29.2亿。就像物理世界一样,有些人怀有恶意。(网络罪犯)。他们试图利用合法用户,并从经济上获利。恶意软件(恶意软件的简称)是一个通用术语,用来表示所有不同类型的不需要的软件程序。这些程序包括病毒、蠕虫、木马、间谍软件、机器人、rootkit、ransomware等等。恶意软件已被网络犯罪分子用作实现目标的武器。特别是,恶意软件已经被用来发动广泛的安全攻击,比如破坏计算机,窃取机密信息,发送垃圾邮件,降低服务器性能,渗透网络,和瘫痪的关键基础设施。这些攻击通常会造成严重的损害和重大的财务损失。根据卡巴斯基实验室最近的一份报告,为了把这一观点考虑在内,大约有10亿美元是在全球金融机构因恶意软件攻击(卡巴斯基2015年)而被盗的。此外,Kingsoft报告说,每天受感染电脑的平均数量在200- 500万之间[Kingsoft 2016]。
许多恶意软件的攻击对互联网用户构成了严重的安全威胁。为了保护合法用户免受这些威胁,来自不同公司的反恶意软件产品提供了针对恶意软件的主要防御手段,如科摩多、卡巴斯基、金山和赛门铁克。通常,基于签名的方法在这些广泛使用的恶意软件检测工具中使用,以识别各种威胁。签名是一个简短的字节序列,它通常是每个已知的恶意软件特有的,允许新出现的文件以一个小的错误率正确地识别出来[Ye et al. 2011]。然而,由于经济利益,恶意软件的作者很快开发出了自动化的恶意软件开发工具包(例如,Zeus [Song et al. 2008])。这些工具包使用了一些技术,如指令虚拟化、包装、多态性、仿真和变质(instruction virtualization, packing, polymor�phism, emulation, and metamorphism),以编写和修改能够逃避检测的恶意代码[Beaucamps和ric Filiol 2007;Filiol et al . 2007]。这些恶意软件创建工具包大大降低了新手攻击者进入网络犯罪世界的障碍(允许没有经验的攻击者编写和定制他们自己的恶意软件样本),并导致新的恶意软件样本的大量扩散,这是由于他们的广泛可用性。结果,恶意软件样本迅速流行,并在全世界范围内以前所未有的速度传播和感染计算机。2008年,赛门铁克报告说,恶意程序和其他不受欢迎的代码的发布速度可能超过了良性软件应用程序[Symantec 2008]。这表明传统的基于签名的恶意软件检测解决方案可能面临巨大的挑战,因为它们可以被恶意软件作者超越。例如,根据赛门铁克的报告,在2008年,大约有180万个恶意软件的签名被发布,这导致了每月2亿次的检测[Symantec 2008]。2013年,金山软件反恶意软件实验室收集的可疑文件达到1.2亿,426万(34%)被检测为恶意软件[金山软件2014]。虽然许多恶意软件样本被检测和屏蔽,大量的恶意软件样本(例如,所谓的“零日”恶意软件[Wikipedia 2017f])已经产生或突变,他们倾向于逃避传统的基于签名的反病毒扫描工具。这促使反恶意软件行业重新考虑他们的恶意软件检测方法,因为这些方法主要基于现有的基于签名的模型的变体。为了保持有效,许多反恶意软件公司开始使用基于云(服务器)的检测[Nachenberg和Seshadri 2010;Ye et al. 2011;Stokes et,2012年。基于云的恶意软件检测采用基于云的架构(Ye et al. 2011):反恶意软件产品在客户端使用一个轻量级签名库来认证有效的软件程序,并阻止无效的软件程序,同时预测任何未知的文件(例如:在云(服务器)端上的灰色列表,并快速向客户端生成判定结果。随着恶意软件的编写和创建技术的发展,灰色列表中的文件样本数量不断增加(例如,金山云安全中心每天收集50多万个文件样本)。因此,智能方法自动检测来自云端新收集的文件中的恶意软件样本是急需的。因此,许多研究报告使用数据挖掘和机器学习技术来开发智能恶意软件检测系统[Schultz et al. 2001;Kolter和Maloof 2004;Karim et al. 2005;Lee和Mody 2006;Ye et al. 2007;Moskovitch et al . 2008;Kolbitsch et al . 2009;Ye et al. 2010, 2011;Karampatziakis et al. 2013;Tamersoy et al . 2014;2015年,萨克斯和柏林;Ni等人,2016年。
在本文中,我们首先简要介绍了恶意软件和防病毒软件行业,并介绍了恶意软件检测的工业需求。然后我们调查了智能恶意软件的检测方法。在这些方法中,恶意软件检测分为两步:特征提取和分类/聚类。这种恶意软件检测方法的性能严重依赖于提取的特征和分类技术。我们对特征提取和分类/聚类步骤进行了全面的研究。我们还讨论了利用数据挖掘技术进行恶意软件检测的其他问题和挑战,并最终预测了恶意软件开发的趋势。本文的其余部分组织如下:第2节介绍了恶意软件和反恶意软件行业的概况。第3节介绍了利用数据挖掘技术进行恶意软件检测的全过程。第4节描述了恶意软件的文件表示方法,第5节系统地讨论了恶意软件检测的特征选择方法。第6节介绍了恶意软件检测的分类,第7节描述了用于恶意软件检测的聚类。第8节进一步讨论了使用数据挖掘技术进行恶意软件检测的其他问题。第9节预测了恶意软件开发的趋势。最后,第10节总结了这篇文章。
二、恶意软件和反恶意软件行业的概述
恶意软件是故意满足恶意攻击者有害意图的软件程序[Bayer et al. 2006b]。它的设计是为了实现攻击者的目标。这些目标包括干扰系统操作、获取计算系统和网络资源,以及在未经用户允许的情况下收集个人敏感信息。因此,恶意软件通常会威胁到主机的完整性、Internet的可用性和用户的隐私。
恶意软件可以以不同的方式通过多种渠道到达系统。这些不同的方法总结如下:(1)网络上的脆弱服务允许恶意软件自动感染可访问的系统。(2)从互联网下载过程:已显示70-80%的恶意软件来自流行网站[Rehmani et al. 2011]。通过利用web浏览器的漏洞,drive - By下载能够首先从因特网获取恶意代码,然后在受害者的机器上执行代码[Egele等2012]。(3)攻击者还可以诱使受害者故意在他们的机器上执行恶意代码。典型的例子包括要求用户安装一个提供的“编解码器”来观看在网站上播放的电影,或者点击/打开附加到垃圾邮件的图片[Egele et al. 2012]。在某些情况下,恶意软件可能只会影响系统性能和创建过载进程。在间谍活动中,恶意软件隐藏在系统中,窃取计算机的关键信息,并向攻击者发送信息。
为了保护合法用户免受恶意软件攻击,主要的防御是来自反恶意软件公司的软件产品。然而,反恶意软件行业在检测和预防攻击方面越成功,在野外就可能出现越复杂的恶意软件样本。因此,恶意软件防御者和恶意软件作者之间的军备竞赛正在继续升级。在接下来的章节中,我们介绍了恶意软件的分类,阐述了恶意软件行业的发展,并描述了恶意软件检测的进展。
2.1 恶意软件的分类
基于不同的目的和扩散方式,恶意软件可以分为不同的类型。本节简要概述了大多数常见的恶意软件,如病毒、蠕虫、木马、间谍软件、ransomware、scareware、bots和rootkit。
病毒(Viruses):病毒是一段可以附加到其他系统程序的代码,当被执行时,受影响的区域被“感染”[Wikipedia 2017b]。病毒不能独立运行,因为它们需要由它们的“宿主”程序激活[Spafford 1989]。由Bob Thoma编写的爬虫病毒是一种实验性的自我复制程序,在20世纪70年代早期首次被发现[Wikipedia 2017b]。
蠕虫(Worms):不像病毒需要它的“宿主”程序运行来激活它,蠕虫是一个能够独立运行的程序。注意,蠕虫可以将自己的完全工作副本传播到其他机器上[Spafford 1989]。Morris蠕虫(在1988年被释放)是第一个公开的程序实例,它表现出类似蠕虫的行为[Spafford 1989]。在莫里斯上诉过程中,根据美国上诉法院的估计,移除莫里斯蠕虫的费用约为1亿美元[维基百科2017c]。那些臭名昭著的蠕虫,如爱门,编码,SQL的关,我的末日,和风暴蠕虫,已经成功地攻击了数以千万计的Windows电脑并且造成了巨大的损失。例如,在其发布的第一天,红色代码蠕虫(2001年首次发布)感染359000台主机在互联网上(摩尔和香农2002],虽然MyDoom的蠕虫(2004年的)减慢全球互联网接入10%,造成某些网站的访问(2011年Bizjournals)减少了50%。
特洛伊木马(Trojans):与蠕虫病毒相比,它更容易将自己的一个完整的工作版本传播到其他机器上,特洛伊病毒是一个假装有用但在后端执行恶意操作的软件程序[Schultz et al. 2001]。最近著名的特洛伊木马,宙斯(也被称为Zbot)能够执行许多恶意和犯罪的任务。宙斯经常被用来窃取与银行相关的信息,通过敲击键盘记录和获取(维基百科2017g)。2009年6月,安全公司Prevx发现,在许多公司的网站上,有超过74000个FTP账号被Zeus泄露(包括ABC、Amazon、BusinessWeek、Cisco、NASA、Monster.com、Oracle、Play.com和美国银行)[Wikipedia 2017g]。
间谍软件(Spyware):间谍软件是一种恶意程序,监视用户的活动,而不需要用户的知情或同意[边界和Prakash 2004]。攻击者可以使用间谍软件监视用户活动、收集击键和获取敏感数据(例如,用户登录、帐户信息)。
Ransomware: Ransomware是近年来最流行的恶意软件之一[Symantec 2016],它在受害者的电脑上秘密安装,并执行一种对其不利的加密病毒攻击[Wikipedia 2017d]。如果计算机被这个恶意软件感染,受害者被要求支付赎金给攻击者来解密它。
Scareware: Scareware是一种最新类型的恶意文件,旨在欺骗用户购买和下载不必要的、潜在危险的软件,如假冒的反病毒保护[Wikipedia 2016],它对受害者构成了严重的财务和隐私相关的威胁。
机器人(bot):机器人是一种恶意程序,允许机器人主人远程控制被感染的系统[Stinson和Mitchell 2007]。机器人的典型传播方法是利用软件漏洞和使用社会工程技术。一旦系统被感染,机器人主人可以安装蠕虫、间谍软件和木马,并将个人受害系统转化为僵尸网络。僵尸网络广泛用于发起分布式拒绝服务(DDoS)攻击[Kanich et al. 2008]、发送垃圾邮件和托管钓鱼欺诈。Agobot和Sdbot是两个最臭名昭著的机器人。
rootkit:一种隐秘的软件,旨在隐藏特定的进程或程序,并允许继续访问计算机(Wikipedia 2017e)。Rootkit技术可以在不同的系统级别上使用:它们可以在用户模式中调用应用程序编程接口(API),或者将操作系统结构作为设备驱动程序或内核模块进行篡改。
混合恶意软件(Hybrid Malware):混合恶意软件将两个或更多其他形式的恶意代码合并成一个新的类型,以实现更强大的攻击功能。
其他一些常见的网络害虫也会对计算机用户造成危害,比如“垃圾邮件”、“广告软件”等等。实际上,这些典型的恶意软件并不相互排斥。换句话说,一个特定的恶意软件样本可能同时属于多个恶意软件类型。
2.2 恶意软件产业发展
病毒是恶意软件的第一个实例。恶意软件作者的最初动机常常是突出安全性的弱点,或者仅仅是为了展示他们的技术能力。此外,为了躲避反恶意软件的检测,恶意软件作者和攻击者开发并应用了各种隐藏技术:(1)加密(Encryption):加密的恶意软件包括加密算法、加密密钥、加密的恶意代码和解密算法[Sung et .2004]。密钥和解密算法用于解密恶意软件中的恶意组件。攻击者使用新生成的密钥和加密算法,并生成新版本的恶意软件以逃避检测。(2)打包(Packing):打包是一种用于加密或压缩可执行文件的技术[Kendall和McMillan 2007]。通常情况下,要揭示包装恶意程序的整体语义,需要打开一个解包的阶段。(3)混淆:Obfuscation [Sung et .2004]的目的是隐藏程序的底层逻辑,防止其他人对代码有任何相关的知识。典型的混淆技术包括添加垃圾命令、不必要的跳转等等。通过应用混淆,恶意代码及其所有有害功能在被激活之前仍然无法理解。(4)多态性(Polymorphism)[Bazrafshan et al. 2013]:一个多态性的恶意软件每次被复制时都被设定为不同的外观,同时保持原始代码的完整性。不同于简单的加密,多态恶意软件可以使用无限数量的加密算法,在每次执行中,解密代码的一部分将会改变。根据恶意软件类型,恶意软件执行的不同恶意操作可以被置于加密操作之下。通常,一个转换引擎嵌入到加密的恶意软件中。注意,在任何更改中,引擎都会生成一个随机加密算法。然后,使用生成的算法对引擎和恶意软件进行加密,并与它们连接新的解密密钥。(5)变形(Metamorphic)(Bazrafshan et al. 2013;Crandall et al. 2005]:变形恶意软件是最复杂的恶意软件。在变形的恶意软件中,恶意代码改变了自己,使一个新的实例与原始的实例没有相似之处。恶意软件没有任何编码引擎。在每个传输中,恶意软件源代码中会自动发生更改。
恶意软件作者的动机随着时间的推移而改变。随着计算机的普及和互联网的高速发展,电子商务在银行业和金融业中得到了广泛的应用。eMarketer的最新预测显示,全球B2C电子商务销售额将达到1.5万亿美元[eMarketer 2014]。因此,在今天的电子商务中,存在着一个蓬勃发展的地下恶意软件经济[zbig et al. 2008]。通过传播破坏性的有效载荷,恶意软件可以首先感染并控制脆弱的计算机系统,并利用它们获取非法资金[Zhuge et al. 2008]。金钱的前景,而不是有趣的因素,成为恶意软件开发的驱动力。在相当大的经济利益的驱动下,恶意软件样本的多样性和复杂性在过去几年显著增加[Hu 2011]。例如,Ramnit最初是2010年发现的一种普通蠕虫病毒,后来被恶意软件作者修改为盗取了45,000个Facebook账户。通过从宙斯木马上获取的一些代码从web会话中获取数据,当前版本的Ramnit是原始蠕虫的混合版本,它允许黑客进行财务欺诈。木马程序的设计目的是提供未经授权和远程访问的电脑,允许黑客窃取敏感信息(如Facebook账户或电子银行账户),它的受欢迎程度越来越高,目前在恶意软件收集中占多数(73%)[Ye 2010]。
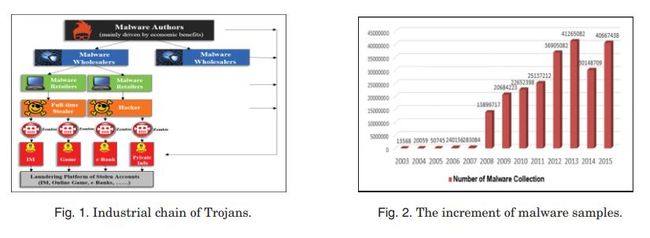
现在已经有一个成熟的木马产业链(如图1所示),在经济效益方面是有利可图的:从木马的创建到规避检测、传播、bot控制、账户盗窃、销售。劳动分工十分明确,整个过程和组织构成了一个健全完整的装配线。在中国,这样一个黑色链的增长速度非常快,每年的产值可以超过10亿美元[Ye 2010]。
然而,尽管恶意软件更加复杂,编写和定制恶意软件的必要知识实际上已经大大减少[Hu2011]。这主要是由于许多自动恶意软件创建工具包的可用性,这些工具也易于使用,比如Zeus [TrendMicro 2010]和SpyEye [Coogan 2010]。这些工具包允许没有经验的攻击者定制并创建恶意软件程序来实施网络犯罪,这将导致大量的恶意软件变体。此外,许多恶意软件样本不断变异,以绕过反恶意软件供应商的检测。而不是从头编写一个新的恶意软件,恶意软件作者总是采取一种更具成本效益的策略来完善现有的恶意软件样本(略有修改源代码或二进制文件)他们绕过反恶意软件扫描检测,使用一组不同的工具和技术通常包括指令重新排序,垃圾插入,等同替换代码和运行时包装。因此,这些变种的恶意软件样本已经演化成一个流排列的过程[奥曼2010]。由于恶意软件的变种可以自动和快速地生成,恶意软件作者可以替换过时的恶意软件,在新的检测签名被开发和更新之前,给他们的变种提供一个有利的攻击窗口。这种恶意软件突变过程的易用性导致了新的恶意软件文件样本的指数增长[Ye等人,2009c]。基于金山云安全中心提供的数据[Kingsoft 2014, 2015, 2016],图2展示了从2003年到2015年中国恶意软件样本的增长趋势。该数据显示,自2008年以来,恶意软件样本的数量急剧增加,2015年收集的新恶意软件样本总数达到4066万例[金山软件2016]。不幸的是,这种趋势可能会继续下去,恶意软件仍将是互联网用户面临的最大安全威胁之一。
2.3 恶意软件检测的进展
2.3.1。基于签名的恶意软件检测。为了保护合法用户免受恶意软件的威胁,来自反恶意软件公司的软件产品(例如,来自科摩多、卡巴斯基、金山、麦咖啡和赛门铁克的产品)提供了主要的防御。通常,他们使用基于签名的方法来识别已知的威胁。签名是每个已知的恶意软件的一个简短的字节序列,它允许新遇到的文件以一个小错误率正确地识别出来[Ye et al. 2011]。图3显示了一个用于检测在线游戏木马的示例签名。

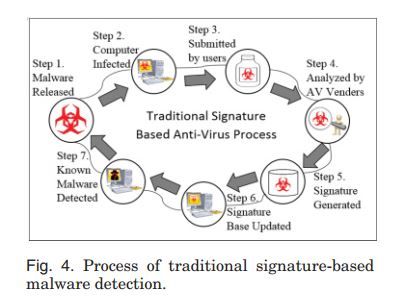
基于签名的方法从二进制代码中识别唯一的字符串[Moskovitch et al. 2009]。这种传统检测方法的过程如图4所示。每当一种新的恶意软件被释放,反恶意软件供应商就需要获得新的恶意软件的实例,分析实例,创建新的签名,并在他们的客户端部署(Micropoint 2008;Moskovitch et al . 2009]。传统上,签名基础通常是由领域专家手工生成、更新和传播的。这个过程通常被称为时间和劳动消耗。这种检测方法使得反恶意软件工具对新威胁的响应能力较弱。它甚至可能允许一些恶意软件样本绕过检测,并在很长一段时间内不被发现。例如,一个恶意软件的发布到它被反恶意软件软件工具检测的一个典型的时间窗口大约是54天[Hu 2011]。在更糟糕的情况下,在180天之后,15%的样本仍未被发现[Damballa 2008]。
2.3.2 基于启发式的恶意软件检测。通过应用上面描述的对策(例如加密、打包、混淆、多态性和变质),恶意软件作者可以轻松绕过基于签名的检测。从20世纪90年代末到2008年,基于启发式的方法是检测恶意软件最重要的方法。基于启发性的检测是基于专家确定的规则/模式,以区分恶意软件样本和良性文件。这些规则/模式应该足够通用,可以与相同恶意软件威胁的变体保持一致,但不能与恶意文件相匹配[Egele et al. 2012]。然而,恶意软件样本的分析和领域专家对规则/模式的构建往往容易出错,且耗时。更重要的是,如上所述,在经济利益的驱动下,恶意软件行业已经发明了自动的恶意软件开发工具包(如Zeus [TrendMicro 2010]),可以每天创建和变异数千个恶意代码,这些代码可以通过传统的基于签名或基于启发式的检测[Symantec 2008]。因此,人工分析已成为恶意软件分析工作的主要瓶颈,要求智能技术自动分析传入的样本。这种智能技术可以让反恶意软件供应商跟上快速的恶意软件生成和部署,同时减少他们对新的恶意软件威胁的响应时间。此外,恶意软件创建的速度(例如,超过10,000个新的恶意软件/天)比签名生成速度快,而且签名的增加使得客户变得越来越“沉重”。
2.3.3 基于云计算的恶意软件检测。为了克服上述挑战,并保持有效,许多反恶意软件供应商已经使用基于云(服务器)的检测。基于云的检测工作流如图5所示。具体来说,该方案可以在以下[Ye et al. 2011]中描述:
(1)用户通过客户端不同渠道从互联网接收新文件。
(2)客户端上的签名集首先被反恶意软件产品用于扫描新文件。如果现有的签名不能检测到这些文件,那么这些文件将被标记为“未知”。
(3)收集未知文件的信息(如文件声誉、文件特性、甚至文件)并发送到云服务器。
(4)在云服务器上,分类器(s)对未知文件样本进行分类,生成判决(良性或恶性)。
(5)裁决结果将立即发送给客户。
(6)基于云服务器的结果,客户端扫描过程进行检测。
(7)随着云服务器的快速响应和反馈,客户端用户将拥有最新的安全解决方案。
综上所述,恶意软件检测现在以客户端-服务器方式进行,采用基于云的架构[Ye et al. 2011]:从黑名单中屏蔽无效的软件程序,从客户端(用户)的白列表中验证有效的软件程序,并预测任何未知的文件(例如:,在云(服务器)端显示灰色列表,并快速向客户端生成结果。灰色列表包含未知的软件文件,这些文件可能是良性的,也可能是恶意的。传统上,灰色列表被恶意软件分析人员拒绝或手动验证。随着恶意软件的编写和创建技术的发展,灰色列表中的文件样本数量不断增加。例如,Kingsoft或Comodo云安全中心收集的灰色列表通常每天包含超过500,000个文件示例[Ye 2010]。因此,迫切需要开发智能技术,以便在云(服务器)端支持高效、有效的恶意软件检测。
近年来,金山安全产品等商业产品[Ye et al. 2009c, 2010],科摩多杀毒(AV)产品[Ye et al. 2011];Chen et al. 2015;Hardy et al. 2016],赛门铁克的抗alware (AM)产品[Chau et al. 2011],以及微软的Internet Explorer [Stokes et al. 2012]已经开始使用数据挖掘技术来执行恶意软件检测。
3 应用数据挖掘技术进行恶意软件检测的总体过程
近年来,基于数据挖掘技术的恶意软件检测被大量报道。这些技术能够对以前不可见的恶意软件样本进行分类,识别恶意软件样本的恶意软件家族,以及/或推断签名。在这些系统中,检测通常是两步过程:特征提取和分类/聚类。图6显示了使用数据挖掘技术的恶意软件检测的整个过程。在第一步中,静态和/或动态地提取各种特性(参见第4节),如API调用、二进制字符串和程序行为,以捕获文件示例的特征。在第二步中,利用分类或聚类等智能技术,在分析特征表示的基础上,自动将文件样本分类为不同的类/组。注意,这些基于数据挖掘的恶意软件探测器主要区别于特征表示和所使用的数据挖掘技术。

分类:对任何未知文件进行分类,可以是良性的,也可以是恶性的,分类过程可以分为两个连续步骤:模型构建和模型使用。第一步,向系统提供包括恶意软件和良性文件在内的训练样本。然后,对每个样本进行解析,提取代表其基本特征的特征。提取的特征被转换为训练集中的向量,将每个样本的特征向量和类标签作为分类算法(如人工神经网络(ANN)、决策树(DT)和支持向量机(SVM))的输入。分类算法通过对训练集的分析,建立分类模型(或分类器)。然后,在模型使用阶段,一个新的未知的文件样本的集合,也可以是良性的或恶意的,被提交给从训练集中生成的分类器。请注意,新文件样本的代表向量首先提取(使用相同的特征提取技术在训练阶段)。分类器根据提取的特征向量对新的文件样本进行分类。
聚类:在许多情况下,很少有标记训练样本用于恶意软件检测。因此,研究人员提出了使用聚类来自动将具有相似行为的恶意软件样本分组到不同的组中。聚类是对一组对象进行分组的任务,使得同一组中的对象(被称为集群)比其他组(集群)中的对象彼此更相似(例如,使用特定距离或相似性度量)。聚类允许自动的恶意软件分类,并且还能够生成用于检测的签名。
为了评估目的,通常采用表一所示的经典方法来评估基于分类的恶意软件检测的性能。注意,在恶意软件检测中,恶意软件样本通常被用作阳性实例。真正的阳性率(TPR)衡量的是恶意软件样本(即。通过分类模型对正实例进行了正确的分类,而假阳性率(FPR)是良性文件的分类率(即错误分类(例如:,误分类为恶意软件样本)。Accuracy (ACY)度量正确分类的文件实例的速率,包括正实例和负实例。使用传统方法的评估方法通常被称为累积方法(cumulative approach)[Nachenberg和Seshadri 2010]。累积方法衡量的是在实例级的恶意软件检测方法/系统的性能(例如,每级文件)。还有另一种度量方法,称为基于交互的度量方法(interactive-based)[Ramzan et al. 2013],它试图在事务级度量恶意软件检测方法/系统的性能(考虑到不同的用户群)。基于交互的度量方法基于实际的用户群来度量恶意软件检测方法/系统的真实保护和虚假正面影响。例如,假设在时间T,有两个测试文件的恶意软件,(有100万用户)和B(10个用户),和恶意软件检测方法/系统错误分类的第一个文件(例如,一个假阴性,将恶意软件划分为一个良性的文件),但第二个文件B正确归类为恶意软件样本。仅基于这两个文件,累积测量将给出50%的准确性,因为它正确地分类一个文件,而一个文件不正确;但是在基于交互的测量方法中,它会根据A和b的用户对错误的负面和真实的优点分配不同的权重。对于基于集群的方法,不同算法的性能通常是通过使用宏f1和微f1度量来评估的,这两种方法分别强调了系统在罕见的和常见的分类上的性能。
4 特征提取
特征提取方法提取用于表示文件样本的模式。在本文中,我们主要讨论对Windows可执行文件的检测。注意,PE是Windows操作系统的一种常见文件格式,而PE恶意软件是大多数恶意软件样本。注意CIH、CodeBlue、costed、Killonce、LoveGate、Nimda、Sircam和Sobig都针对PE文件[Ye et al. 2007]。恶意软件检测中主要有两种不同类型的特征提取:静态分析和动态分析。

4.1 静态分析
静态分析分析PE文件而不执行它们。静态分析的目标可以是二进制或源代码[Christodorescu和Jha 2003]。如果PE文件被第三方二进制压缩工具(例如UPX和ASPack Shell)压缩或嵌入自制的封隔器中,则需要首先对其进行解压/解压[Yeet al. 2007]。要对windows可执行文件进行反编译,可以使用反汇编器(disassembler)和内存转储器工具(Memory dumper tools)。反编译工具(例如,IDA Pro IDAPro 2016)显示恶意软件代码为英特尔86汇编指令。内存转储工具(例如,OllyDump[2006]和LordPE[2013])用于获取位于主内存中的受保护代码,并将其转储到文件中[Gandotra et al. 2014]。内存转储对于分析打包的难以分解的可执行文件非常有用。在解压缩和解密可执行文件之后,可以提取静态分析中使用的检测模式,如Windows API调用、字节N-gram、字符串、操作码(操作码)和控制流图。
——Windows API调用:几乎所有程序都使用Windows API调用向操作系统发送请求[Orenstein 2000]。因此,Windows API调用可以反映程序代码片段的行为。例如,“KERNEL32”中“GetVersionExA”的Windows API。恶意软件可以使用DLL来检查当前操作系统的版本,这是通过调用系统调用实现的。因此,Windows API之间的关联和关系可能捕获恶意软件行为的底层语义,并可作为恶意软件检测的基本特性,如“KERNEL32”中的Windows API调用。“OpenProcess”、“CopyFileA”、“CloseHandle”、“GetVersionEx A”、“GetModuleFileNameA”和“WriteFile”的DLL在恶意软件样本集合中总是同时出现,而很少在良性文件集中同时出现[Ye et al. 2007]。
——N-gram: N-gram是程序代码中长度为N的子字符串[Henchiri和Japkowicz 2006a]。例如,“82EDD875”序列被分割(表示)为5-gram,分别为“82EDD”、“2EDD8”、“EDD87”和“DD875”。在过去的十年中,许多研究基于二进制代码内容进行了未知的恶意软件检测;[2004],[2004],[2005],Elovici等[2007],Masud等[2007],Anderson等[2012]。
—— string:可解释字符串是恶意行为的高级规范。这些字符串可以反映攻击者的意图和目标,因为它们包含重要的语义信息[Ye et al. 2009]。例如,“window.open(‘readme.eml’)” 总是存在于“Nimda”的蠕虫中,暗示蠕虫试图感染脚本。另一个例子是字符串“&gameid = %s&pass = %s;myparentthreadid = % d;myguid =%s,“这表明攻击者意图窃取在线游戏的密码并将其发送回服务器。”此外,字符串是健壮的特性,恶意软件作者不容易逃避基于字符串的检测。这是因为即使恶意软件变体可以通过重新编译或采用混淆技术生成,修改所有可解释的字符串在大多数程序中也不实用[Ye et al. 2009]。
——Opcodes(操作码):操作码是机器语言指令的子部分,用于标识要执行的操作[Wikipedia 2017a]。更具体地说,程序被定义为一系列有序的汇编指令。指令是由操作码、操作数或操作数列表(例如“mov ebx”、“add eax 1”、“xor eax eax”和“call sub_401BCD”)组成的一对指令。指令段通常可以反映程序的功能。研究表明,在实践中,来自相同源代码或属于同一家族的恶意软件样本通常共享大量的指令块/段[Ye et .2010]。
——Control Flow Graphs (CFGs)控制流图:CFG是表示程序控制流的图。CFGs广泛应用于软件分析,也被广泛研究[Anderson et al. 2012]。
还有许多其他静态特性来表示文件示例,如文件属性、文件资源信息和导出表。静态分析能够探究恶意软件样本中所有可能的执行路径。因此,它在检测恶意逻辑方面具有详尽的优点。换句话说,静态分析没有动态分析所遇到的覆盖问题。静态分析的另一个优点是,分析器的机器不能被正在研究的恶意软件攻击。静态分析的一个缺点是,在处理某些情况时,由于不可判定性(例如,通过函数指针间接控制转移)而无法进行。因此,无论何时需要进行分析,都必须在精确和效率之间做出权衡。静态分析的其他缺点包括缺乏对运行时打包代码的支持以及与复杂混淆相关的限制。Moser等人[2007]讨论了静态分析的缺点。他们认为,动态分析可以成为静态分析的必要和有用的补充。
4.2 动态分析
动态分析技术(例如,调试和分析)观察PE文件的执行(在真实或虚拟处理器上),以获得特性[Egele等人2012]。可以采用自动启动可扩展性点、函数参数分析、函数调用监控、信息流跟踪、指令跟踪等多种技术进行动态分析[Egele et al. 2012];Gandotra et al . 2014]。典型的动态分析工具包括Valgrind [Nethercote和Seward 2007]、QEMU [QEMU 2016]和strace。对恶意软件的动态分析已经有了大量的研究,在执行环境中对恶意软件和分析粒度进行了不同的分析。下面我们根据执行环境对动态分析技术进行分类:
——Debugger:在指令级别上,可以使用GDB (Loukides和Oram 1996)、Windbg (Robbins 1999)或Softice (Compuware 1999)等调试器对二进制代码(包括恶意软件)进行细粒度分析。然而,大多数恶意软件(如果不是全部的话)已经变得足够智能,可以通过监视对代码的更改来检测调试器的存在,这些更改是支持断点(调试的主要工具)所必需的。为了对抗这种反调试的恶意软件,研究了新的调试方法。吸血鬼[Vasudevan和Yerraballi 2005]支持秘密断点,通过利用虚拟内存和硬件单步机制,帮助调试自修改和/或自检查恶意软件。构建于吸血鬼之上的Cobra [Vasudevan和Yerraballi 2006]是一个细粒度的恶意软件分析框架,可以选择性地部署在恶意代码流上,以提高分析效率。最后,Ether [Dinaburg et al. 2008]是一种调试工具,它利用诸如Intel VT [Intel 2013]等硬件虚拟化扩展,使恶意软件看不到它。
——Simulator模拟器:这组工具在受控环境中运行恶意软件并监视其行为。例如,Detours [Hunt and Brubacher 1998]是一种动态检测工具,可以检测恶意软件示例调用的Windows API,而CWSandbox [Willems et al. 2007]通过执行API连接和DLL注入来监控恶意软件调用的Windows API。
——仿真器(Emulator):TTAnalyze [Bayer et al. 2006a]是一个基于qemu的动态恶意软件分析框架,监控Windows API调用和Windows本机系统调用,以及函数调用参数。BitBlaze二进制分析平台中的TEMU是一个仿真器,它支持指令级的动态检测和整个系统的污染跟踪。一些专门的分析工具[Caballero et al. 2007;Kang et al. 2007;Yin等人2007]已经在TEMU之上建立。K-Tracer [Lanzi et al. 2009]动态跟踪Windows内核级rootkit的执行情况,以查找其系统数据操作行为。
——虚拟机(Virtual Machine):Strider honeymonkey [Wang et al. 2006a]通过在Microsoft Virtual PC和Virtual server为基础的环境中访问恶意网站,并识别这种访问导致的持续系统状态变化,从而确定恶意网站。vGrounds [Jiang et al. 2005]研究基于用户模式的Linux (UML)虚拟环境中的蠕虫行为。
在动态特征提取中,配置或环境相关的信息(如变量值、系统配置和程序输入)在提取过程中被解析。这是动态分析的一大优势。这些环境或配置依赖于静态分析会造成困难,因为它们超出了代码本身。动态分析在分析打包的恶意软件时特别有用,因为在大多数情况下,当恶意软件运行时,在某个时刻,恶意软件必须自行解压,其原始代码将位于主存中。Renovo [Kang et al.2007]就是这样一个工具,它通过跟踪恶意软件新写入的内存区域来提取隐藏的代码,即使它是通过多层压缩和加密来隐藏的。有限的覆盖范围是动态分析的一个缺点。原因是一个执行会话只能在恶意软件中探索一个特定的程序路径。但是一些恶意软件行为可能取决于某些特殊的条件(例如,在特定的时间,当收到特定的文件,或者执行特定的命令/操作)。
此外,由于恶意软件样本在运行时暴露其所有行为需要时间,因此动态分析通常要比静态分析耗费更多的时间和资源。因此,这些特性限制了在商业分析系统中采用动态分析。
4.3 混合分析
静态和动态特征提取方法都有各自的优点和局限性。与动态特性表示相比,静态方法更便宜,可以覆盖所有的代码路径(包括不总是执行的程序片段),因此可以更准确、更完整地描述程序功能[Hu 2011]。然而,由于低层次的突变技术(例如混淆和包装),它的性能开销很大。相反,动态分析能够抵抗低层次的混淆,适合检测恶意软件变体和新的家庭,但是在基于触发的恶意软件样本上表现很差。此外,由于动态分析的覆盖范围有限,它的成本很高,而且不具有可扩展性。根据Comodo云安全中心的统计数据,大约80%的文件示例可以使用静态特性得到很好的表示,而大约40%的文件示例可以动态运行[Ye et al. 2011]。
由于它们各自的优缺点,无论是静态的还是基于动态的特征提取方法都不能为恶意软件分析中的特征提取提供一个完美的解决方案[Hu 2011]。因此,需要一种综合的方法,将静态和动态分析结合起来,并获得两者的好处。混合分析是一种结合静态分析和动态分析各自优点的分析方法。例如,打包的恶意软件可以首先通过一个动态分析器,如PolyUnpack [Royal et al. 2006],通过比较恶意软件实例的运行时执行与其静态代码模型,提取打包恶意软件实例的隐藏代码体。一旦隐藏代码主体被发现,静态分析器就可以继续分析恶意软件。
4.4 其他新特征
也有一些研究使用文件内容的语义来表示文件示例。例如,Christodorescu等[2005]提出了一种感知语义的恶意软件检测方法。在提出的框架中,使用模板描述恶意行为,模板是使用变量和符号常量的指令序列。基于提取的特征,提出了一种基于语义感知的恶意软件检测匹配算法。
除了从文件内容中提取的静态和动态特性之外,还有其他可以代表恶意软件或良性文件的特性吗?正如《圣经》中所说:“人因其所结交的人而为人所知。”“实际上,不同文件样本之间的关系可能意味着它们之间的相互依赖,可以提供关于它们的属性和特征的关键信息[Ye et al. 2011];Tamersoy et al . 2014]。更准确地说,一个文件的合法性可以通过分析它与其他标记为(良性或恶意的)对等点的关系来推断。例如,如果一个未知的文件总是与许多木马程序共存,那么该文件很有可能是恶意的木马程序-下载加载程序[Ye et al. 2011],可以从远程服务器下载并安装多个不需要的应用程序(例如,trojan, adware)。Ye等人将文件关系和文件内容结合起来进行恶意软件检测。特别是,他们提出的方法已经被成功地整合到Comodo的反恶意软件产品中[Ye et .2011]。最近,更多的商业反恶意软件产品,包括赛门铁克的AM产品[Nachenberg和Seshadri 2010]和微软的Internet Explorer [Stokes et al. 2012]已经开始使用文件内容以外的特性来检测恶意软件:(1)赛门铁克的AM产品通过分析文件-机器关系(Chau et al. 2011),通过对文件-机器关系的分析来判断文件的声誉,并且还使用了文件关系图[Tamersoy et al. 2014]检测恶意软件;(2)微软的ie浏览器使用文件定位进行恶意软件检测[Venzhega et al. 2013]。
表二总结了不同特征提取方法在恶意软件检测中的一些代表性研究。
