决策树在sklearn中的实现
小伙伴们大家好~o( ̄▽ ̄)ブ,首先声明一下,我的开发环境是Jupyter lab,所用的库和版本大家参考:
Python 3.7.1(你的版本至少要3.4以上
Scikit-learn 0.20.0 (你的版本至少要0.20
Graphviz 0.8.4 (没有画不出决策树哦,安装代码conda install python-graphviz
Numpy 1.15.3, Pandas 0.23.4, Matplotlib 3.0.1, SciPy 1.1.0
用SKlearn 建立一棵决策树
这里采用的数据集是SKlearn中的红酒数据集。
1 导入需要的算法库和模块
from sklearn import tree #导入tree模块
from sklearn.datasets import load_wine #导入红酒数据集
from sklearn.model_selection import train_test_split #导入训练集和测试集切分包
2 探索数据
wine = load_wine()
wine.data
wine.data.shape
wine.target
wine.target.shape
运行的结果是这样子的:

data就是该数据集的特征矩阵,从运行结果可以看出,该红酒数据集一共有178条记录,13个特征。

特征矩阵中有178条记录,相对应的标签Y就有178个数据。
如果wine是一张表,应该长这样:
import pandas as pd
pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1)

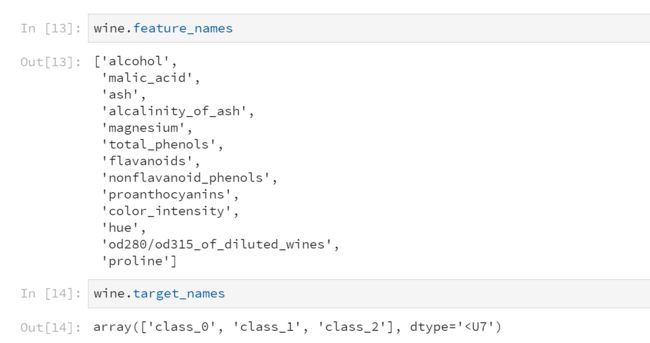
这是数据集特征列名和标签分类
wine.feature_names
wine.target_names
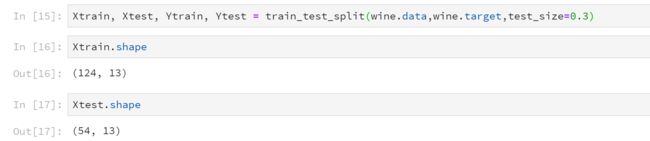
3 分训练集和测试集
这里选取30%作为测试集。切分好之后,训练集有124条数据,测试集有54条数据。
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
Xtrain.shape
Xtest.shape
4 建立模型
clf = tree.DecisionTreeClassifier(criterion="entropy") #初始化树模型
clf = clf.fit(Xtrain, Ytrain) #实例化训练集
score = clf.score(Xtest, Ytest) #返回预测的准确度
score

5 画出一棵树吧
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
import graphviz
dot_data = tree.export_graphviz(clf
,out_file=None
,feature_names= feature_name
,class_names=["琴酒","雪莉","贝尔摩德"]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
graph

6 探索决策树
#特征重要性
clf.feature_importances_
[*zip(feature_name,clf.feature_importances_)]

到现在为止,我们已经学会建立一棵完整的决策树了。有兴趣的话,动手建立一棵属于自己的决策树吧~
更多内容可移步:https://www.cda.cn/?seo-jianshu