iOS开发的核心语言是Objective-C,Objective-C是在C语言的基础加了一层面向对象的语法。为了能够更好地掌握Objective-C,我们可以先学习C语言,然后在C语言的基础上升华到Objective-C。
C语言:
是编译型语言;
*C语言于1972年发明,首次使用是用于重写UINX操作系统(UNIX以前是用汇编写的)
*C语言是一门面向过程的语言,非面向对象的语言
++ 特点:
*弱语法;
*提供了34种运算符;
*有丰富的数据类型;整型(int)、float、char、int[]、指针类型(void *)、结构体类型(struct)、共用体类型(union)等;
*允许直接访问物理地址,对硬件进行操作;最强大的是指针,可通过指针直接访问内存地址,使用得当,可节省代码量,优化内存管理、提高性能;
*具有高级语言的功能,又具有低级语言的许多功能能如汇编语言一样对位(bit)、字节和地址进行操作(这三者是计算机工作的基本单元);
*高效率的目标代码;可读性好,易于调试,修改和移植,代码质量与汇编相当;
*可移植性好;在一个环境上用C语言编写的程序,不改动或稍加改动,就可移植到另一个完全不同的环境中;
**不足:
*由于C语言是面向过程的,因此它的数据封装性差、安全性低,这就是C语言和其他面向对象语言的区别之一。面向对象语言的特性之一就是数据的封装性;
*语法限制不严格,对变量的类型约束不严格,对数组下标越界不作检查等;
+使用:
*由于C语言具有强大的数据处理能力,而且允许直接访问物理地址,直接对硬件操作,因此它适于编写系统软件、图形处理、单片机程序、嵌入式系统开发甚至是用于科研;
- 很多操作系统的底层都是用C语言写的,比如android;
*iOS开发中的核心语言是Objective-C(简称OC),OC是在C语言的基础上加了一层面向对象语法;
+标准:1983年美国国家标准局(American National Standards Institute,简称ANSI)成立了一个委员会,开始制定C语言标准的工作。1989年C语言标准被批准,这个版本的C语言标准通常被称为ANSI C;
— Xcode中的C语言是在标准的C 语言上做了一些封装;
+语法:
[goto语句一般很少使用,会破坏程序的结构;占位符同android string;%f 默认6位小数;]

函数(方法):
以#开头为预处理指令;在编译之前执行的指令;include的作用只是把后面<**>中的内容拷贝到该处;
若导入的文件是系统自带的文件用<>,自己写的文件用”";
.h称为头文件;用来声明一些常用的函数;若想使用这些函数,就必须包含这个头文件;函数具体的实现是放在其他文件的;
一个C程序只有一个入口main函数;
面向过程:就是先分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用函数就可以了;(只写函数,不使用对象)
一个C程序中一定会有一个main函数,也只能有一个main函数。main函数是整个C程序的入口。main.c的第3行代码就定义了一个main函数。
main函数的返回值为int类型,接收2个参数,其实可以不写参数;
main函数没有写返回值类型,并不代表函数没有返回值,而是表示返回值类型为int类型,void才代表函数没有返回值;可直接写main(){…}
+运行过程:
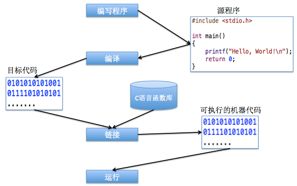
目标代码须和C 语言的函数库链接在一起,找个头文件中的引用的函数名的实现生成的机器代码才能运行。
+1+ 编写程序
C语言源文件的扩展名为”.c”,源文件以ASCII码形式存储,不能直接被计算机执行;
+2+ 编译(VC)[main.c—>main.obj]
1)把C的源程序翻译成计算机可以识别的二进制形式的目标代码文件,这个过程称为编译,由C的编译器完成
2)在编译的同时,还对源程序的语法等进行检查。若出现语法错误,则编译失败。如果编译成功则生成目标文件,目标文件名跟源程序文件名一样,扩展名为".obj"。比如,mj.c编译后生成目标文件mj.obj
3)每个源文件是单独进行编译的,假如一个项目中有多个.c源文件,编译成功会生成多个对应的.obj目标。一般情况下,目标文件之间是有关联的,比如 a.obj 可能会调用 b.obj 中定义的一个函数,因此它们都不能够单独被计算机执行,而且目标文件中并不包含程序运行所需要的库函数等
头文件不会被编译;
+3+ 链接(VC下)
将所有有关联的obj目标文件,以及系统提供的C库函数等组合在一起生成可执行文件的过程,称为"链接"
链接生成的可执行文件的文件名跟源程序文件同名,(win下)扩展名为”.exe”,计算机可以直接执行;
+4+ 运行
win下的.exe;Mac下为exec,双击即可执行;
函数:
主函数:main;有且只有一个;不论什么位置,都是从main 开始执行;
自定义函数:
C库提供的库函数;
++ 声明与定义:
在标准C语言中,是从上向下编译,故只有后面的函数才能调用前面定义过的函数;
[在使用中可将函数名在mian()方法前声明,在项目开发中,为了分模块开发,一般会将函数的声明和定义(实现)分别放在2个文件中,函数声明放在.h头文件中,函数定义放在.c源文件中;这样使项目结构清晰。]
(由于include只是拷贝,可直接include “header.c”;但不能重复导入头文件,故一般不这样写;””的方式是先在当前源程序下找,若打不到,再到系统的path中找;<>是只在c语言库函数文件中找)
—-[函数在整个项目中不允许重复定义,不支持重载]—-
形参和实参:若是基本数据类型作为函数的形参,那就是简单的传递,将实参赋值给了形参b;和b是分别有着不同内存地址的2个变量,因此改变了形参b的值,并不会影响实参a的值。
— printf():
占位符:
%d 整型,%4d表示占用4个位置空间;
%s String
%c char 只能表示一个字符,但一个中文至少占用两个字符;
%f 浮点数;%.2f表示保留两位小数;默认六位小数;
%o 以不带符号的八进制输出
%x 以不带符号的十六进制输出
%e 以标准指数形式输出单、双精度数,数字部分小数位为6位
- scanf
阻塞式函数,不输入不向下执行;
要对变量进行赋值,须使用地址和占位符;如:int a;scanf(“%d”,&a);
&a表示变量a的地址;
scanf(“%d-%d”,&a,&b);则输入也须是a-b的形式;
- 数据类型
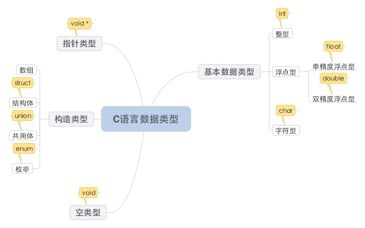 数据类型
数据类型
结构体,类似class ;共用体很少使用;
int 整型 2个字节;
float 单精度浮点型 4个字节
double 双精度浮点型 8个字节
char 字符型 1个字节,同java,只能存储一个字符(不能是中文,同java);
变量:若未初始化会自动赋值(全局变量会为0(int),但局部变量可能是一个随机数,必须初始化后再使用,更安全);
类型修饰符:
short 短型;short int =1;限制取值范围;
long长型;扩展int的取值范围;long a=1;等同于 long int a=1;(C中无long型,long只是一个修饰符)
signed 有符号型;signed int a=1;等同于int a=1;可为正数也可为负;
unsigned 无符号型;只能为正数或0;
可同时使用 unsigned long int a=5;
[不同的编译器,取值范围不同;]
基本语句(同java)
基本运算(同java)
但由于C没有boolean故没有true和false;用1和0来表示true和false;
如:5>4 —> 1; 5<4 —>0;
** 在if语句中,所有非0(包括负数)的值都为真(true)
[NOTE:像a==0这样的表达式,最好写成0==a。因为若误写成0=a,编译器会直接报错,而a=0是不会报错的。]
在C中,可以不保存关系去处的结果;如:a>10;a==0;
&& 与 || 同Java 也是阻断式的;
逗号表达式;
返回值为最后一个表达式的值;如:
int e=2,f=4;
int g = (++e,e*f); g—>12; 若int g = ++e,e*f;则相当于g=(++e),值为3;
+sizeof
用于得到数据占用的字节长度,返回值为size_t(即unsigned long,可直接使用int);使用 size_t size=sizeof(a);
地址
计算机中的内存是以字节为单位的存储空间。内存的每一个字节都有一个唯一的编号,这个编号就称为地址。
*凡存放在内存中的程序和数据都有一个地址,也就是说,一个函数也有自己的内存地址。
*当定义一个变量时,系统就分配一个带有唯一地址的存储单元来存储这个变量。变量存储单元的第一个字节的地址就是该变量的地址。
*获取地址: &a;
数组
只能是int a[5];的形式(int[5] a;int[] b;int a[];int i=0;int a[i]均错误。int)
[]里面的个数必须是一个固定值,可以是常量(比如6、8)、常量表达式(比如3+4、5*7)。绝对不能使用变量或者变量表达式来表示元素个数,大多数情况下不要省略元素个数(当数组作为函数的形参和数组初始化时除外)
一维数组
定义数组时,系统将按照数组类型和个数分配一段连续的存储空间来存储数组元素,如int a[3]占据了连续的6字节存储空间(在16位编译器环境下,一个int类型占用2个字节)。要注意的是,数组名代表着整个数组的地址,也就是数组的起始地址。
其实a不算是变量,是个常量,它代表着数组的地址,不能对其赋值[int a[2];a={1,2};//是错误的]。]
数组a的地址是ffc1,a[0]的地址是ffc1,a[1]的地址是ffc3,a[2]的地址是ffc5。因此a == &a[0],即第一个元素的地址就是整个数组的地址
[数组名代表的就是数组的地址,也就是第0个元素的地址;]
初始化:int a[2]={1,2}(可省略size和和第一个元素后的元素);或 a[0]=1,a[1]=[2];
一维数组的元素作为函数实参,与同类型的简单变量作为实参一样,是单向的值传递,即数组元素的值传给形参,形参的改变不影响实参;
但是,如果一维数组的名字作为函数实参,传递的是整个数组,即形参数组和实参数组完全等同,是存放在同一存储空间的同一个数组。这样形参数组修改时,实参数组也同时被修改了。形参数组的元素个数可以省略。
[** 此处同java **]
二维数组
是一个特殊的一维数组,元素是一个一维数组;存放的顺序是一行行的存;
a[0]、a[1]也是数组,是一维数组,而且a[0]、a[1]就是数组名,因此a[0]、a[1]就代表着这个一维数组的地址;a = a[0][0];
[若只初始化了部分元素,可省略行数,但不能省略列数;]
字符串
没有String类型,使用字符数组来存储字符串;
字符串可以看做是一个特殊的字符数组,为了跟普通的字符数组区分开来,应该在字符串的尾部添加了一个结束标志’\0’。’\0'是一个ASCII码值为0的字符,是一个空操作符,表示什么也不干。所以采用字符数组存放字符串,赋值时应包含结束标志'\0'。
[NOTE:尾部有个’\0’,如果没有这个结束标记,说明这个字符数组存储的并不是字符串]
初始化:一般使用 char s[] =“mj”;会自动在末尾添加’\0’;
若使用char s[]={‘m’,’j’,’\0’};一定要加’\0’;否则会造成内存地址错误,内存泄露,读到脏数据;
== puts(s)== 输出字符串:会从起始地址一直打印到’\0’止,故若定义时没有’\0’,则很可能会出现内存泄露(很危险)
== gets(s)== 输入字符串:从s的地址开始逐个赋值用户输入的字符,并自动加上\0,故两个s一起打印,会读到其他数据(很危险),
(gets一次只能读取一个字符串,scanf则可以同时读取多个字符串;
gets可以读入包含空格、tab的字符串,直到遇到回车为止;scanf不能用来读取空格、tab
字符串数组
一维字符给存放一个字符串;
字符串处理函数
== putchar(‘A’)==:输出一个char字符;
== char c;c=getchar()==:输入一个char字符;
== strlen(s) ==:测量字符个数,但不包括\0;
== strcpy(s1,s2)==:将右边的s2字符串拷贝到字符数组s1中。从s1的首地址开始,逐个字符拷贝,直到拷贝到\0为止。当然,在s1的尾部肯定会保留一个\0。[原s1中的内容会被清掉]
== strcat(s1,s2)==:把s2拼接到s1的后面,从首地址开始到第一个’\0’就认为是字符串末尾,而不管后面是否还有内容如(char s[]={‘a’,’\0’,’b’})[但必须要保证s1有足够的长度来存储s2,否则会内存溢出。];
== strcmp(s1,s2)==:根据字符的ASCII码的大小来比较两个字符串的大小;大于为1,等于为0,小于为-1;
== strlwr(s)==:将字符串中的大写转成小写;
感谢李明杰老师@M了个J的讲解及时详细的课件(http://www.cnblogs.com/mjios)
博客地址:IOS基础学习之C(一)