有数据的地方就有表格。无论是异常值处理,清除缺省值,还是增删改查,无论是csv还是mysql等各种数据库,无不是以表格的形式存储数据。表格在数据中成为了一个绕不开的话题,因此专门处理数据的pandas库中出现DataFrame也就不显得奇怪了。
今天,给大家简单介绍一下DataFrame。
我们约定在程序开头的包引入是这种写法。
from pandas import DataFrame
我们先初始化一个表格,然后再对它的各种操作进行一系列讲解。构建DataFrame的方法有很多,最常见的就是利用NumPy数组组成的字典传入。如下。
data = {'姓名' : ['李大', '王二', '张三', '李四'], '薪酬' : [10000, 8000, 12000, 5000], '工作' : ['程序员', '程序员鼓励师', '产品经理', '运营']}
frame = DataFrame(data)
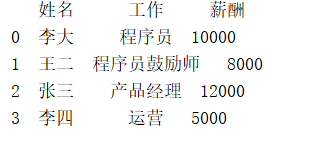
我们可以看到,姓名,薪酬,工作是作为列的,而自动生成的索引是作为行的。这是python中pandas约定俗称的格式。
我们可以对该表格,进行矩阵运算。比如矩阵转置。
frame = frame.T
然后我们会得到如下结果

这个操作非常简单,注意T要大写,而且非常有用。比如当我们得到一大堆已经存储在数据库中数据,我们想对它进行索引。当我们不想使用默认的数字来当作索引时(比如上课老师点名,你觉得是点学号好,还是点姓名好呢?),我们可以通过转置来改变索引。
我们之前使用NumPy数组传入的,如果我们传入列在数据中找不到,表格就会自动生成NA值,表示这里为空。
data = {'姓名' : ['李大', '王二', '张三', '李四'], '薪酬' : [10000, 8000, 12000, 5000], '工作' : ['程序员', '程序员鼓励师', '产品经理', '运营']}
frame = DataFrame(data, columns= ['姓名', '薪酬', '工作', '是否有女朋友'], index= [1, 2, 3, 4])

我们可以看到,在是否有女朋友那一栏全部自动生成了NaN, 表示这一列数据为空。这里我们也可以得到启发,就是表格的index(索引)也是可以改变的,不一定就非要是数字。比如。
data = {'姓名' : ['李大', '王二', '张三', '李四'], '薪酬' : [10000, 8000, 12000, 5000], '工作' : ['程序员', '程序员鼓励师', '产品经理', '运营']}
frame = DataFrame(data, columns= ['姓名', '薪酬', '工作', '是否有女朋友'], index= ['one', 'two', 'three', 'four'])

可以看到,索引变成了英文单词。接着来,我们知道,程序员一般没有女朋友,程序员鼓励师一般是女生也没有女朋友,但是产品经理,运营这种天天比较喜欢吹的人,往往就有女朋友(不公平啊)。我们如何更改表格数据让它更符合客观事实呢?
这就涉及到表格的查找了,表格的查找有很多,我把它分为位置查找和范围查找。
位置查找有三种方法,分别是函数ix、loc、iloc,ix现在已经不推荐使用了。我们主要来介绍后面两种函数。它俩的区别用一句话来概括就是,当用行号来索引时用iloc,当用行名,标签来索引的时候用iloc,而且是只能这么用。做一下对比你们就明白了。
data = {'姓名' : ['李大', '王二', '张三', '李四'], '薪酬' : [10000, 8000, 12000, 5000], '工作' : ['程序员', '程序员鼓励师', '产品经理', '运营']}
frame = DataFrame(data, columns= ['姓名', '薪酬', '工作', '是否有女朋友'], index= [1, 2, 3, 4])
#frame = DataFrame(data, columns= [1, 2, 3, 4], index= [1, 2, 3, 4])
frame = frame.iloc[2:3]
print(frame)

可当我们把索引代码稍微改一下,程序就会报错。
frame = frame.iloc[2:3, '是否有女朋友']
这是因为我的行索引为数字,而列索引是字符串导致的。这时候如果想达到要求效果就应该用loc。
frame.loc[3:4, '是否有女朋友'] = '有'

我们发现社会对单身狗是比较鄙视,所以我们想把没有女朋友的这几行给删掉,其实也就是删除缺省值。如下。
print(frame.dropna())

讲完了位置查找的主要内容,接下来我们说一下范围查找。以上面那个表格为例子,我们想找出工资不低于一万的人的资料如何做呢?如下。
print(frame[frame['薪酬'] >= 10000])

是不是特别的方便呢?感觉就像是在数据库中操作,而且比sql语句更加简洁。所以用python处理小型数据量的工程,其实用excel的csv格式进行存储,增删改查是比数据库要方便,轻量级且简单的。
以上,是DataFrame最简单的应用,看完博客后读者可以自行发挥想象,组合出不同的使用方式。但是万变不离其宗,彻底理解最基础的操作,才是最重要的,而且最基础的操作其实都很简单。
接下来我们介绍NumPy与Pandas中都有的一个定义,叫做广播。我们都知道,列表只可以和列表做运算,列表如果和整数运算就会报错。可是在NumPy、Pandas中就分别赋予了数组与表格对整数和一位数组的运算。如果需要更加形象的来表述何为广播。我觉得应该说,它赋予了数据形式可以与比其低一个维度的数据形式运算的能力。
test1 = np.array(range(1, 10))
print(test1)
print(test1 - 1)

数组里每个元素都比原来少了1,这个功能的出现使得python更加灵活。其实我对它的最大感悟就是,它使得我在for循环时解决索引溢出问题方便多了。
表格也可以进行广播操作。
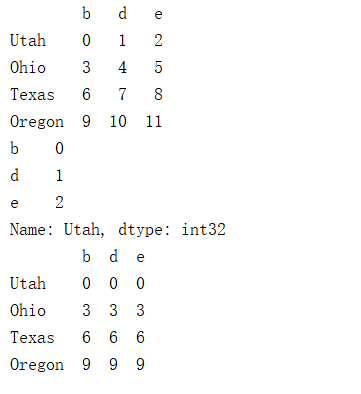
frame = DataFrame(np.arange(12).reshape((4,3)), columns=list('bde'), index=['Utah', 'Ohio', 'Texas', 'Oregon'])
print(frame)
series = frame.loc['Utah']
print(series)
print(frame - series)
最后给大家介绍一个表格绘图功能。我们知道,matplotlib是python中最常用的画图功能,不过它有它自身的缺陷,它像是一个组装工具箱一样,标题,标签,横纵坐标等等,需要一个一个组装上去,最后形成一张图片。而且当一张图上需要表现多组数据,比如呈现多条折线的时候,matplotlib使用起来十分麻烦。但是pandas可以几行代码非常简单的实现这些功能。
import numpy as np
from matplotlib import pyplot as plt
from pandas import DataFrame
import pandas as pd
df = DataFrame(np.random.randn(10,4).cumsum(0),
columns=['A', 'B', 'C', 'D'],
index=np.arange(0,100,10))
df.plot()
plt.show()
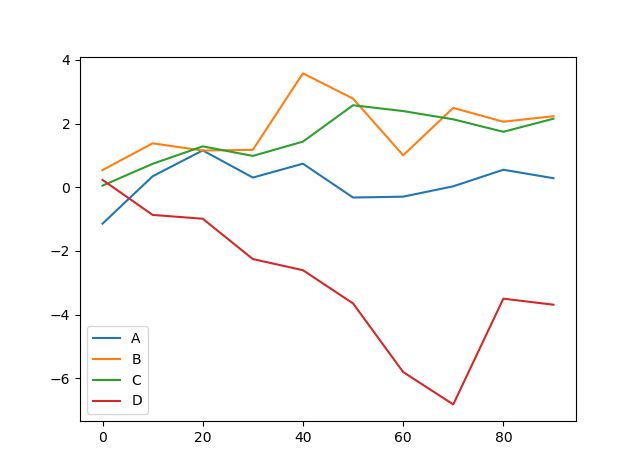
可以看到,列名可以当作标签,自动选择颜色,直接用表格plot,这里其实是用表格来调用了matplotlib的api。可以实现一图展现多行数据进行对比的功能。