原理
- 通过选择最好的特征来划分数据集,对数据子集继续划分,直到数据子集中是相同的类别;划分数据集的特征可以通过计算信息增益的方法来选择。
优点
- 计算复杂度不高,输出结果容易理解,可以处理不相关特征数据。
缺点
- 可能会产生过度匹配问题。
适用数据类型:
- 标称型和数值型数据。
import math
#计算熵
def calEntropy(data_2d_array):
classDict = {}
for item in data_2d_array:
classDiff = item[-1]
classDict[classDiff] = classDict.get(classDiff,0) + 1
#计算熵的公式
h = 0.0
for key in classDict:
prob = classDict[key] / len(data_2d_array) #计算概率
h -= prob * math.log(prob,2) #计算熵
return h
calEntropy([[1,1,'yes'],[1,0,'no'],[1,1,'yes'],[0,1,'no'],[0,1,'no']])
0.9709505944546686
#划分数据集
def splitData(data_2d_array, feature, value):
restData = []
for diff in data_2d_array:
if diff[feature] == value:
restList = diff[:feature]
restList.extend(diff[feature+1:])
restData.append(restList)
return restData
data_2d_array=[[1,1,'yes'],[1,0,'no'],[1,1,'yes'],[0,1,'no'],[0,1,'no']]
splitData(data_2d_array,0,1)
[[1, 'yes'], [0, 'no'], [1, 'yes']]
def chooseBestFeatureToSplit(data_2d_array):
bestInfoGain = 0.0
bestFeatureIndex = -1
numFeature = len(data_2d_array[0])-1
beforeEntropy = calEntropy(data_2d_array)
for i in range(numFeature):
uniqValue = set([x[i] for x in data_2d_array])
afterEntropy = 0
for val in uniqValue:
restData = splitData(data_2d_array,i,val)
subEntropy = calEntropy(restData)
power = len(restData) / len(data_2d_array)
afterEntropy += power*subEntropy #公式参考西瓜书P35
InfoGain = beforeEntropy - afterEntropy #afterEntropy越小,数据越有序,InfoGain越大
if InfoGain >= bestInfoGain:
bestInfoGain = InfoGain
bestFeatureIndex = i
return bestFeatureIndex
chooseBestFeatureToSplit(data_2d_array)
0
'''
构建决策树伪代码:
if 样本类别相同:
return 类别
if:遍历完所有特征:
return 投票结果
else:
选择最优特征
划分数据集
创建分支节点
for 每个数据集:
分支节点 += 递归构建决策树
return 分支节点
'''
#少数服从多数投票
def vote(classList):
classCount = {}
for i in classList:
classCount[i] += classCount.get(i,0)
sortClass = sorted(classCount.items(), key= lambda x: x[1])
return sortClass[0][-1]
#构建决策树
def createTree(data_2d_array,feature):
classList = [i[-1] for i in data_2d_array]
if classList.count(classList[0]) == len(data_2d_array):
return classList[0]
if len(data_2d_array[0]) == 1:
return vote(classList)
#选择最优特征
bestFeatureIndex = chooseBestFeatureToSplit(data_2d_array)
bestFeature = feature[bestFeatureIndex]
#创建分支节点
myTree = {feature[bestFeatureIndex]:{}}
del(feature[bestFeatureIndex])
#数据子集继续划分
uniFeatureValueSet = set([i[bestFeatureIndex] for i in data_2d_array])
for val in uniFeatureValueSet:
subFeature = feature[:]
subData = splitData(data_2d_array, bestFeatureIndex, val)
myTree[bestFeature][val] = createTree(subData,subFeature)
return myTree
data_2d_array=[[1,1,'yes'],[1,0,'no'],[1,1,'yes'],[0,1,'no'],[0,1,'no']]
createTree(data_2d_array,feature=['no surfacing','flippers'])
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
#使用文本注解绘制树节点
import matplotlib.pyplot as plt
decisionNode = dict(boxstyle='sawtooth',fc='0.8')
leafNode = dict(boxstyle='round4',fc='.8')
arrow_args = dict(arrowstyle='<-')
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy = parentPt, \
xycoords = 'axes fraction', xytext = centerPt, \
textcoords = 'axes fraction', va = "center", \
ha = "center", bbox = nodeType, arrowprops = arrow_args)
def createPlot():
fig = plt.figure(facecolor='white')
# fig.clf()
createPlot.ax1 = plt.subplot(111, frameon = False) #frameon 是否绘制矩形贴图
plotNode('decisionNode', (0.5, 0.1), (0.1, 0.5), decisionNode)
plotNode('leafNode', (0.8, 0.1), (0.3, 0.8), leafNode)
plt.show()
createPlot()
output_5_0.png
#获取叶子节点个数和树的深度
def getNumLeafs(myTree):
firstNode = list(myTree.keys())[0]
secondDict = myTree[firstNode]
numLeafs = 0
for key in secondDict:
if type(secondDict[key]).__name__ == 'dict':
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstNode = list(myTree.keys())[0]
secondDict = myTree[firstNode]
#遍历所有节点来计算这个节点的深度,找到最深那条分支,装进袋子里(装袋法)。
for key in secondDict:
if type(secondDict[key]).__name__ == 'dict':
#本节点深度 = 1(本节点)+ 子树深度
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
'''自己做的错误解法:
def getTreeDepth(myTree):
numDepth = 0
firstNode = list(myTree.keys())[0]
secondDict = myTree[firstNode]
for key in secondDict:
if type(secondDict[key]).__name__ == 'dict':
numDepth += 1
else:
numDepth = 1
return numDepth
'''
myTree = {'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1:{'flippers': {0: 'no', 1: 'yes'}}}}}}
print('number of leafs is: %d'%getNumLeafs(myTree))
print('depth of tree is: %d' %getTreeDepth(myTree))
number of leafs is: 4
depth of tree is: 3
#使用文本注解绘制树节点
import matplotlib.pyplot as plt
decisionNode = dict(boxstyle='sawtooth',fc='0.8')
leafNode = dict(boxstyle='round4',fc='.8')
arrow_args = dict(arrowstyle='<-')
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlotTree.ax1.annotate(nodeTxt, xy = parentPt, \
xycoords = 'axes fraction', xytext = centerPt, \
textcoords = 'axes fraction', va = "center", \
ha = "center", bbox = nodeType, arrowprops = arrow_args)
#获取叶子节点个数和树的深度
def getNumLeafs(myTree):
firstNode = list(myTree.keys())[0]
secondDict = myTree[firstNode]
numLeafs = 0
for key in secondDict:
if type(secondDict[key]).__name__ == 'dict':
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstNode = list(myTree.keys())[0]
secondDict = myTree[firstNode]
#遍历所有节点来计算这个节点的深度,找到最深那条分支,装进袋子里(装袋法)。
for key in secondDict:
if type(secondDict[key]).__name__ == 'dict':
#本节点深度 = 1(本节点)+ 子树深度
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
def plotMidText(centerPt, parentPt, txtString):
xMid = centerPt[0] + (parentPt[0] - centerPt[0])/2
yMid = centerPt[1] + (parentPt[1] - centerPt[1])/2
createPlotTree.ax1.text(xMid,yMid,txtString)
def plotTree(myTree, parentPt, nodeTxt):
numLeafs = getNumLeafs(myTree)
depth = getTreeDepth(myTree)
firstNode = list(myTree.keys())[0]
centerPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW,plotTree.yOff)
plotMidText(centerPt, parentPt,nodeTxt)
plotNode(firstNode, centerPt, parentPt,decisionNode)
secondDict = myTree[firstNode]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict:
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key], centerPt, str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
plotNode(secondDict[key],(plotTree.xOff, plotTree.yOff),centerPt,leafNode)
plotMidText((plotTree.xOff,plotTree.yOff),centerPt,str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
def createPlotTree(inTree):
fig = plt.figure(facecolor='white')
axprops = dict(xticks=[],yticks=[])
createPlotTree.ax1 = plt.subplot(frameon=False,**axprops)
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -.5 / plotTree.totalW
plotTree.yOff = 1.0
plotTree(inTree,(.5,1.0),'')
plt.show()
myTree = {'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1:{'flippers': {0: 'no', 1: 'yes'}}}}}}
createPlotTree(myTree)
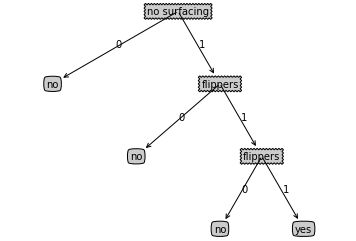
output_7_0.png
myTree = {'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1:'yes'}}}}
featureName = ['no surfacing','flippers']
testVector = [1,1]
#分类
def classify(myTree, featureName, testVector):
firstNode = list(myTree.keys())[0]
#找到第一个特征所对应在testVector的值
indexOfFirstNode = featureName.index(firstNode)
valOfFirstNodeInTestVec = testVector[indexOfFirstNode]
secondDict = myTree[firstNode]
for val in secondDict: #遍历子树的key,其实就是该节点的value
if valOfFirstNodeInTestVec == val:
if type(secondDict[val]).__name__ == 'dict':
res = classify(secondDict[val],featureName, testVector)
else:
res = secondDict[val]
return res
classify(myTree, featureName, testVector)
'yes'
#存储决策树
def dumpTree(myTree,filename):
import pickle
fw = open(filename,'wb') #以二进制的方式打开
pickle.dump(myTree,fw) #pickle存储方式默认是二进制方式
fw.close()
def loadTree(filename):
import pickle
fr = open(filename,'rb')
tree = pickle.load(fr)
fr.close()
return tree
dumpTree(myTree,'classifierStorage.txt')
loadTree('classifierStorage.txt')
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
使用决策树预测隐形眼镜类型
def classifyLenses():
fr = open('../../Reference Code/Ch03/lenses.txt')
lenses = [line.strip().split('\t') for line in fr.readlines()]
feature = ['age','prescript','astigmatic','tearTate']
lenseTree = createTree(lenses,feature)
showTree = createPlotTree(lenseTree)
return showTree
classifyLenses()
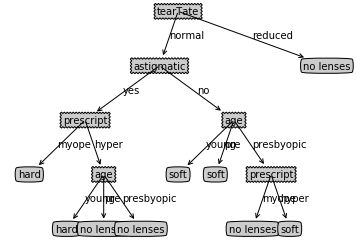
output_11_0.png