标签: 信息检索
一、准备阶段:
1. 购买阿里云服务器ECS(学生版)
使用mobaxterm工具设置session,通过密码连接云服务器。

aliyun.PNG
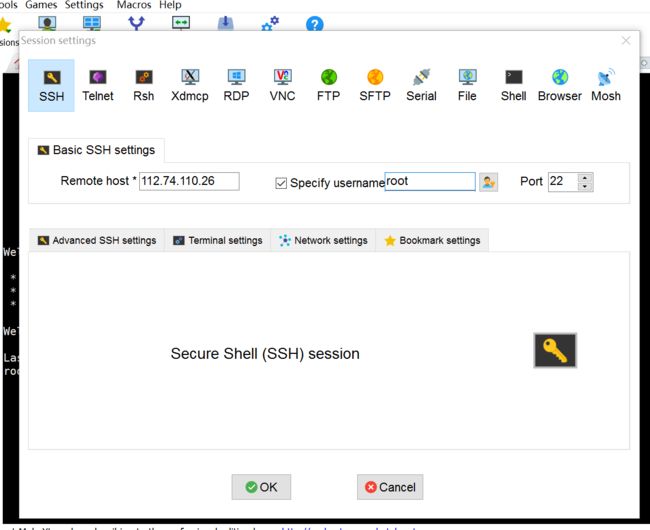
session1.PNG
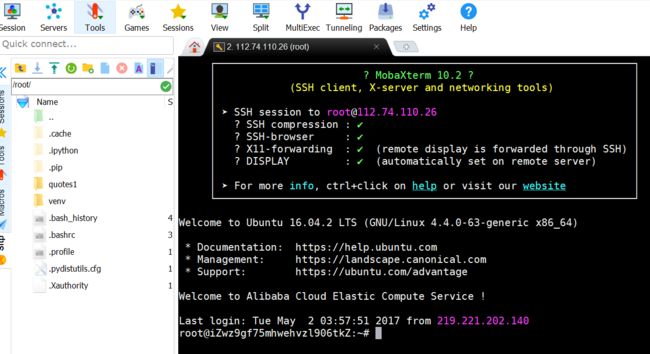
mobaxterm.PNG
2. 配置虚拟开发环境(virtualenv)
sudo pip install virtualenv
virtualenv --version
virtualenv venv
cd venv
ls
source bin/activate
3. 安装Scrapy和其依赖的包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple twisted
sudo apt-get install build-essential libssl-dev libffi-dev python-dev
pip install cryptography
pip install scrapy
二、采集阶段:
1. 创建一个Scrapy项目
使用mobaxterm、pycharm工具,采用阿里云ECS服务器。
scrapy startproject quotes
2. 编写spider,爬行网站,抽取所需数据
2.1 使用Google chrome开发者工具,观察网页结构。
![Uploading chrome_558181.PNG . . .]
2.2 编写初始quotes_spider.py
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/'
]
for url in urls:
yield scrapy.Request(url= urls, callback=self.parse)
def parse(self, response):
page = response.url.split('/')[-2]
fileName = 'quotes-%s.html' % page
#打开文件
with open(fileName, 'wb') as f:
f.write(response.body)
self.log('saved file %s ' % fileName)
3. 使用命令行导出采集结果
3.1在项目根目录下输入命令。
scrapy crawl quotes
3.2 使用Scrapy Shell 选择器提取数据。
scrapy shell 'http://quotes.toscrape.com/page/1/'
4. 修改spider,遍历超链接
4.1 使用递归、循环等,修改quotes_spider.py。
import scrapy
class QuotesSpider(scrapy.Spider):
name="quotes"
def start_requests(self):
urls=[
'http://quotes.toscrape.com/page/1',
'http://quotes.toscrape.com/page/2',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
for quote in response.css('div.quote'):
yield{
'text':
quote.css('span.text::text').extract_first(),
'author':
quote.css('small.author::text').extract_first(),
'tags': quote.css('div.tags a.tag::text').extract(),
}
next_page = response.css('li.next a::attr(href)').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
4.2 存储quotes数据。
scrapy crawl quotes-o quotes.json
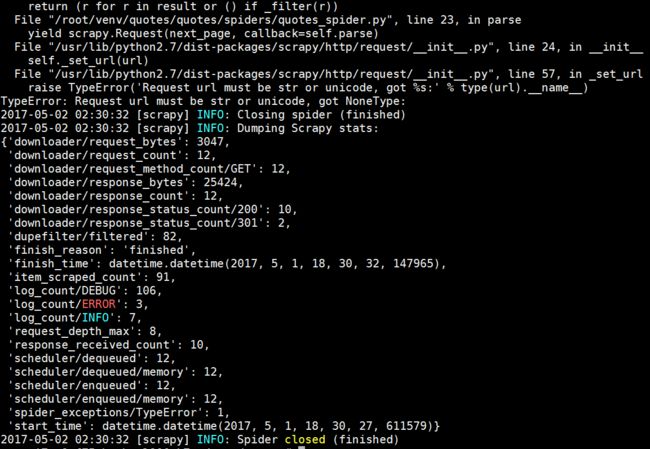
18.PNG

16.PNG
4.3 使用Google refine工具,阅读分析quote.json文件。

17.PNG
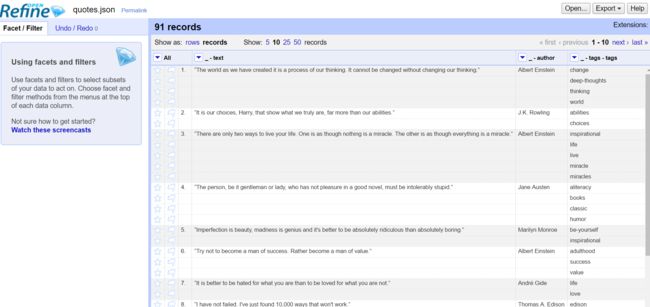
21.PNG
4.4 使用递归、循环等,创建author_spiders.py。
import scrapy
class AuthorSpider(scrapy.Spider):
name='authors'
start_urls=['http://quotes.toscrape.com/']
def parse(self,response):
for href in response.css('.author + a::attr(href)').extract():
yield scrapy.Request(response.urljoin(href),
callback=self.parse_author)
next_page= response.css('li.next a::attr(href)').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page,callback=self.parse)
def parse_author(self, response):
def extract_with_css(query):
return response.css(query).extract_first().strip()
yield {
'name': extract_with_css('h3.authortitle::text'),
'birthday': extract_width_xpath('//span[@class="author-born-date"]/text()'),
'location': extract_width_xpath('//span[@class="author-born-location"]/text()'),
}
4.5 存储authors数据。

22.PNG
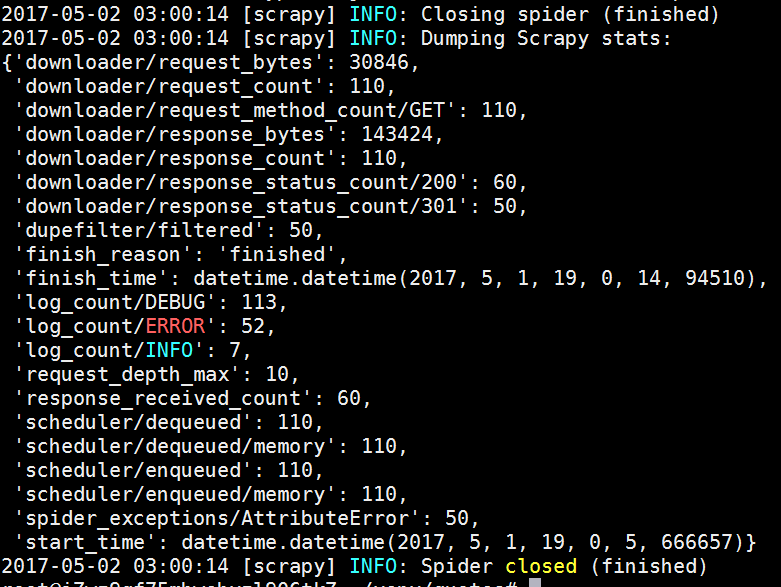
23.PNG

24.PNG
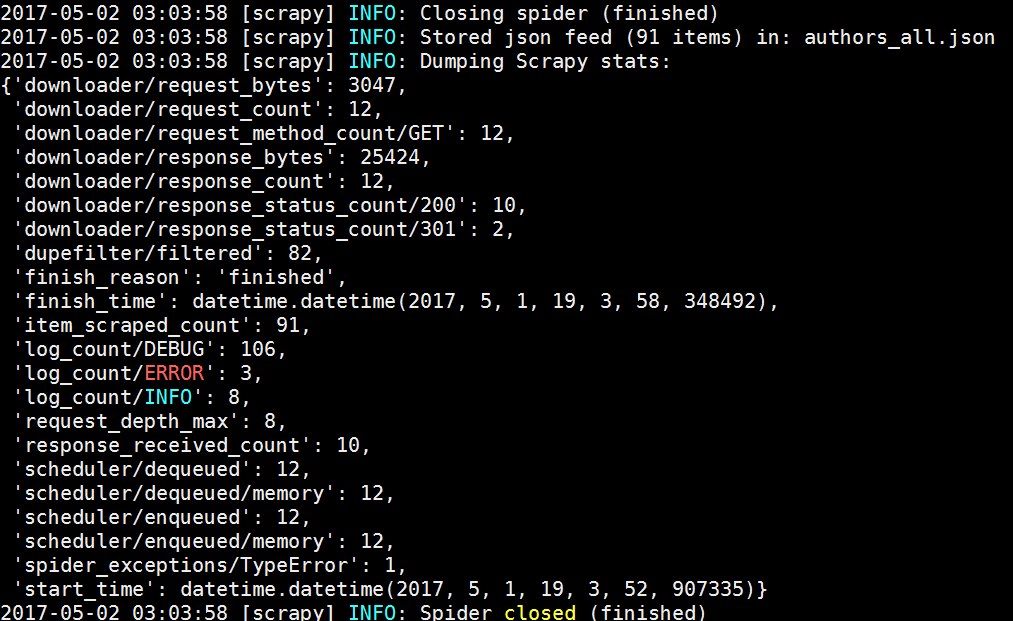
25.PNG
5. 使用spider参数
5.1 观察网页结构,创建quotesremen_spider.py。
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes_tag'
def start_requests(self):
url = 'http://quotes.toscrape.com/'
tag = getattr(self, 'tag', None)
if tag is not None:
url = url + 'tag/' + tag
yield scrapy.Request(url, self.parse)
def parse(self, response):
for quote in response.xpath('//div[@class="quote"]'):
yield {
'text': quote.xpath('span[@class="text"]/text()').extract_first(),
'author': quote.xpath('span/small[@class="author"]/text()').extract_first(),
}
next_page = response.xpath('//li[@class="next"]/a/@href').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(url= next_page, callback= self.parse)
5.2 使用Spider参数,依次抓取并存储热门标签的名人名言(以friendship为例)。
scrapy crawl quotes_tag -o quotes-friendship.json -a tag=friendship

zong.PNG

friendship.PNG
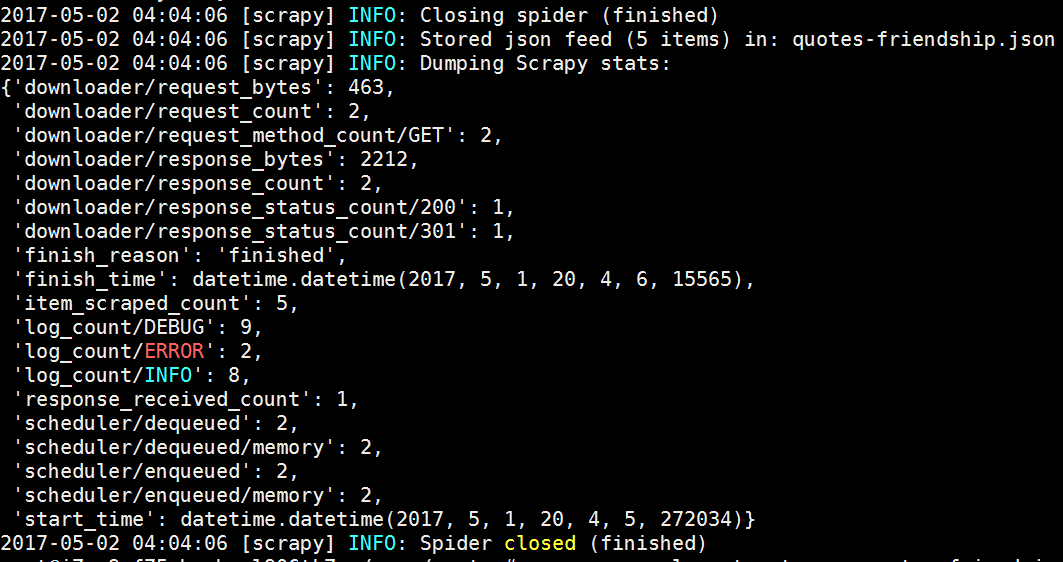
friendship1.PNG

inspirationalq.PNG

life.PNG
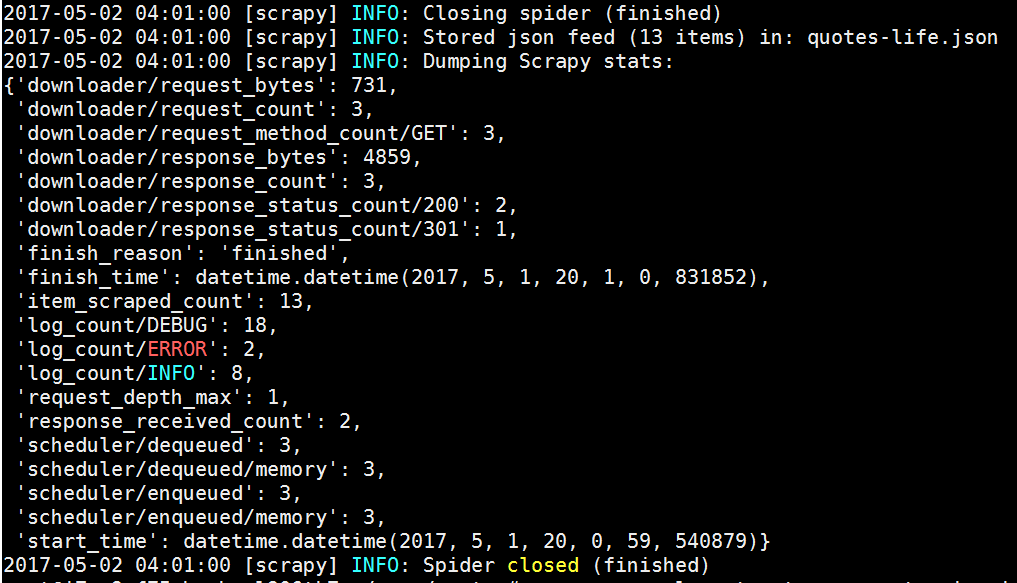
life1.PNG

love.PNG
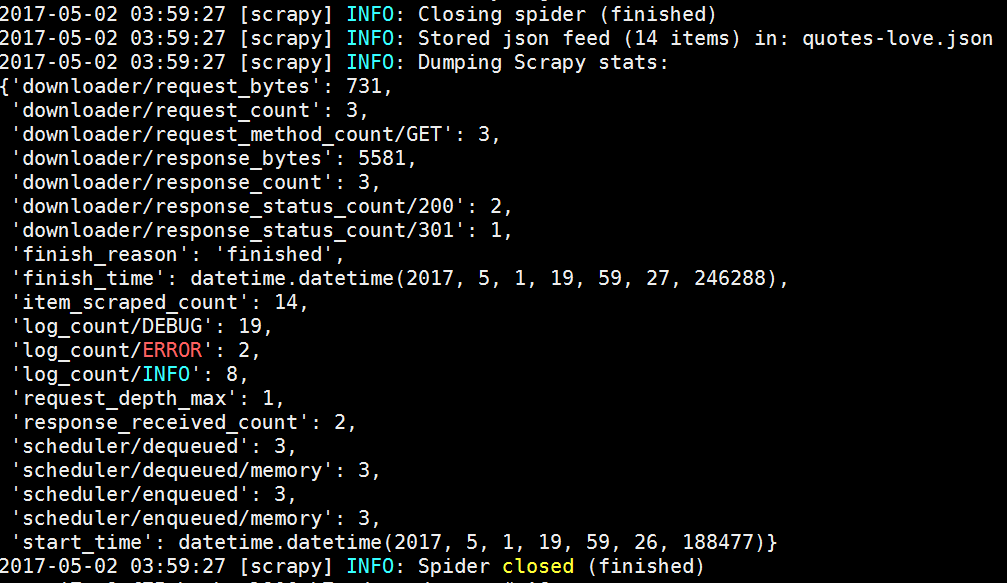
love1.PNG

reading.PNG

reading1.PNG

simile.PNG

simile1.PNG

truth.PNG

truth1.PNG

books.PNG
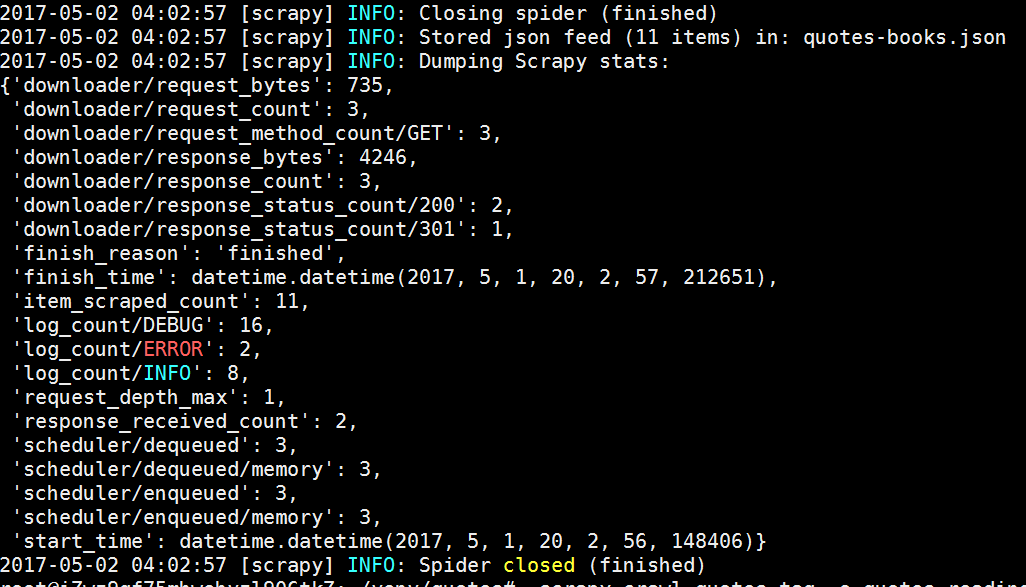
books1.PNG

friend.PNG
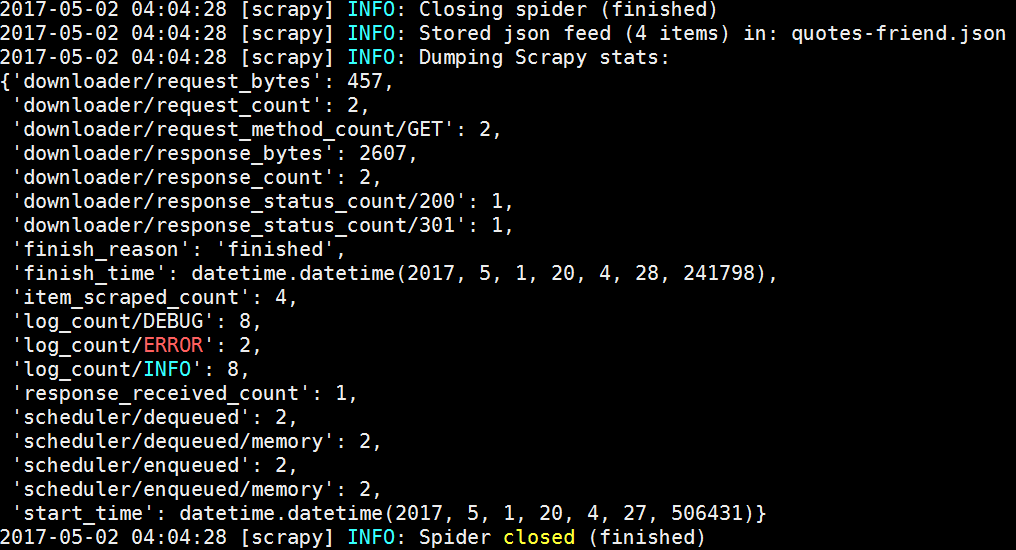
friend1.PNG

humor.PNG
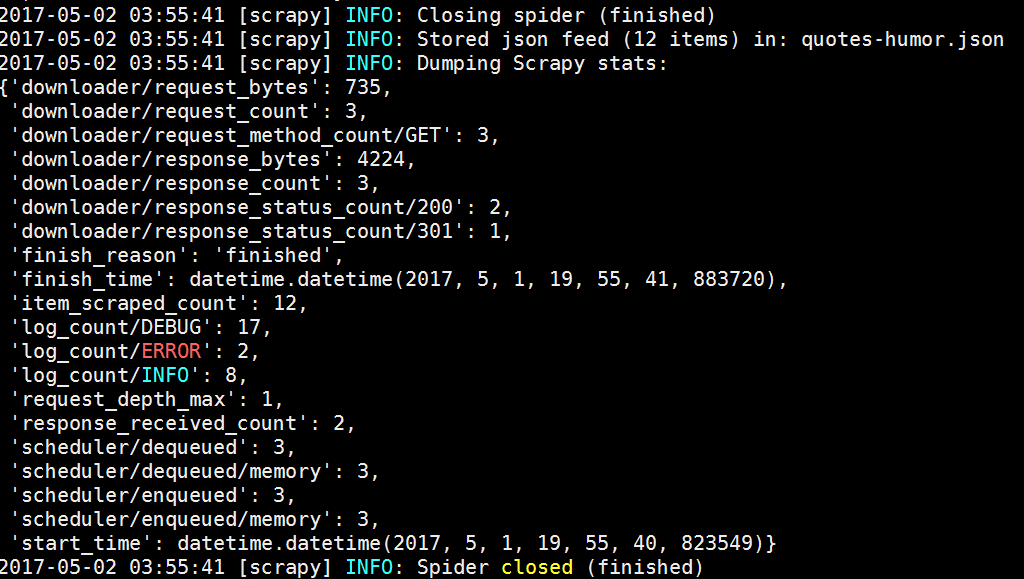
humor1.PNG

inspirational.PNG
6. 将采集到的数据JSON文件转换成XML文件
6.1 使用Google refine工具,将采集的JSON文件export成HTML文件。
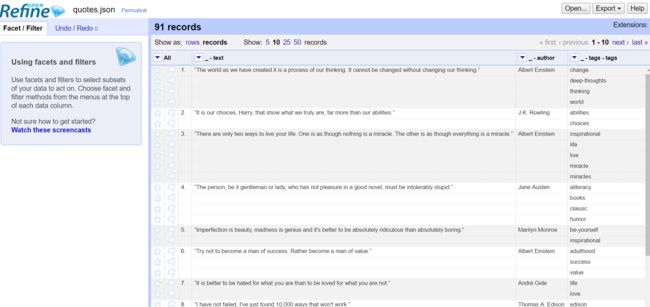
21.PNG
6.2 使用sublime工具,打开上一步导出的HTML文件,另存为XML文件(节选部分代码如下),用Firefox测试。
quotes json
_ - text _ - author _ - tags - tags “The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” Albert Einstein change deep-thoughts thinking world
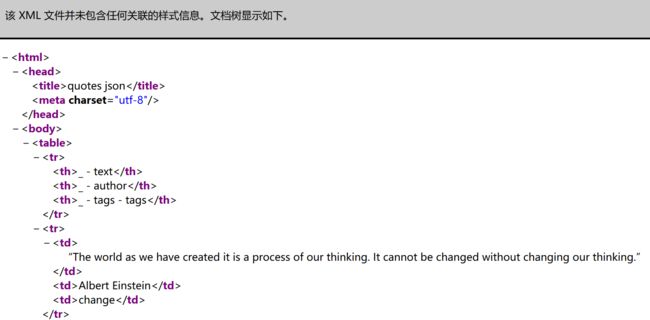
27.PNG
阅读材料:
Scrapy官方文档