1 梯度
1.1 定义
梯度:是一个矢量,其方向上的方向导数最大,其大小正好是此最大方向导数。
关于梯度的更多介绍请看:如何直观形象的理解方向导数与梯度以及它们之间的关系?
1.2 计算
一个标量函数φ的梯度记为:
在三维直角坐标系中表示为:

1.3 范例

2 梯度下降法
2.1 定义
梯度下降法(英语:Gradient descent)是一个一阶最优化算法,通常也称为最速下降法。 要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。如果相反地向梯度正方向迭代进行搜索,则会接近函数的局部极大值点;这个过程则被称为梯度上升法。
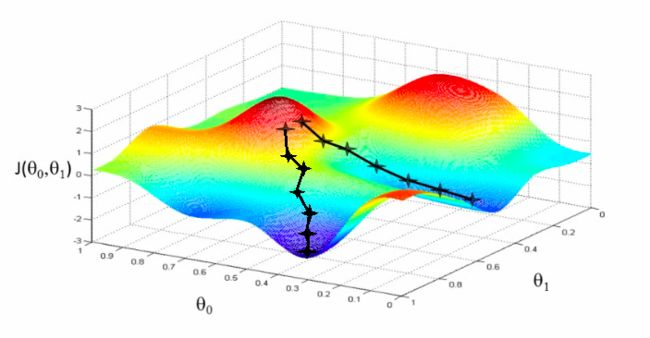
2.2 描述
梯度下降法基于以下观察的:如果实值函数F(x)在a处可微且有定义,那么函数F(x)在a点沿着梯度相反的方向-▽F(a)下降最快。
因而,假设
对于γ>0为一个够小数值时成立,那么F(a)≥F(b)。
考虑到这一点,我们可以从函数F的局部极小值的初始估计x 0出发,考虑到如下序列x 0,x 1,x 2,....使得:
因此可以得到
如果顺利的话,序列(x n)收敛到期望的极值。注意每次迭代的γ可以改变。
下面的这张图片展示了这一过程,这里假设F定义在平面上,并且函数图像是一个碗形。蓝色的曲线是等高线,即函数F为常数的集合构成的曲线。红色的箭头指向该点梯度的反方向。(一点处的梯度方向与通过该点的等高线垂直)。沿着梯度下降方向,将最终到达碗底,即函数F值最小的点。

2.3 实例
梯度下降法处理一些复杂的非线性函数会出现问题,例如Rosenbrock函数
其最小值在(x,y)=(1,1)处,数值为f(x,y)=0。优化过程是之字形的向极小值点靠近,速度非常缓慢。

2.4 梯度下降算法的原理
-
微分
 单变量的微分
单变量的微分

-
什么是梯度
J(θ)是关于θ的一个函数,那么关于θ的梯度如下图所示:

其实是一个有方向的向量,代表函数变化最快的方向
- 如何使用梯度来更新参数
就如在很多文章中将梯度下降算法比喻为一个人以最快的速度下山,同时要保证速度最快,方向是正确的。如下图所示,θ0是最初的位置,θ1是我们要到达的第二个位置,计算公式为下图:

- 关于α
α为学习率即参数到达最优值过程的速度快慢,如Andrew Ng的Stanford公开课程所说,假如你从山峰的最高点根据梯度下降法寻找最优值,当你学习率过大,即下降的快,步子大,那么你很可能会在某一步跨过最优值,当你学习率过小时,每次下降一厘米,这将走到何年何月呀,用术语来说就是,长时间无法收敛。因此,学习率直接决定着学习算法的性能表现。https://blog.csdn.net/john_kai/article/details/72861731
如下图所示:

-
梯度计算实例

3代码实现
参考:
import numpy as np
# Size of the points dataset.
m = 20
# Points x-coordinate and dummy value (x0, x1).
X0 = np.ones((m, 1))
X1 = np.arange(1, m+1).reshape(m, 1)
X = np.hstack((X0, X1))
# Points y-coordinate
y = np.array([
3, 4, 5, 5, 2, 4, 7, 8, 11, 8, 12,
11, 13, 13, 16, 17, 18, 17, 19, 21
]).reshape(m, 1)
# The Learning Rate alpha.
alpha = 0.01
def error_function(theta, X, y):
'''Error function J definition.'''
diff = np.dot(X, theta) - y
return (1./2*m) * np.dot(np.transpose(diff), diff)
def gradient_function(theta, X, y):
'''Gradient of the function J definition.'''
diff = np.dot(X, theta) - y
return (1./m) * np.dot(np.transpose(X), diff)
def gradient_descent(X, y, alpha):
'''Perform gradient descent.'''
theta = np.array([1, 1]).reshape(2, 1)
gradient = gradient_function(theta, X, y)
while not np.all(np.absolute(gradient) <= 1e-5):
theta = theta - alpha * gradient
gradient = gradient_function(theta, X, y)
return theta
optimal = gradient_descent(X, y, alpha)
print('optimal:', optimal)
print('error function:', error_function(optimal, X, y)[0,0])
Gradient Descent lecture notes from UD262 Udacity Georgia Tech ML Course.
深入浅出--梯度下降法及其实现
这篇文章关于梯度下降算法讲解比较清洗和透彻,其中也有关于学习率的介绍梯度下降算法以及其Python实现
梯度下降法