01 获取分析
地铁信息获取从高德地图上获取。

上面主要获取城市的「id」「cityname」及「名称」。
用于拼接请求网址,进而获取地铁线路的具体信息。

找到请求信息,获取各个城市的地铁线路以及线路中站点详情。
02 数据获取
具体代码如下。
importjson
importrequests
frombs4importBeautifulSoup
headers = {'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
defget_message(ID, cityname, name):
"""
地铁线路信息获取
"""
url ='http://map.amap.com/service/subway?_1555502190153&srhdata='+ ID +'_drw_'+ cityname +'.json'
response = requests.get(url=url, headers=headers)
html = response.text
result = json.loads(html)
foriinresult['l']:
forjini['st']:
# 判断是否含有地铁分线
iflen(i['la']) >0:
print(name, i['ln'] +'('+ i['la'] +')', j['n'])
withopen('subway.csv','a+', encoding='gbk')asf:
f.write(name +','+ i['ln'] +'('+ i['la'] +')'+','+ j['n'] +'\n')
else:
print(name, i['ln'], j['n'])
withopen('subway.csv','a+', encoding='gbk')asf:
f.write(name +','+ i['ln'] +','+ j['n'] +'\n')
defget_city():
"""
城市信息获取
"""
url ='http://map.amap.com/subway/index.html?&1100'
response = requests.get(url=url, headers=headers)
html = response.text
# 编码
html = html.encode('ISO-8859-1')
html = html.decode('utf-8')
soup = BeautifulSoup(html,'lxml')
# 城市列表
res1 = soup.find_all(class_="city-list fl")[0]
res2 = soup.find_all(class_="more-city-list")[0]
foriinres1.find_all('a'):
# 城市ID值
ID = i['id']
# 城市拼音名
cityname = i['cityname']
# 城市名
name = i.get_text()
get_message(ID, cityname, name)
foriinres2.find_all('a'):
# 城市ID值
ID = i['id']
# 城市拼音名
cityname = i['cityname']
# 城市名
name = i.get_text()
get_message(ID, cityname, name)
if__name__ =='__main__':
get_city()
最后成功获取数据。
包含换乘站数据,一共3541个地铁站点。
03 数据可视化
先对数据进行清洗,去除重复的换乘站信息。
fromwordcloudimportWordCloud, ImageColorGenerator
frompyechartsimportLine, Bar
importmatplotlib.pyplotasplt
importpandasaspd
importnumpyasnp
importjieba
# 设置列名与数据对齐
pd.set_option('display.unicode.ambiguous_as_wide',True)
pd.set_option('display.unicode.east_asian_width',True)
# 显示10行
pd.set_option('display.max_rows',10)
# 读取数据
df = pd.read_csv('subway.csv', header=None, names=['city','line','station'], encoding='gbk')
# 各个城市地铁线路情况
df_line = df.groupby(['city','line']).count().reset_index()
print(df_line)
通过城市及地铁线路进行分组,得到全国地铁线路总数。

一共183条地铁线路。
defcreate_map(df):
# 绘制地图
value = [iforiindf['line']]
attr = [iforiindf['city']]
geo = Geo("已开通地铁城市分布情况", title_pos='center', title_top='0', width=800, height=400, title_color="#fff", background_color="#404a59", )
geo.add("", attr, value, is_visualmap=True, visual_range=[0,25], visual_text_color="#fff", symbol_size=15)
geo.render("已开通地铁城市分布情况.html")
defcreate_line(df):
"""
生成城市地铁线路数量分布情况
"""
title_len = df['line']
bins = [0,5,10,15,20,25]
level = ['0-5','5-10','10-15','15-20','20以上']
len_stage = pd.cut(title_len, bins=bins, labels=level).value_counts().sort_index()
# 生成柱状图
attr = len_stage.index
v1 = len_stage.values
bar = Bar("各城市地铁线路数量分布", title_pos='center', title_top='18', width=800, height=400)
bar.add("", attr, v1, is_stack=True, is_label_show=True)
bar.render("各城市地铁线路数量分布.html")
# 各个城市地铁线路数
df_city = df_line.groupby(['city']).count().reset_index().sort_values(by='line', ascending=False)
print(df_city)
create_map(df_city)
create_line(df_city)
已经开通地铁的城市数据,还有各个城市的地铁线路数。

一共32个城市开通地铁,大部分都是省会城市,还有个别经济实力强的城市。其中北京、上海线路已经超过了20条。
线路数量分布情况。

可以看到大部分还是在「0-5」这个阶段的,当然最少为1条线。
# 哪个城市哪条线路地铁站最多
print(df_line.sort_values(by='station', ascending=False))
探索一下哪个城市哪条线路地铁站最多。
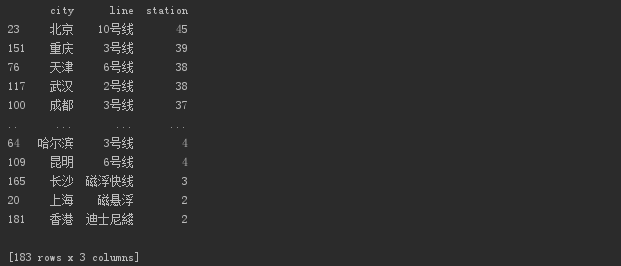
北京10号线第一,重庆3号线第二。

还是蛮怀念北京1张票,2块钱地铁随便做的时候。
可惜好日子一去不复返了。
去除重复换乘站数据。
# 去除重复换乘站的地铁数据
df_station = df.groupby(['city','station']).count().reset_index()
print(df_station)
一共包含3034个地铁站,相较新周刊中3447个地铁站数据,减少了近400个地铁站。

接下来看一下哪个城市地铁站最多。
# 统计每个城市包含地铁站数(已去除重复换乘站)
print(df_station.groupby(['city']).count().reset_index().sort_values(by='station', ascending=False))
32个城市,上海第一,北京第二。没想到的是,武汉居然有那么多地铁站。

现在来实现一下新周刊中的操作,生成地铁名词云。
defcreate_wordcloud(df):
"""
生成地铁名词云
"""
# 分词
text =''
forlineindf['station']:
text +=' '.join(jieba.cut(line, cut_all=False))
text +=' '
backgroud_Image = plt.imread('rocket.jpg')
wc = WordCloud(
background_color='white',
mask=backgroud_Image,
font_path='C:\Windows\Fonts\华康俪金黑W8.TTF',
max_words=1000,
max_font_size=150,
min_font_size=15,
prefer_horizontal=1,
random_state=50,
)
wc.generate_from_text(text)
img_colors = ImageColorGenerator(backgroud_Image)
wc.recolor(color_func=img_colors)
# 看看词频高的有哪些
process_word = WordCloud.process_text(wc, text)
sort = sorted(process_word.items(), key=lambdae: e[1], reverse=True)
print(sort[:50])
plt.imshow(wc)
plt.axis('off')
wc.to_file("地铁名词云.jpg")
print('生成词云成功!')
create_wordcloud(df_station)
词云图如下。

广场、大道、公园占了前三,和新周刊的图片一样,说明分析有效。
words = []
forlineindf['station']:
foriinline:
# 将字符串输出一个个中文
words.append(i)
defall_np(arr):
"""
统计单字频率
"""
arr = np.array(arr)
key = np.unique(arr)
result = {}
forkinkey:
mask = (arr == k)
arr_new = arr[mask]
v = arr_new.size
result[k] = v
returnresult
defcreate_word(word_message):
"""
生成柱状图
"""
attr = [j[0]forjinword_message]
v1 = [j[1]forjinword_message]
bar = Bar("中国地铁站最爱用的字", title_pos='center', title_top='18', width=800, height=400)
bar.add("", attr, v1, is_stack=True, is_label_show=True)
bar.render("中国地铁站最爱用的字.html")
word = all_np(words)
word_message = sorted(word.items(), key=lambdax: x[1], reverse=True)[:10]
create_word(word_message)
统计一下,大家最喜欢用什么字来命名地铁。

路最多,其中上海的占比很大。
不信往下看。
# 选取上海的地铁站
df1 = df_station[df_station['city'] =='上海']
print(df1)
统计上海所有的地铁站,一共345个。

选取包含路的地铁站。
# 选取上海地铁站名字包含路的数据
df2 = df1[df1['station'].str.contains('路')]
print(df2)
有210个,约占上海地铁的三分之二,路的七分之二。

看来上海对路是情有独钟的。
具体缘由这里就不解释了,详情见新周刊的推送,里面还是讲解蛮详细的。
武汉和重庆则是对家这个词特别喜欢。标志着那片土地开拓者们的籍贯与姓氏。
# 选取武汉的地铁站
df1 = df_station[df_station['city'] =='武汉']
print(df1)
# 选取武汉地铁站名字包含家的数据
df2 = df1[df1['station'].str.contains('家')]
print(df2)
# 选取重庆的地铁站
df1 = df_station[df_station['city'] =='重庆']
print(df1)
# 选取重庆地铁站名字包含家的数据
df2 = df1[df1['station'].str.contains('家')]
print(df2)
武汉共有17个,重庆共有20个。
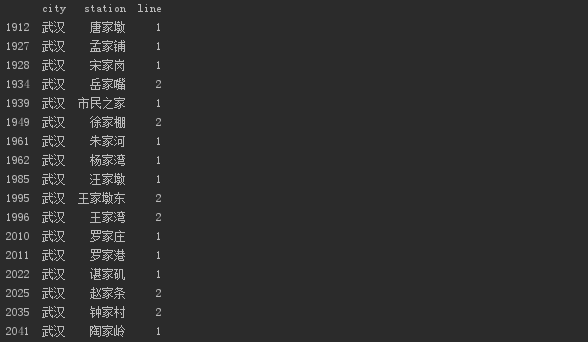

看完家之后,再来看一下名字包含门的地铁站。
defcreate_door(door):
"""
生成柱状图
"""
attr = [jforjindoor['city'][:3]]
v1 = [jforjindoor['line'][:3]]
bar = Bar("地铁站最爱用“门”命名的城市", title_pos='center', title_top='18', width=800, height=400)
bar.add("", attr, v1, is_stack=True, is_label_show=True, yaxis_max=40)
bar.render("地铁站最爱用门命名的城市.html")
# 选取地铁站名字包含门的数据
df1 = df_station[df_station['station'].str.contains('门')]
# 对数据进行分组计数
df2 = df1.groupby(['city']).count().reset_index().sort_values(by='line', ascending=False)
print(df2)
create_door(df2)
一共有21个城市,地铁站名包含门。
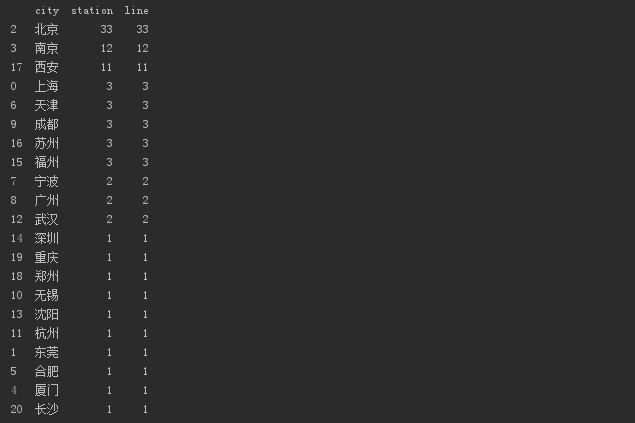
其中北京,南京,西安作为多朝古都,占去了大部分。

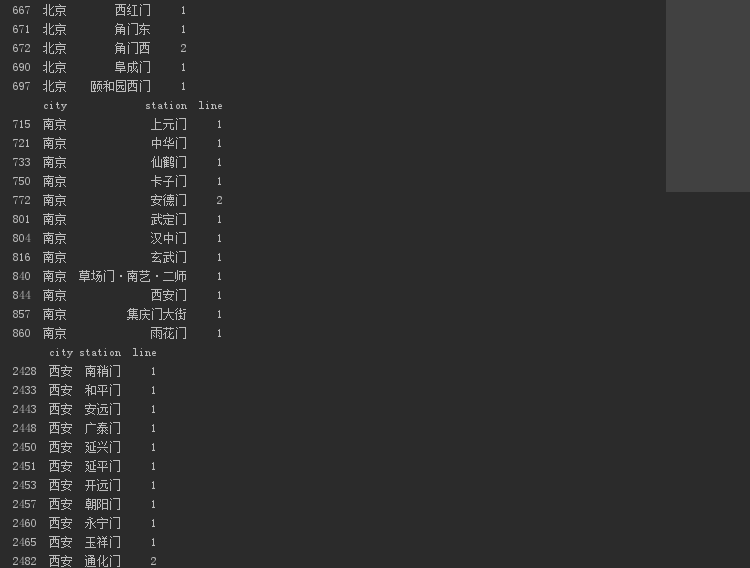
具体的地铁站名数据。
# 选取北京的地铁站
df1 = df_station[df_station['city'] =='北京']
# 选取北京地铁站名字包含门的数据
df2 = df1[df1['station'].str.contains('门')]
print(df2)
# 选取南京的地铁站
df1 = df_station[df_station['city'] =='南京']
# 选取南京地铁站名字包含门的数据
df2 = df1[df1['station'].str.contains('门')]
print(df2)
# 选取西安的地铁站
df1 = df_station[df_station['city'] =='西安']
# 选取西安地铁站名字包含门的数据
df2 = df1[df1['station'].str.contains('门')]
print(df2)
输出如下。

04 总结
可以说,一个小小的地铁名就是一座城市风貌的一部分。它反映着不同地方的水土,也承载着各个城市的文化和历史。
确实如此,靠山的城市地铁名多“山”,靠水的城市地铁名“含水量”则是杠杠的。
