基于上一章的内容,我们需要把key替换成hash值存储到b+tree中
首先要改变的就是set和get函数
template
int smallsql::getType()
{
return typeid(T) == typeid(int) ? 0 : 1;
}
template
void smallsql::set(const std::string& key, const T& value)
{
unsigned long iKey = HashString(key, 1);
int type = getType();
SqlData* pItem = static_cast*>(bplus_tree_get(m_pTree, iKey, type));
if (pItem == nullptr)
{
bplus_tree_put(m_pTree, iKey, nullptr, type);
pItem = new SqlData();
pItem->value = value;
bplus_tree_put(m_pTree, iKey, pItem, type);
}
else
{
pItem->value = value;
}
}
template
T smallsql::get(const std::string& key)
{
unsigned long iKey = HashString(key, 1);
int type = getType();
SqlData* pItem = static_cast*>(bplus_tree_get(m_pTree, iKey, type));
if (pItem == nullptr)
{
return T();
}
else
{
return pItem->value;
}
}
这两个函数首先都需要用HashString函数把key的内容转换成unsigned long类型的整数
然后存储到bplus_tree中,这些都在上一章里介绍过,需要需要看具体的实现附件有工程文件可以看
然后就是open和close函数,他们负责读取和保存,也需要修改
bool smallsql::open(const std::string& sqlPath)
{
FILE* fp = nullptr;
m_sqlPath = sqlPath;
fopen_s(&fp, sqlPath.c_str(), "r");
if (fp == nullptr)
{
return true;
}
while (!feof(fp))
{
unsigned long key = 0;
fread_s(&key, sizeof(unsigned long), sizeof(unsigned long), 1, fp);
if (key == 0)
{
continue;
}
int type = 0;
fread_s(&type, 1, 1, 1, fp);
if (type == 0)
{
int value = 0;
fread_s(&value, sizeof(int), sizeof(int), 1, fp);
SqlData* pItem = new SqlData();
pItem->value = value;
bplus_tree_put(m_pTree, key, pItem, type);
}
else if (type == 1)
{
int len = 0;
fread_s(&len, 1, 1, 1, fp);
char* value = new char[len + 1];
fread_s(value, len, len, 1, fp);
value[len] = 0;
SqlData* pItem = new SqlData();
pItem->value = std::string(value);
delete[] value;
bplus_tree_put(m_pTree, key, pItem, type);
}
}
fclose(fp);
return true;
}
void smallsql::close()
{
FILE* fp = nullptr;
fopen_s(&fp, m_sqlPath.c_str(), "w");
if (fp == nullptr)
{
return;
}
struct bplus_leaf *leaf = (struct bplus_leaf *)m_pTree->head[0];
if (leaf != NULL)
{
while (leaf != NULL)
{
for (int j = 0; j < leaf->entries; ++j)
{
fwrite(&leaf->key[j], sizeof(unsigned long), 1, fp);
fwrite(&leaf->datatype[j], 1, 1, fp);
if (leaf->datatype[j] == 0) // int
{
SqlData* pItem = static_cast*>(leaf->data[j]);
fwrite(&pItem->value, sizeof(int), 1, fp);
}
else if (leaf->datatype[j] == 1) // string
{
SqlData* pItem = static_cast*>(leaf->data[j]);
int len = pItem->value.length();
fwrite(&len, 1, 1, fp);
fwrite(pItem->value.c_str(), len, 1, fp);
}
}
leaf = leaf->next;
}
}
fclose(fp);
相对于上一个版本,稍微简单了点
另外b+tree的代码也需要修改(相对于上一章给出的b+tree实现版本https://github.com/begeekmyfriend/bplustree)
需要加入int datatype[MAX_ENTRIES];表示数据类型,另外key的类型从int->unsigned long,相应的函数也需要修改一下
总体来说大概就是加入b+tree和hash算法的实现代码bplustee.h/cpp和hash.h/cpp,另外小小的修改一下set和get函数,open和close函数
替换完成,赶紧看看1W个数据的测试时间,可以看出最慢的插入只需要0.07秒,而上一个版本需要7.6秒 快了100倍

这下我们可以试试10W数据了,10W数据只需要0.57秒,而上一个版本需要80秒,快了140倍
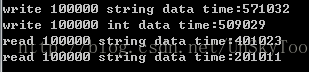
再来试试100W数据测试,最慢需要4.1秒

到这里,数据库基本能看了,至少效率比之前好多了接下来还有不少需要优化的地方