这一节开始我们介绍强化学习(reinforcement learning)。在监督学习中,对于一个给定的输入x,我们可以明确知道输出y。而在很多序列决策(sequential decision making)问题中,我们无法确切知道结果。比如我们造了一个机器人并教它如何走路,我们一开始是不知道给它下达哪个“正确”的指令才能让它走起来。
在强化学习问题中,我们会为算法定义一个奖励函数,这个函数用于给学习者一个反馈,然后根据反馈的好坏决定下一步动作。比如在机器人的例子中,我们会给机器人一个正向的奖励如果它向前走了一步,并且会给机器人一个负向的奖励如果它向后走了一步或者跌倒了。强化学习算法需要找到一组最佳行动使得机器人获得最大的奖励。
强化学习算法在诸如直升机自动驾驶、机器人行走、手机网络路由、市场战略决策等领域有着广泛成功的应用。我们将会从马尔可夫决策过程(Markov decision processes (MDP))开始学起,它给出了强化学习问题形式化的定义。
马尔可夫决策过程
马尔可夫决策过程由一个五元组构成,可以表示为(S, A, {Psa}, γ, R),其中:
- S是状态集合。比如在直升机无人驾驶例子中,S就是直升机可能的位置和方向集合。
- A是行动集合。比如在直升机无人驾驶例子中,A就是操控直升机可能的动作集合,比如上下左右等。
- Psa是状态转换概率。Psa指的是在状态s采取行动a的概率分布。
- γ ∈ [0, 1)是折扣因子(discount factor)。
- R: S × A → R是奖励函数(reward function)。R表示在状态s采取行动a时能获得的奖励。奖励函数有时只和状态有关,这时我们写成R: S → R。
MDP的决策过程如下:首先我们处于初始状态s0,然后从行动集合A中选择一个行动a0,这样我们的状态按照Ps0a0的概率转移到下一个状态s1。紧接着我们选择下一个行动a1,状态按照Ps1a1的概率转移到下一个状态s2。再接着我们选择下一个行动a2,以此类推。我们可以把这一过程用下图表示:
在遍历所有的状态和行动后,整个过程的奖励为:
如果我们把奖励函数当作只和状态相关,那么可以简化为:
我们后面会一直使用简化版的奖励函数R(s),尽管把它扩展到R(s, a)并没有太大的难度。
我们强化学习的目标就是选择一组行动使得整个奖励函数的期望最大化:
注意奖励的值随着时刻t被γt的因子衰减。因此为了获得最大的奖励,我们需要尽早获得正向的奖励或者推迟获得负向的奖励。在经济学领域中,R表示获得的金钱,γ可以被自然的解释为“利率”(可以解释为今天的美元比明天的值钱)。
策略(policy)是指任意一个从状态到行动的映射函数π: S → A。当我们在状态s时执行某个策略π时,我们采取的行动a = π(s)。我们定义策略π的价值函数(value function)为:
Vπ(s)表示的是初始状态为s,执行策略为π时总奖励的期望值。
对于一个固定的策略π,其价值函数Vπ满足贝尔曼方程(Bellman equations):

上式表明了Vπ包含了两部分:第一部分是初始状态下的立即奖励(immediate reward)R(s),第二部分是后续状态下的总奖励。我们更详细地考察下第二部分,这个总奖励可以被写成:
其中s′是初始状态s之后的下一个状态,因此整个第二部分是指初始状态为s′下的后续所有奖励之和。
贝尔曼方程可以用来高效地求解Vπ(s)。特别的,对于有限状态的MDP(|S| < ∞),我们可以为每个状态s写出对应的方程,这样对于|S|个状态就有|S|个方程,通过求解这个方程组就可以就出每个Vπ(s)。
我们的目标是找到最大的价值函数,因此定义最优价值函数(optimal value function):
对于最优价值函数,也有对应版本的贝尔曼方程:

我们同样定义最优策略π*: S → A为:
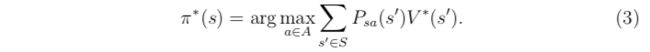
π*(s)就是使得等式(2)中获得最优价值函数的那个策略。
对于所有的状态s和所有的策略π,可以很容易地发现它们满足如下不等式:
注意π*对于所有的状态s都成立,这意味着不管我们在MDP中选取哪个作为初始状态,最优策略的函数不变。
价值迭代和策略迭代
现在我们介绍用于求解有限状态的MDP问题的两种算法,现在我们考虑的MDP问题必须是有限状态和有限行动的,即满足|S| < ∞,|A| < ∞。
求解MDP的第一个方法称为价值迭代(value iteration),步骤如下:
- 对每一个状态s,初始化V(s) := 0
重复如下操作直到收敛:{
对于每个状态s,更新V(s):
}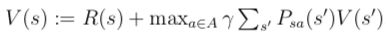
算法的第2步可以看作是不断地用贝尔曼等式去更新价值函数。第2步的循环可以有两种不同的更新方式。第一种方法,我们可以为每个状态s计算V(s),然后一次性把新的V(s)值替换旧值,这种更新称为是同步(synchronous)的。这种情况下,这个算法可以认为是实现了一个贝尔曼算子(Bellman backup operator),贝尔曼算子将当前价值函数映射到更接近最优值的一个估计。另一种更新方法称为异步(asynchronous)更新,这种情况下每次计算出V(s)后就立刻进行更新。
不管是同步还是异步的更新,价值迭代都会使得V不断收敛到V*,得到V*后我们通过等式(3)就能求出最佳策略。
求解MDP的第二个方法称为策略迭代(policy iteration),步骤如下:
- 随机初始化一个策略π
- 重复如下操作直到收敛:{
(a). 令V := Vπ
(b). 对于每个状态s,更新π(s):}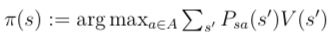
算法的第2步不断地根据当前策略求出价值函数,然后根据当前价值函数更新策略。其中第2步中的(a)可以用之前提到的求解方程组获得。
在算法经过一定次数的迭代后,V会不断收敛到V*,π会不断收敛到π*。
价值迭代和策略迭代都是用于求解MDP的常规算法,目前没有一个统一的定论说哪个更好。对于规模较小的MDP,策略迭代收敛更快。对于规模较大的MDP,由于求解方程组的开销太大,价值迭代性能更好。因此在实践中,通常选取的算法是价值迭代。
MDP的模型学习
到目前为止,我们都是在已知状态转换概率和奖励函数的情况下讨论MDP算法。但在实际情况中,通常状态集合、行动集合和折扣因子是已知的,但状态转换概率和奖励函数很可能是未知的,这个时候我们就需要从实际数据中预估它们。

比如上图中描述了若干轮MDP迭代的过程,其中si(j)表示第j轮实验的i时刻时的状态,ai(j)是对应时刻的行动。在实际情况中,每次实验都需要运行到终止状态为止,或者运行相对比较多的次数为止。
在这若干次实验后,我们可以根据经验认为状态转换概率由下式给出:

如果这个比率是“0/0”,也就是没有出现状态s和行动a的情况下,我们可以简单地用1/|S|进行估计,也就是所有状态出现的平均值。
如果我们实验运行的次数足够多,分子和分母可以用所有实验中出现次数的累加值,这样算出来的比率更接近状态转换概率的真实情况。
类似的,如果奖励函数R未知,我们可以把R(s)的值用状态s下的平均奖励作近似估计。
在建立了模型参数后,我们就可以用价值迭代或者策略迭代求解MDP问题了。将两者结合起来,下面描述了在状态转换概率未知的情况下求解MDP问题的步骤:
- 随机初始化一个策略π
- 重复如下操作直到收敛:{
(a). 用策略π进行若干次MDP实验
(b). 根据实验结果,估算出Psa的值
(c). 根据估算出的Psa,执行价值迭代得到新的V
(d). 根据新得到的V,执行策略迭代中第2步中的(b),从而更新π
}
我们发现对于这个特定的算法,有一个很简单的优化可以使得这个算法运行更快。在算法内层循环中的(c)步,价值迭代默认是把V初始化成0,如果将V初始化成上一轮迭代得到的V值,这样能获得一个更好的迭代起始点,因而收敛地更快。
总结
- 强化学习的一个常见模型是马尔可夫决策过程(MDP),MDP由一个五元组构成,MDP的目标是找到最优价值函数
- 当MDP是有限状态的情况下,可以用价值迭代或策略迭代两种方法求解。对于规模较小的MDP,策略迭代收敛更快;对于规模较大的MDP,价值迭代性能更好。因此在实践中,通常选取的算法是价值迭代
- 当MDP的状态转换概率和奖励函数未知的情况下,可以进行多次实验并根据实验结果给出近似的预估
参考资料
- 斯坦福大学机器学习课CS229讲义 Reinforcement Learning and Control
- 网易公开课:机器学习课程 双语字幕视频