前言
测序的生信数据往往体量庞大,动辄几十个G不在话下,常规的下载方式往往会遇到下载速度慢或者下载不成功的问题。但是呢,在复现论文或者学习生信流程的过程中,获取数据又是第一步的工作,所以总结了一些简单的数据下载的方式。这里的数据主要针对有SRA号的测序数据,这些数据是已发表文献中的高通量测序数据,因为作者也是一枚生信小白,所以记录成分更多。
目录
- NCBI-SRA数据库与EBI-ENA数据库
- SRA数据库的各种编号
- 使用 aria2 从 ENA 直接下载 fastq 文件
- 使用 fastq-dump 从 SRA 获取 fastq 文件
- 使用 rsync 从 NCBI 快速获取数据
NCBI-SRA数据库与EBI-ENA数据库
所有已发表文献中的高通量测序数据大多会上传到某个数据库中方便其他人的下载学习与再研究,这其中受众最广的自然是出身NCBI的SRA数据库。同时出身EBI的ENA数据库对于下载数据有很多便利之处,所以在具体下载文件之前先了解一下这两个数据库的情况。
补充说明,NCBI与EBI同属于INSDC:International Nucleotide Sequence Database Collaboration,提交给所属三个数据库的数据是可以互通的。该架构内容具体如下:
- NCBI: National Center for Biotechnology Information
- EBI: European Bioinformatics Institute
- DDBJ:DNA Data Bank of Japan
SRA数据库
SRA数据库: Sequence Read Archive是一个保存高通量测序数据以及比对信息和元数据(meta data)的数据库,所有已经发表的文献中的高通量测序数据基本上都会上传到该数据库中,毕竟这个数据库隶属于NCBI。
ENA数据库
ENA数据库: European Nucleotide Archive隶属于EBI,功能上应该是与SRA类似的,但是其搜索界面更加亲民,并且对于下载fastq文件以及检查下载数据完整性更加友好,所以强烈推荐优先使用。具体优劣势详见后续说明。

SRA数据库的各种编号
- 元数据(meta data)
是指与测序实验及其实验样品相关的数据, 如实验目的、 实验设计、 测序平台、 样本数据(物种, 菌株,个体表型等),在SRA数据库中,meta数据分如下层次来存储:- 研究课题(study)
在 SRA 数据库中,研究课题的检索号(accession number)以前缀 DRP,ERP 或 SRP 开头。 - 样本信息(sample)
样本的检索号以前缀 DRS,ERS 或 SRS 开头。 样本信息可以包括物种信息、 菌株(品系)信息、家系信息、表型数据、临床数据, 组织类型等。 - 实验信息(experiment)
实验的检索号以前缀 DRX,ERX 或 SRX 开头。 实验是 SRA 数据库的最基本单元, 就像 PubMed 数据库的每一篇文献是 PubMed数据库的基本单元一样。 一个实验隶属于某个研究课题,对一个或多个样本进行测序,产生的测序数据以 runs 的形式存储于SRA数据库。
- 研究课题(study)
- 序列数据
包括序列及其质量信息等,在 SRA 数据库中以 run 为单元存储。run 的检索号以前缀 DRR,ERR 或 SRR 开头。
我们可以来看一个例子,这个例子来源于 该文献。给大家展示以下其中有关野生型小鼠胚胎干细胞的相关SRA编号如下:

使用aria2从ENA直接下载fastq文件
在有关数据库和SRA编号的铺垫之后,我们来看看怎样来下载获得我们所需要的数据,因为大部分的数据分析流程都要从测序数据的质控开始,而常用的质控软件所需要的输入文件格式一般都是fastq, 所以我们的目标便是从一个已有的SRA号来获得fastq数据。
ENA数据库使用
最直接的方式便是利用ENA数据库,我们这里继续使用上面提到的文献,目标是从ENA数据库中下载得到2个检索号以SRR开头的fastq数据,检索号分别为:SRR7368841、 SRR7368842 。
首先,在数据库页面右上角搜索栏输入目标SRA检索号,确认后稍等片刻可得结果页面

其次,点击选取 Experiment 可以获得该实验下所有的测序序列数据的信息

我们可以看到隶属于该实验的两个序列数据信息,并且可以在 FASRTQ files(FTP) 栏中获得直接下载 fastq 文件的FTP 地址。
获取直接下载 fastq 文件的FTP地址
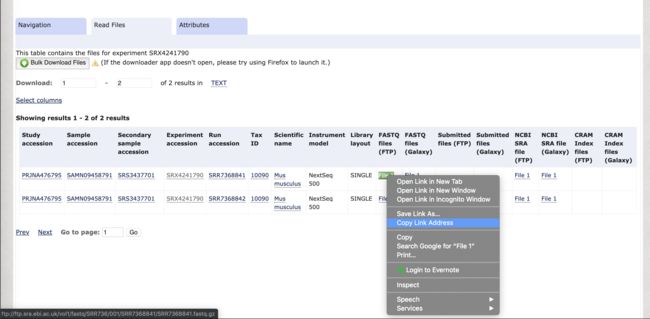
aria2 从FTP地址下载 fastq 文件
获得具体地址之后,我们可以通过命令行软件进行数据的下载,这里推荐速度飞快的aria2 软件,linux下具体安装方式可见该教程。
单个与多个数据下载代码:
#single data file downloaded into dir data_download
aria2c -d $HOME/data_download/ ftp://ftp.sra.ebi.ac.uk/vol1/fastq/SRR736/001/SRR7368841/SRR7368841.fastq.gz
#multiple data files downloaded into dir data_download
aria2c -Z -d $HOME/data_download/ ftp://ftp.sra.ebi.ac.uk/vol1/fastq/SRR736/001/SRR7368841/SRR7368841.fastq.gz ftp://ftp.sra.ebi.ac.uk/vol1/fastq/SRR736/002/SRR7368842/SRR7368842.fastq.gz
其中, -d 参数确定的是下载文件保存的地址,默认值是当前工作目录。数据下载过程中会显示下载进度与下载速度,可以方便时时观察。下载的数据将会是 fastq.gz 的压缩形式, 可以直接进行后续的分析。
ENA数据库的另一个优势
除了可以直接获取得到 fastq 文件外,使用ENA数据库还有一个优势是可以确认下载数据的完整性。生信数据的大体量性带来的下载时间长(期间网络万一不正常就会波动)可能会造成下载数据的缺失等问题,这些问题一般很难在获得数据的初期被发现。ENA数据库提供了md5码这种途径来检查数据的完整性。
简单来说,依据特定算法可以从大数据文件的数据内容计算出一个特定的md5码,如果数据有缺失,计算所得的md5码就会与原始的不同,所以我们可以通过计算我们下载所得数据的md5码并与网站提供的原始md5码进行比较来判断下载数据是否有问题,如果相同则证明数据没问题。
在ENA数据库结果页面点击信息表坐上角的 select column 后可以选择将 Fastq md5 展示出来

针对下载所得的数据文件,我们可以使用 md5sum 命令进行计算其md5码。
md5sum file_name.fastq.gz
使用fastq-dump从SRA获取fastq文件
如果ENA上有我们所需要的数据的话,下载的过程自然是十分快捷舒服的,但是有可能数据的同步速度没那么快,在NCBI上传的数据还没同步到ENA的网站上你就要使用了怎么办呢?那还是老老实实回到NCBI去下载,NCBI为了方便管理下载者的流量,有其专门的下载软件sratoolkit。
sratoolkit 下载与使用
sratoolkit的下载可以参照官方文档,需要注意的是下载之后的配置路径,参照官方文档的说明应该是没有问题的。因为本人使用的是实验室服务器里已经配置好的环境,所以很轻松地略过了这一步骤,哈哈哈。
主要使用的工具是prefetch和fastq-dump。其中,prefetch主要是用来从NCBI的数据库中下载得到.sra文件,文件将会保存在如下地址:
~/ncbi/public/sra/
fastq-dump则可以将下载所得的.sra文件转化为.fastq文件,可以配套prefetch获得fastq文件,也可以单独使用下载得到fastq文件(速度巨慢)。
NCBI 数据下载示例
无论是使用 prefetch 还是 fastq-dump, 我们都可以直接使用SRA检索号,而不需要使用具体地址。下载示例如下:
#use prefetch and fastq-dump to get fastq.gz file into dir data_download
prefetch SRR7368841
fastq-dump -o $HOME/data_download --gzip ~/ncbi/pubilic/sra/*.sra
#use fastq-dump to download fastq.gz file into dir data_download
fastq-dump -o $HOME/data_download --gzip SRR7368841
使用rsync从NCBI快速获取数据
这里应该是要挖一个坑,其实在NCBI上也可以通过寻找FTP地址进行下载。但是如果直接使用 wget 等方法直接去通过FTP地址下载的话,数据是会有丢失的。这里有另外一种方式(rsync)可以利用NCBI中的FTP地址去下载数据,但是在NCBI上寻找SRA号对应的FTP地址比较麻烦,同时在使用rsync时需要对FTP地址进行一定规则的改写,所以还是有点麻烦的。当然,这种方法的下载速度自然是要比使用sratoolkit快上不少。
因为种种原因(嗯,不是纯粹因为懒),所以先把这个坑挖下吧,之后有时间再来填坑。但或许要等到ENA下载不了又受不了fastq-dump龟速的时候了吧,哈哈哈。
嗯,这就是有关sra与fastq数据下载的个人经验了,记录在此也希望能发挥到它能发挥的作用吧。