- 一. 复杂度
- 时间复杂度
- 二. 数据结构
- 1. 数组
- 数组为什么下标从0开始
- 容器能否完全替代数组?- 2. 链表 (Linked list)
- 3. 栈
- 4. 队列
- 5. 跳表
- 时间复杂度:
- 空间复杂度:
- 跳表索引动态更新
- 跳表特点:
- 三. 算法
- 1. 递归
- 2. 排序
- 2.1 冒泡排序
- 2.2 插入排序
- 2.3 选择排序
- 2.4 归并排序
- 2.5 快速排序
- 2.6 桶排序
- 2.7 计数排序
- 2.8 基数排序
- 3. 查找
- 3.1 二分查找法
一. 复杂度
复杂度分析,是贯彻数据结构和算法中的一项基础技能,学习数据结构和算法的目的,无非就是要写出占用空间更小、运行时间更短的代码。
时间复杂度
- 大O表示法:
T(n) = O(f(n))
- 表示代码执行时间随数据规模增长的变化趋势(注意只是表示「变化趋势」)
- 由于只是表示变化趋势,一般计算复杂度时,会忽略低阶、常量、系数
-
几种常见的时间复杂度量级:

多项式量级:
- 常数阶 O(1)
- 对数阶 O(logn)
- 线性阶 O(n)
- 线性对数阶 O(nlogn)
- 平方阶 O(n²) O(n³) ... O(n^k)
非多项式量级:(n越多,执行时间急剧上升,性能低)
- 指数阶 O(2^n)
- 阶乘阶 O(n!)
- 加法法则和乘法法则
- 加法法则:总复杂度等于量级最大的那段代码的复杂度
- 乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
- 平均时间复杂度:
- 也叫加权平均时间复杂度或者期望时间复杂度。
- 要会计算:最好、最坏、平均时间
- 均摊时间复杂度
- 特殊的平均时间复杂度
- 相当于算法有规律可循,计算时间时,可以把一次耗时多的操纵的时间,均摊给多次耗时少的操纵。
二. 数据结构
1. 数组
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。具有的特性:
- 线性表
- 连续的内存空间
- 相同类型的数据
- 可以随机访问
- 数据操作比较低效,平均情况时间复杂度为 O(n)
数组为什么下标从0开始
- 由于数组是是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
所以:
- 如果下标从0开始:
- 计算下标为k的对象的地址的公式为:
a[k]_address = base_address + k * type_size
- 计算下标为k的对象的地址的公式为:
- 如果下标从1开始:
- 计算下标为k的对象的地址的公式为:
a[k]_address = base_address + (k-1) * type_size - 对于 CPU 来说,就是多了一次减法指令。
- 计算下标为k的对象的地址的公式为:
- C 语言设计者用 0 开始计数数组下标,之后的 Java、JavaScript 等高级语言都效仿了 C 语言。
容器能否完全替代数组?
例如Java的ArrayList,ArrayList 最大的优势就是可以将很多数组操作的细节封装起来。比如前面提到的数组插入、删除数据时需要搬移其他数据等。另外,它还有一个优势,就是支持动态扩容。
那么,作为高级语言编程者,是不是数组就无用武之地了呢?当然不是,有些时候,用数组会更合适些,总的来说,对于业务开发,直接使用容器就足够了,省时省力。毕竟损耗一丢丢性能,完全不会影响到系统整体的性能。但如果你是做一些非常底层的开发,比如开发网络框架,性能的优化需要做到极致,这个时候数组就会优于容器,成为首选。
2. 链表 (Linked list)
不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用。
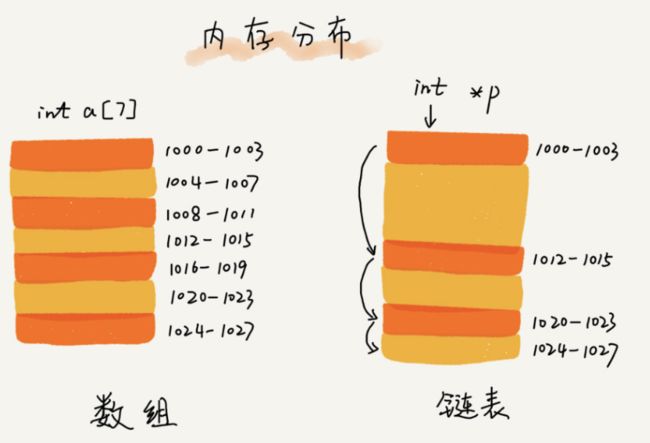
几种常见的链表形式:
1. 单链表
2. 循环链表
3. 双向链表 (空间换时间思想)
4. 双向循环列表
与数组的对比:
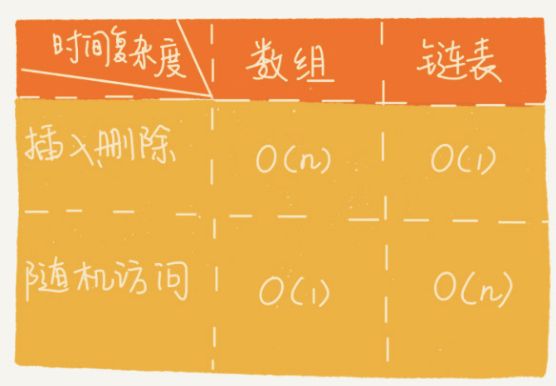
不过,数组和链表的对比,并不能局限于时间复杂度。而且,在实际的软件开发中,不能仅仅利用复杂度分析就决定使用哪个数据结构来存储数据。
写链表代码的几个技巧:
1. 理解指针或引用的含义、警惕指针丢失和内存泄漏
2. 利用哨兵简化实现难度
3. 重点留意边界条件处理
4. 举例画图、辅助思考
写链表代码是最考验逻辑思维能力的。因为,链表代码到处都是指针的操作、边界条件的处理,稍有不慎就容易产生 Bug。链表代码写得好坏,可以看出一个人写代码是否够细心,考虑问题是否全面,思维是否缜密。所以,这也是很多面试官喜欢让人手写链表代码的原因。所以,这一节讲到的东西,你一定要自己写代码实现一下,才有效果。
- 单链表反转
- 链表中环的检测
- 两个有序的链表合并
- 删除链表倒数第 n 个结点
- 求链表的中间结点
3. 栈
- 用数组实现的 顺序栈
- 用链表实现的 链式栈
- 出栈入栈时间复杂度 空间复杂度都是O(1)
- 先进后出
应用:
- 1,函数的临时变量的存储销毁
- 2,表达式求值
- 3,浏览器的前进后退
4. 队列
特点:先进先出
- 用数组实现 顺序队列
- 用链表实现 链式队列
队列拓展:
-
循环队列
- 解决用数组实现的队列需要数据迁移的问题
- 队空:head == tail
-
队满:(tail+1)%n=head。

-
阻塞队列
- 队列满了时,不给入队。
- 生产者 - 消费者模型
-
并发队列
- 线程安全的队列我们叫作并发队列
5. 跳表
我们知道,数组支持快速的随机访问,而链表不支持,这样的话,就不能用二分查找法来对链表进行快速查找。实际上,我们只需要对链表稍加改造,就可以支持类似“二分”的查找算法。我们把改造之后的数据结构叫作跳表(Skip list)。
跳表,其实就是对有序链表建立多级“索引”,每两个(也可以是其他数量)结点提取一个结点到上一级,我们把抽出来的那一级叫作索引或索引层。你可以看我画的图。图中的 down 表示 down 指针,指向下一级结点。

如果我们现在要查找某个结点,比如 16。我们可以先在索引层遍历,当遍历到索引层中值为 13 的结点时,我们发现下一个结点是 17,那要查找的结点 16 肯定就在这两个结点之间。然后我们通过索引层结点的 down 指针,下降到原始链表这一层,继续遍历。这个时候,我们只需要再遍历 2 个结点,就可以找到值等于 16 的这个结点了。这样,原来如果要查找 16,需要遍历 10 个结点,现在只需要遍历 7 个结点。
我举的例子数据量不大,查找效率的提升也并不明显。为了让你能真切地感受索引提升查询效率。我画了一个包含 64 个结点的链表,按照前面讲的这种思路,建立了五级索引。
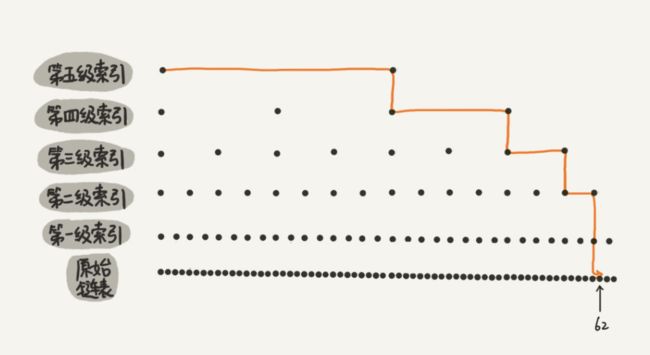
从图中我们可以看出,原来没有索引的时候,查找 62 需要遍历 62 个结点,现在只需要遍历 11 个结点,速度是不是提高了很多?所以,当链表的长度 n 比较大时,比如 1000、10000 的时候,在构建索引之后,查找效率的提升就会非常明显。
时间复杂度:
跳表查询某个数据的时间复杂度是多少呢?
按照我们刚才讲的,每两个结点会抽出一个结点作为上一级索引的结点,那第一级索引的结点个数大约就是 n/2,第二级索引的结点个数大约就是 n/4,第三级索引的结点个数大约就是 n/8,依次类推,也就是说,第 k 级索引的结点个数是第 k-1 级索引的结点个数的 1/2,那第 k级索引结点的个数就是 n/(2k)。
假设索引有 h 级,最高级的索引有 2 个结点。通过上面的公式,我们可以得到 n/(2h)=2,从而求得 h=log2n-1。如果包含原始链表这一层,整个跳表的高度就是 log2n。我们在跳表中查询某个数据的时候,如果每一层都要遍历 m 个结点,那在跳表中查询一个数据的时间复杂度就是 O(m*logn)。
那这个 m 的值是多少呢?按照前面这种索引结构,我们每一级索引都最多只需要遍历 3 个结点,也就是说 m=3。
所以在跳表中查询任意数据的时间复杂度就是 O(logn)。这个查找的时间复杂度跟二分查找是一样的。换句话说,我们其实是基于单链表实现了二分查找,是不是很神奇?不过,天下没有免费的午餐,这种查询效率的提升,前提是建立了很多级索引,也就是我们在第 6 节讲过的空间换时间的设计思路。
空间复杂度:
跳表是不是很浪费内存?比起单纯的单链表,跳表需要存储多级索引,肯定要消耗更多的存储空间。那到底需要消耗多少额外的存储空间呢?我们来分析一下跳表的空间复杂度。
跳表的空间复杂度分析并不难,我在前面说了,假设原始链表大小为 n,那第一级索引大约有 n/2 个结点,第二级索引大约有 n/4 个结点,以此类推,每上升一级就减少一半,直到剩下 2 个结点。如果我们把每层索引的结点数写出来,就是一个等比数列。

这几级索引的结点总和就是 n/2+n/4+n/8…+8+4+2=n-2。所以,跳表的空间复杂度是 O(n)。也就是说,如果将包含 n 个结点的单链表构造成跳表,我们需要额外再用接近 n 个结点的存储空间。那我们有没有办法降低索引占用的内存空间呢?
我们前面都是每两个结点抽一个结点到上级索引,如果我们每三个结点或五个结点,抽一个结点到上级索引,是不是就不用那么多索引结点了呢?
第一级索引需要大约 n/3 个结点,第二级索引需要大约 n/9 个结点。每往上一级,索引结点个数都除以 3。为了方便计算,我们假设最高一级的索引结点个数是 1。我们把每级索引的结点个数都写下来,也是一个等比数列。

通过等比数列求和公式,总的索引结点大约就是 n/3+n/9+n/27+…+9+3+1=n/2。尽管空间复杂度还是 O(n),但比上面的每两个结点抽一个结点的索引构建方法,要减少了一半的索引结点存储空间。
实际上,在软件开发中,我们不必太在意索引占用的额外空间。在讲数据结构和算法时,我们习惯性地把要处理的数据看成整数,但是在实际的软件开发中,原始链表中存储的有可能是很大的对象,而索引结点只需要存储关键值和几个指针,并不需要存储对象,所以当对象比索引结点大很多时,那索引占用的额外空间就可以忽略了。
跳表索引动态更新
当我们不停地往跳表中插入数据时,如果我们不更新索引,就有可能出现某 2 个索引结点之间数据非常多的情况。极端情况下,跳表还会退化成单链表。

作为一种动态数据结构,我们需要某种手段来维护索引与原始链表大小之间的平衡,也就是说,如果链表中结点多了,索引结点就相应地增加一些,避免复杂度退化,以及查找、插入、删除操作性能下降。
当我们往跳表中插入数据的时候,我们可以选择同时将这个数据插入到部分索引层中。如何选择加入哪些索引层呢?
我们通过一个随机函数,来决定将这个结点插入到哪几级索引中,比如随机函数生成了值 K,那我们就将这个结点添加到第一级到第 K 级这 K 级索引中。
随机函数的选择很有讲究,从概率上来讲,能够保证跳表的索引大小和数据大小平衡性,不至于性能过度退化。
跳表特点:
- 前提是有序链表
- 动态数据结构
- 支持快速的查询、插入、删除操作,时间复杂度为O(logn)
- 表面上空间复杂度是O(n),但是因为索引只需要存储关键值和几个指针,并不需要存储对象,所以当对象比索引结点大很多时,那索引占用的额外空间就可以忽略了。
- 和红黑树相比的优势:当需要按区间查找数据时,跳表可以做到 O(logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了。
- 代码实现比红黑树容易很多。
三. 算法
1. 递归
可以用递归的条件:
- 一个问题的解可以分解为几个子问题的解
- 这个问题与分解之后的子问题,除了数据规模不同,求解思路完全一样
- 存在递归终止条件
写递归算法的思路:
- 归纳出递归表达式
- 寻找终止条件
递归代码的弊端:
- 堆栈溢出
- 可能会重复计算
- 函数调用耗时多
- 空间复杂度高
2. 排序
衡量排序算法好坏的三要素:
- 执行效率
- 最好时间复杂度
- 最坏时间复杂度
- 平均时间复杂度
- 时间复杂度的系数、常数 、低阶(因为排序的数据规模一般不会非常大)
- 比较、交换的次数
- 额外内存消耗(内存消耗为O(1)的称为原地排序)
- 稳定性,是否是稳定排序(即如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变)
按时间复杂度分类:
- O(n²): 冒泡排序、插入排序、选择排序
- O(nlogn):归并排序、快速排序
- O(n) :桶排序、计数排序、基数排序 (条件苛刻,适用于部分场景)
2.1 冒泡排序
原理: 从下往上,逐次比较两个相邻的数据,如果下面的数据比上面的数据大,则把这两个数据的位置互换。


- 最好时间复杂度 O(n)
- 最坏时间复杂度 O(n^2)
- 平均时间复杂度 O(n^2)
- 原地排序、稳定排序
2.2 插入排序
原理: 分为已排区域和未排区域,每次拿未排区域中的第一个数,插入到已排区域中正确的位置。

- 最好时间复杂度 O(n)
- 最坏时间复杂度 O(n^2)
- 平均时间复杂度 O(n^2)
- 原地排序、稳定排序
2.3 选择排序
原理: 分为已排区域和未排区域,每次从未排区域中选取最小的数,放到已排区域的最后面。
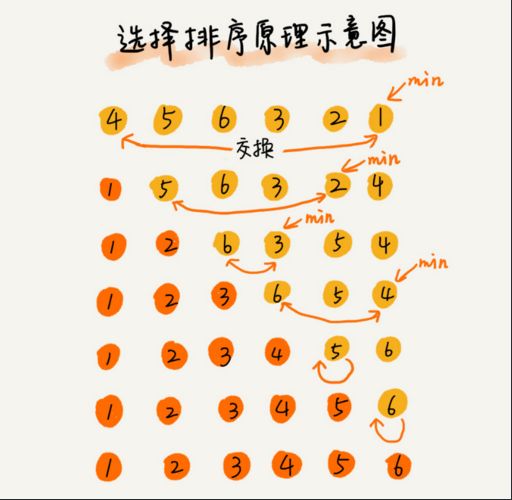
- 最好时间复杂度 O(n^2)
- 最坏时间复杂度 O(n^2)
- 平均时间复杂度 O(n^2)
- 原地排序、 非稳定的排序算法
- 一般都不考虑用该算法。
2.4 归并排序
原理: 归并排序的核心思想还是蛮简单的。如果要排序一个数组,我们先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。

- 非原地排序,空间复杂度为O(n)
- 稳定排序
- 利用分治递归思想
- 递推公式:
merge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r)) -
最好、最坏、平均时间复杂度都是 O(nlogn)

2.5 快速排序

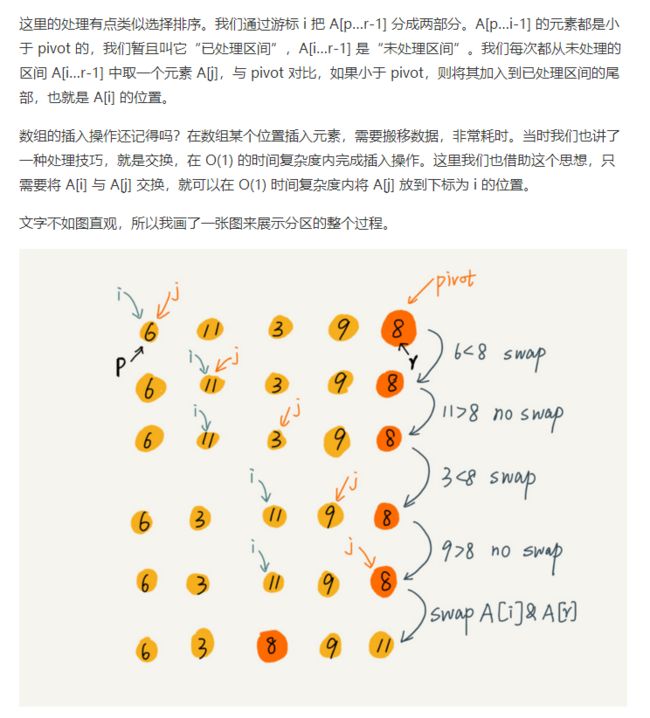
- 原地排序
- 非稳定排序
- 递推公式:
quick_sort(p…r) = partition(p…r) + quick_sort(p…q-1) + quick_sort(q+1, r) - 最好时间复杂度: O(nlogn)
- 最坏时间复杂度: O(n^2) (极小几率出现)
- 平均时间复杂度: O(nlogn)
2.6 桶排序
桶排序,顾名思义,会用到“桶”,核心思想是将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是有序的了。

桶排序的时间复杂度为什么是 O(n) 呢?我们一块儿来分析一下。如果要排序的数据有 n 个,我们把它们均匀地划分到 m 个桶内,每个桶里就有 k=n/m 个元素。每个桶内部使用快速排序,时间复杂度为 O(k * logk)。m 个桶排序的时间复杂度就是 O(m * k * logk),因为 k=n/m,所以整个桶排序的时间复杂度就是 O(n*log(n/m))。当桶的个数 m 接近数据个数 n 时,log(n/m) 就是一个非常小的常量,这个时候桶排序的时间复杂度接近 O(n)。
苛刻的条件:
- 要排序的数据需要很容易就能划分成 m 个桶
- 桶与桶之间有着天然的大小顺序
- 数据在各个桶之间的分布是比较均匀的
2.7 计数排序
计数排序其实是桶排序的一种特殊情况: 数据的访问很小(例如年龄、考生的成绩),桶的数量是有限的。
以给高考考生成绩进行排名为例,考生的满分是 900 分,最小是 0 分,对应901个桶,把全国的考生放入这901个桶,桶内的数据都是分数相同的考生,所以并不需要再进行排序。
特殊要求:
- 只能用在数据范围不大的场景中,如果数据范围 k 比要排序的数据 n 大很多,就不适合用计数排序了
- 计数排序只能给非负整数排序,如果要排序的数据是其他类型的,要将其在不改变相对大小的情况下,转化为非负整数。如果要排序的数据中有负数,数据的范围是 [-1000, 1000],那我们就需要先对每个数据都加 1000,转化成非负整数。如果考生成绩精确到小数后一位,我们就需要将所有的分数都先乘以 10,转化成整数。
2.8 基数排序
我们再来看这样一个排序问题。假设我们有 10 万个手机号码,希望将这 10 万个手机号码从小到大排序,你有什么比较快速的排序方法呢?
我们之前讲的快排,时间复杂度可以做到 O(nlogn),还有更高效的排序算法吗?桶排序、计数排序能派上用场吗?手机号码有 11 位,范围太大,显然不适合用这两种排序算法。针对这个排序问题,有没有时间复杂度是 O(n) 的算法呢?现在我就来介绍一种新的排序算法,基数排序。
刚刚这个问题里有这样的规律:假设要比较两个手机号码 a,b 的大小,如果在前面几位中,a 手机号码已经比 b 手机号码大了,那后面的几位就不用看了。
借助稳定排序算法,这里有一个巧妙的实现思路。还记得我们第 11 节中,在阐述排序算法的稳定性的时候举的订单的例子吗?我们这里也可以借助相同的处理思路,先按照最后一位来排序手机号码,然后,再按照倒数第二位重新排序,以此类推,最后按照第一位重新排序。经过 11 次排序之后,手机号码就都有序了。
手机号码稍微有点长,画图比较不容易看清楚,我用字符串排序的例子,画了一张基数排序的过程分解图,你可以看下。
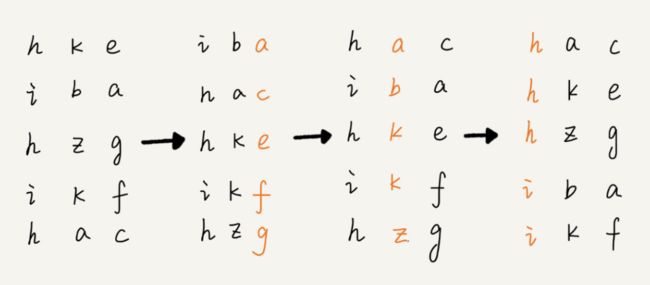
注意,这里按照每位来排序的排序算法要是稳定的,否则这个实现思路就是不正确的。因为如果是非稳定排序算法,那最后一次排序只会考虑最高位的大小顺序,完全不管其他位的大小关系,那么低位的排序就完全没有意义了。
根据每一位来排序,我们可以用刚讲过的桶排序或者计数排序,它们的时间复杂度可以做到 O(n)。如果要排序的数据有 k 位,那我们就需要 k 次桶排序或者计数排序,总的时间复杂度是 O(k*n)。当 k 不大的时候,比如手机号码排序的例子,k 最大就是 11,所以基数排序的时间复杂度就近似于 O(n)。
实际上,有时候要排序的数据并不都是等长的,比如我们排序牛津字典中的 20 万个英文单词,最短的只有 1 个字母,最长的我特意去查了下,有 45 个字母,中文翻译是尘肺病。对于这种不等长的数据,基数排序还适用吗?
实际上,我们可以把所有的单词补齐到相同长度,位数不够的可以在后面补“0”,因为根据ASCII 值,所有字母都大于“0”,所以补“0”不会影响到原有的大小顺序。这样就可以继续用基数排序了。
我来总结一下,基数排序对要排序的数据是有要求的:
- 需要可以分割出独立的“位”来比较,而且位之间有递进的关系,如果 a 数据的高位比 b 数据大,那剩下的低位就不用比较了
- 除此之外,每一位的数据范围不能太大,要可以用线性排序算法来排序,否则,基数排序的时间复杂度就无法做到 O(n) 了。
3. 查找
3.1 二分查找法
- 依赖于数组结构(数据量太大不适合用二分查找法,数据需要连续的存储空间)
- 数据必须是排好序的
- 时间复杂度:logn