1 FastDFS简介
FastDFS是一款类Google FS开源的轻量级分布式文件系统,它用纯C语言实现,支持Linux、FreeBSD、AIX等UNIX系统。它只能通过专有API对文件进行存取访问,不支持POSIX接口方式,不能mount使用。准确地讲,Google FS以及FastDFS、mogileFS、HDFS、TFS等类Google FS都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务。
FastDFS是为互联网应用量身定做的分布式文件系统,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标,使用FastDFS很容易搭建一套高性能的文件服务器集群提供文件上传、下载等服务。
1.1 功能包括:
文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件(建议范围:4KB < file_size <500MB)为载体的在线服务,如相册网站、视频网站等等。
1.2 对比
和现有的类Google FS分布式文件系统相比,FastDFS的架构和设计理念有其独到之处,主要体现在轻量级、分组方式和对等结构三个方面。
1.2.1 轻量级
关键信息:
1)Tracker不记录文件索引信息,占用内存小
2)FastDFS不对文件进行分块存储
3)客户端上传的文件和Storage server上的文件一一对应
4)文件索引,直接根据返回的文件ID定位文件
FastDFS只有两个角色:Tracker server和Storage server。Tracker server作为中心结点,其主要作用是负载均衡和调度。Tracker server在内存中记录分组和Storage server的状态等信息,不记录文件索引信息,占用的内存量很少。另外,客户端(应用)和Storage server访问Tracker server时,Tracker server扫描内存中的分组和Storage server信息,然后给出应答。由此可以看出Tracker server非常轻量化,不会成为系统瓶颈。
FastDFS中的Storage server在其他文件系统中通常称作Trunk server或Data server。Storage server直接利用OS的文件系统存储文件。FastDFS不会对文件进行分块存储,客户端上传的文件和Storage server上的文件一一对应。
众所周知,大多数网站都需要存储用户上传的文件,如图片、视频、电子文档等。出于降低带宽和存储成本的考虑,网站通常都会限制用户上传的文件大小,例如图片文件不能超过5MB、视频文件不能超过100MB等。我认为,对于互联网应用,文件分块存储没有多大的必要。它既没有带来多大的好处,又增加了系统的复杂性。FastDFS不对文件进行分块存储,与支持文件分块存储的DFS相比,更加简洁高效,并且完全能满足绝大多数互联网应用的实际需要。
在FastDFS中,客户端上传文件时,文件ID不是由客户端指定,而是由Storage server生成后返回给客户端的。文件ID中包含了组名、文件相对路径和文件名,Storage server可以根据文件ID直接定位到文件。因此FastDFS集群中根本不需要存储文件索引信息,这是FastDFS比较轻量级的一个例证。而其他文件系统则需要存储文件索引信息,这样的角色通常称作NameServer。其中mogileFS采用MySQL数据库来存储文件索引以及系统相关的信息,其局限性显而易见,MySQL将成为整个系统的瓶颈。
FastDFS轻量级的另外一个体现是代码量较小。最新的V2.0包括了C客户端API、FastDHT客户端API和PHP extension等,代码行数不到5.2万行。
1.2.2 分组方式
关键信息:
1)备份配置一致性强,管理简单
2)可控性强,容易组内扩容和组间扩容
3)FastDFS对文件进行管理,Web server进行文件传输
类Google FS都支持文件冗余备份,例如Google FS、TFS的备份数是3。一个文件存储到哪几个存储结点,通常采用动态分配的方式。采用这种方式,一个文件存储到的结点是不确定的。举例说明,文件备份数是3,集群中有A、B、C、D四个存储结点。文件1可能存储在A、B、C三个结点,文件2可能存储在B、C、D三个结点,文件3可能存储在A、B、D三个结点。
FastDFS采用了分组存储方式。集群由一个或多个组构成,集群存储总容量为集群中所有组的存储容量之和。一个组由一台或多台存储服务器组成,同组内的多台Storage server之间是互备关系,同组存储服务器上的文件是完全一致的。文件上传、下载、删除等操作可以在组内任意一台Storage server上进行。类似木桶短板效应,一个组的存储容量为该组内存储服务器容量最小的那个,由此可见组内存储服务器的软硬件配置最好是一致的。
采用分组存储方式的好处是灵活、可控性较强。比如上传文件时,可以由客户端直接指定上传到的组。一个分组的存储服务器访问压力较大时,可以在该组增加存储服务器来扩充服务能力(纵向扩容)。当系统容量不足时,可以增加组来扩充存储容量(横向扩容)。采用这样的分组存储方式,可以使用FastDFS对文件进行管理,使用主流的Web server如Apache、nginx等进行文件下载。
1.2.3 对等结构
关键信息:
1)和传统的Master-Slave相比,逻辑简单
2)Tracker和Storage都存在对等的架构
FastDFS集群中的Tracker server也可以有多台,Tracker server和Storage server均不存在单点问题。Tracker server之间是对等关系,组内的Storage server之间也是对等关系。传统的Master-Slave结构中的Master是单点,写操作仅针对Master。如果Master失效,需要将Slave提升为Master,实现逻辑会比较复杂。和Master-Slave结构相比,对等结构中所有结点的地位是相同的,每个结点都是Master,不存在单点问题。
2 术语
FastDFS两个主要的角色:Tracker Server 和 Storage Server
Tracker Server:跟踪服务器,主要负责调度storage节点与client通信,在访问上起负载均衡的作用,和记录storage节点的运行状态,是连接client和storage节点的枢纽。
Storage Server:存储服务器,保存文件和文件的meta data(元数据)
Group:文件组,也可以称为卷(volume)。同组内服务器上的文件是完全相同的,做集群时往往一个组会有多台服务器,上传一个文件到同组内的一台机器上后,FastDFS会将该文件即时同步到同组内的其它所有机器上,起到备份的作用。
meta data:文件相关属性,键值对(Key Value Pair)方式,如:width=1024, height=768。和阿里云OSS的meta data相似。
3 FastDFS系统架构
FastDFS服务端有三个个角色:
- 跟踪器-tracker):跟踪服务器,主要做调度工作,起负载均衡的作用。在内存中记录集群中所有存储组和存储服务器的状态信息,是客户端和数据服务器交互的枢纽。
- 存储节点-storage:存储服务器(又称:存储节点或数据服务器),文件和文件属性(meta data)都保存到存储服务器上。Storage server直接利用OS的文件系统调用管理文件。
- 客户端-client:作为业务请求的发起方,通过专有接口,使用TCP/IP协议与跟踪器服务器或存储节点进行数据交互。
Tracker相当于FastDFS的大脑,不论是上传还是下载都是通过tracker来分配资源;客户端一般可以使用ngnix等静态服务器来调用或者做一部分的缓存;存储服务器内部分为卷(或者叫做组),卷于卷之间是平行的关系,可以根据资源的时候情况随时增加,卷内服务器文件相互同步备份,以达到容灾的目的

从FastDFS系统架构图可以看出,Tracker server之间相互独立,不存在直接联系。
客户端和Storage server主动连接Tracker server。Storage server主动向Tracker server报告其状态信息,包括磁盘剩余空间、文件同步状况、文件上传下载次数等统计信息。Storage server会连接集群中所有的Tracker server,向他们报告自己的状态。Storage server启动一个单独的线程来完成对一台Tracker server的连接和定时报告。需要说明的是,一个组包含的Storage server不是通过配置文件设定的,而是通过Tracker server获取到的。
不同组的Storage server之间不会相互通信,同组内的Storage server之间会相互连接进行文件同步。
Storage server采用binlog文件记录文件上传、删除等更新操作。binlog中只记录文件名,不记录文件内容。
文件同步只在同组内的Storage server之间进行,采用push方式,即源头服务器同步给目标服务器。只有源头数据才需要同步,备份数据并不需要再次同步,否则就构成环路了。有个例外,就是新增加一台Storage server时,由已有的一台Storage server将已有的所有数据(包括源头数据和备份数据)同步给该新增服务器。
也即就是:文件上传到一个组内的某台服务器,然后此服务器就开启线程,对应用组内其他的服务器,将新增的文件同步到上面。
Storage server中由专门的线程根据binlog进行文件同步。为了最大程度地避免相互影响以及出于系统简洁性考虑,Storage server对组内除自己以外的每台服务器都会启动一个线程来进行文件同步。
文件同步采用增量同步方式,系统记录已同步的位置(binlog文件偏移量)到标识文件中。标识文件名格式:{dest storage IP}_{port}.mark,例如:192.168.1.14_23000.mark。
4 文件上传和下载的交互过程
4.1 FastDFS文件上传流程
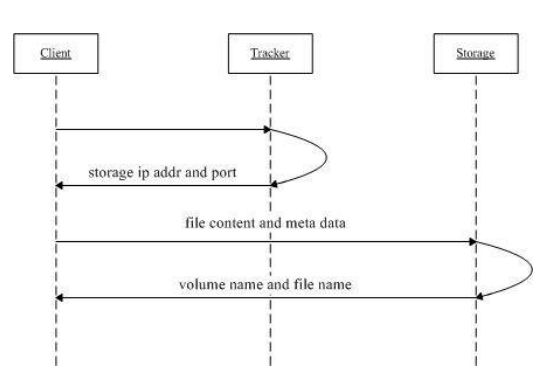
1、 Client询问Tracker server上传到的Storage server
2、 Tracker server返回一台可用的Storage server,返回的数据为该Storage server的IP地址和端口
3、Client直接和该Storage server建立连接,进行文件上传,Storage server返回新生成的文件ID,文件上传结束。
4.2 FastDFS文件下载流程
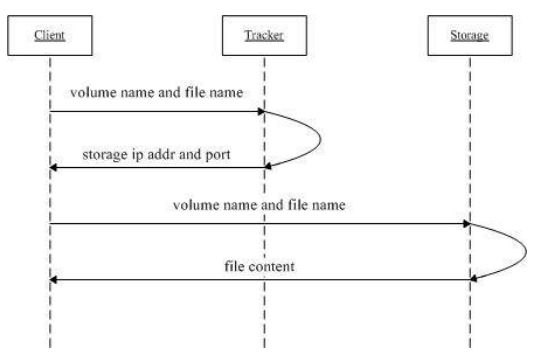
1、Client询问Tracker server可以下载指定文件的Storage server,参数为文件ID(包含组名和文件名)
2、Tracker server返回一台可用的Storage server
3、Client直接和该Storage server建立连接,完成文件下载。
5 HTTP访问支持
我们在使用FastDFS部署一个分布式文件系统的时候,通过FastDFS的客户端API来进行文件的上传、下载、删除等操作。同时通过FastDFS的HTTP服务器来提供HTTP服务。但是FastDFS的HTTP服务较为简单,无法提供负载均衡等高性能的服务,所以FastDFS的开发者——淘宝的架构师余庆同学,为我们提供在FastDFS使用Nginx模块(fastdfs-nginx-module)。可以重定向连接到源服务器取文件,避免客户端由于复制延迟的问题,出现错误。
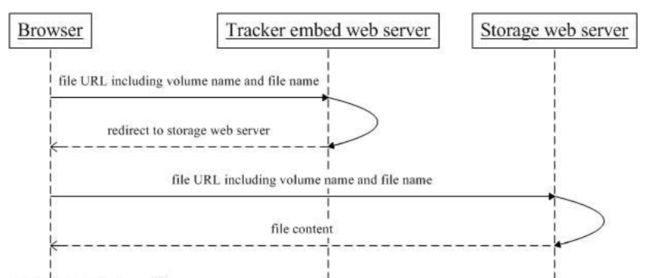
6 FastDFS原理
存储节点采用了分组(group)的方式。存储系统由一个或多个group组成,group与group之间的文件是*相互独立的,所有group的文件容量累加就是整个存储系统中的文件容量。一个group可以由一台或多台存储服务器组成,一个group下的存储服务器中的文件都是相同的,group中的多台存储服务器起到了冗余备份和负载均衡的作用(一个组的存储容量为该组内存储服务器容量最小的那个,不同组的Storage server之间不会相互通信,同组内的Storage server之间会相互连接进行文件同步)。
动态添加group
在group中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。
当存储空间不足或即将耗尽时,可以动态添加group。只需要增加一台或多台服务器,并将它们配置为一个新的group,这样就扩大了存储系统的容量。
FastDFS中的Storage server在其他文件系统中通常称作Trunk server或Data server。Storage server直接利用OS的文件系统存储文件。FastDFS不会对文件进行分块存储,客户端上传的文件和Storage server上的文件一一对应(FastDFS中的文件标识分为两个部分:组名和文件名,二者缺一不可)
Tracker Server 192.168.55.222 /home/tracker 端口:22122
Tracker Server 192.168.55.226 /home/tracker 端口:22122
Storage1 Server 192.168.55.223 group1 /home/storage 端口:23000
Storage4 Server 192.168.55.227 group1 /home/storage 端口:23000
Storage2 Server 192.168.55.224 group2 /home/storage 端口:23000
Storage3 Server 192.168.55.225 group2 /home/storage 端口:23000
Storage2为group2的源服务器
注意:
1.group2同组的Storage2和Storage3 FastDFS服务端口必须一致: port=23000。
2.一台服务器可以装多个组(group)但不能装同组的多个Storage,日志会报错误,日志报错原因是"注意1"
3.Version 4.05之前fastdfs内部绑定了libevent作为http服务器.Version 4.05之后的版本删除了内置的web http服务,内置的web http服务是个累赘,不用也罢!需整合Nginx作为web http服务。
4.启动storage server时,一直处于僵死状态.启动storage server,storage将连接tracker server,如果连不上,将一直重试。直到连接成功,启动才算真正完成!如果集群中有2台tracker server,而其中一台tracker没有启动,可能会导致storage server一直处于僵死状态
7 文件同步延迟问题
7.1 分析原因
总结:
异步方式的文件同步策略会产生同步延迟的问题,在文件访问时:文件更新会优先选择Storage server;文件下载时,tracker根据文件ID解析出时间戳最小的Storage server返回给Client。
客户端将一个文件上传到一台Storage server后,文件上传工作就结束了。由该Storage server根据binlog中的上传记录将这个文件同步到同组的其他Storage server。这样的文件同步方式是异步方式,异步方式带来了文件同步延迟的问题。新上传文件后,在尚未被同步过去的Storage server上访问该文件,会出现找不到文件的现象。FastDFS是如何解决文件同步延迟这个问题的呢?
文件的访问分为两种情况:文件更新和文件下载。文件更新包括设置文件附加属性和删除文件。文件的附加属性包括文件大小、图片宽度、图片高度等。FastDFS中,文件更新操作都会优先选择源Storage server,也就是该文件被上传到的那台Storage server。这样的做法不仅避免了文件同步延迟的问题,而且有效地避免了在多台Storage server上更新同一文件可能引起的时序错乱的问题。
那么文件下载是如何解决文件同步延迟这个问题的呢?
要回答这个问题,需要先了解文件名中包含了什么样的信息。Storage server生成的文件名中,包含了源Storage server的IP地址和文件创建时间等字段。文件创建时间为UNIX时间戳,后面称为文件时间戳。从文件名或文件ID中,可以反解出这两个字段。
然后我们再来看一下,Tracker server是如何准确地知道一个文件已被同步到一台Storage server上的。前面已经讲过,文件同步采用主动推送的方式。另外,每台storage server都会定时向tracker server报告它向同组的其他storage server同步到的文件时间戳。当tracker server收到一台storage server的文件同步报告后,它会依次找出该组内各个storage server(后称作为S)被同步到的文件时间戳最小值,作为S的一个属性记录到内存中。
7.2 FastDFS采取的解决方法
其一:一个最简单的解决办法,和文件更新一样,优先选择源Storage server下载文件即可。这可以在Tracker server的配置文件中设置,对应的参数名为download_server。
其二:另外一种选择Storage server的方法是轮流选择(round-robin)。当Client询问Tracker server有哪些Storage server可以下载指定文件时,Tracker server返回满足如下四个条件之一的Storage server:
1)该文件上传到的源Storage server,文件直接上传到该服务器上的
2)文件创建时间戳 < Storage server被同步到的文件时间戳,这意味着当前文件已经被同步过来了
3)文件创建时间戳=Storage server被同步到的文件时间戳,且(当前时间-文件创建时间戳) > 一个文件同步完成需要的最大时间(如5分钟);
4)(当前时间-文件创建时间戳) > 文件同步延迟阈值,比如我们把阈值设置为1天,表示文件同步在一天内肯定可以完成。
8 存在的问题
从FastDFS的整个设计看,基本上都已简单为原则。比如以机器为单位备份数据,简化了tracker的管理工作;storage直接借助本地文件系统原样存储文件,简化了storage的管理工作;文件写单份到storage即为成功、然后后台同步,简化了写文件流程。但简单的方案能解决的问题通常也有限,FastDFS目前尚存在如下问题。
8.1数据安全性
写一份即成功:从源storage写完文件至同步到组内其他storage的时间窗口内,一旦源storage出现故障,就可能导致用户数据丢失,而数据的丢失对存储系统来说通常是不可接受的。
缺乏自动化恢复机制:当storage的某块磁盘故障时,只能换存磁盘,然后手动恢复数据;由于按机器备份,似乎也不可能有自动化恢复机制,除非有预先准备好的热备磁盘,缺乏自动化恢复机制会增加系统运维工作。
数据恢复效率低:恢复数据时,只能从group内其他的storage读取,同时由于小文件的访问效率本身较低,按文件恢复的效率也会很低,低的恢复效率也就意味着数据处于不安全状态的时间更长。
缺乏多机房容灾支持:目前要做多机房容灾,只能额外做工具来将数据同步到备份的集群,无自动化机制。
8.2 存储空间利用率
单机存储的文件数受限于inode数量
每个文件对应一个storage本地文件系统的文件,平均每个文件会存在block_size/2的存储空间浪费。
文件合并存储能有效解决上述两个问题,但由于合并存储没有空间回收机制,删除文件的空间不保证一定能复用,也存在空间浪费的问题
8.3存储空间利用率
- 负载均衡
group机制本身可用来做负载均衡,但这只是一种静态的负载均衡机制,需要预先知道应用的访问特性;同时group机制也导致不可能在group之间迁移数据来做动态负载均衡。
9 参考资料
1 FastDFS为什么要结合Nginx
2 百度百科——fastdfs
3 分布式文件系统FastDFS架构剖析
4 分布式文件系统FastDFS设计原理
10 相关文章
1 Fastdfs 单节点安装使用教程整理
2 Nginx(Tenginx) 安装和命令
3 mysql索引总结----mysql 索引类型以及创建(转载)
20171109