本文分享的内容不但可以满足物联网领域同时还支持以下场景:
基于 Web 的聊天系统(点对点、群聊)。
Web 应用中需求服务端推送的场景。
基于 SDK 的消息推送平台。
技术选型
要满足大量的连接数、同时支持双全工通信,并且性能也得有保障。 在 Java 技术栈中进行选型首先自然是排除掉了传统 IO。
那就只有选 NIO 了,在这个层面其实选择也不多,考虑到社区、资料维护等方面最终选择了 Netty。
最终的架构图如下:

现在看着蒙没关系,下文一一介绍。
协议解析
既然是一个消息系统,那自然得和客户端定义好双方的协议格式。
常见和简单的是 HTTP 协议,但我们的需求中有一项需要是双全工的交互方式,同时 HTTP 更多的是服务于浏览器。我们需要的是一个更加精简的协议,减少许多不必要的数据传输。
因此我觉得最好是在满足业务需求的情况下定制自己的私有协议,在这个场景下有标准的物联网协议。
如果是其他场景可以借鉴现在流行的 RPC 框架定制私有协议,使得双方通信更加高效。
不过根据这段时间的经验来看,不管是哪种方式都得在协议中预留安全相关的位置。 协议相关的内容就不过多讨论了,更多介绍具体的应用。
简单实现
首先考虑如何实现功能,再来思考百万连接的情况。
注册鉴权
在做真正的消息上、下行之前首先要考虑的就是鉴权问题。 就像你使用微信一样,第一步怎么也得是登录吧,不能无论是谁都可以直接连接到平台。 所以第一步得是注册才行。
如上面架构图中的注册/鉴权模块。通常来说都需要客户端通过 HTTP 请求传递一个唯一标识,后台鉴权通过之后会响应一个 Token,并将这个 Token 和客户端的关系维护到 Redis 或者是 DB 中。
客户端将这个 Token 也保存到本地,今后的每一次请求都得带上这个 Token。一旦这个 Token 过期,客户端需要再次请求获取 Token。
鉴权通过之后客户端会直接通过 TCP 长连接到图中的 push-server 模块。 这个模块就是真正处理消息的上、下行。
保存通道关系
在连接接入之后,真正处理业务之前需要将当前的客户端和 Channel 的关系维护起来。
假设客户端的唯一标识是手机号码,那就需要把手机号码和当前的 Channel 维护到一个 Map 中。
这点和之前 Spring Boot 整合长连接心跳机制类似,如下图:

同时为了可以通过 Channel 获取到客户端唯一标识(手机号码),还需要在 Channel 中设置对应的属性:
public static void putClientId(Channel channel, String clientId) {
channel.attr(CLIENT_ID).set(clientId);
}
获取手机号码时:
public static String getClientId(Channel channel) {
return (String)getAttribute(channel, CLIENT_ID);
}
这样当我们客户端下线时便可以记录相关日志:
String telNo = NettyAttrUtil.getClientId(ctx.channel());
NettySocketHolder.remove(telNo);
log.info("客户端下线,TelNo=" + telNo);
这里有一点需要注意: 存放客户端与 Channel 关系的 Map 最好是预设好大小(避免经常扩容),因为它将是使用最为频繁同时也是占用内存最大的一个对象。
消息上行
接下来则是真正的业务数据上传,通常来说第一步是需要判断上传消息输入什么业务类型。 在聊天场景中,有可能上传的是文本、图片、视频等内容。
所以我们得进行区分,来做不同的处理,这就和客户端协商的协议有关了:
可以利用消息头中的某个字段进行区分。
更简单的就是一个 JSON 消息,拿出一个字段用于区分不同消息。
不管是哪种只要可以区分出来即可。
消息解析与业务解耦
消息可以解析之后便是处理业务,比如可以是写入数据库、调用其他接口等。
我们都知道在 Netty 中处理消息一般是在 channelRead() 方法中。
在这里可以解析消息,区分类型。 但如果我们的业务逻辑也写在里面,那这里的内容将是巨多无比。
甚至我们分为好几个开发来处理不同的业务,这样将会出现许多冲突、难以维护等问题。所以非常有必要将消息解析与业务处理完全分离开来。
这时面向接口编程就发挥作用了。这里的核心代码和 「造个轮子」——cicada(轻量级 Web 框架) 是一致的。
都是先定义一个接口用于处理业务逻辑,然后在解析消息之后通过反射创建具体的对象执行其中的处理函数即可。
这样不同的业务、不同的开发人员只需要实现这个接口同时实现自己的业务逻辑即可。
伪代码如下:


想要了解 cicada 的具体实现请点击这里:
https://github.com/TogetherOS/cicada
上行还有一点需要注意: 由于是基于长连接,所以客户端需要定期发送心跳包用于维护本次连接。
同时服务端也会有相应的检查,N 个时间间隔没有收到消息之后,将会主动断开连接节省资源。
这点使用一个 IdleStateHandler 就可实现。
消息下行
有了上行自然也有下行。比如在聊天的场景中,有两个客户端连上了 push-server,它们直接需要点对点通信。
这时的流程是:
A 将消息发送给服务器。
服务器收到消息之后,得知消息是要发送给 B,需要在内存中找到 B 的 Channel。
通过 B 的 Channel 将 A 的消息转发下去。
这就是一个下行的流程。 甚至管理员需要给所有在线用户发送系统通知也是类似:遍历保存通道关系的 Map,挨个发送消息即可。这也是之前需要存放到 Map 中的主要原因。
伪代码如下:

具体可以参考:
https://github.com/crossoverJie/netty-action/
分布式方案
单机版的实现了,现在着重讲讲如何实现百万连接。
百万连接其实只是一个形容词,更多的是想表达如何来实现一个分布式的方案,可以灵活的水平拓展从而能支持更多的连接。在 做这个事前,首先得搞清楚我们单机版的能支持多少连接。
影响这个的因素就比较多了:
服务器自身配置 。内存、CPU、网卡、Linux 支持的最大文件打开数等。
应用自身配置。 因为 Netty 本身需要依赖于堆外内存,但是 JVM 本身也是需要占用一部分内存的,比如存放通道关系的大 Map。这点需要结合自身情况进行调整。
结合以上的情况可以测试出单个节点能支持的最大连接数。 单机无论怎么优化都是有上限的,这也是分布式主要解决的问题。
架构介绍
在讲具体实现之前首先得讲讲上文贴出的整体架构图:

先从左边开始。 上文提到的注册鉴权模块也是集群部署的,通过前置的 Nginx 进行负载。之前也提过了它主要的目的是来做鉴权并返回一个 Token 给客户端。
但是 push-server 集群之后它又多了一个作用。那就是得返回一台可供当前客户端使用的 push-server。
右侧的平台一般指管理平台,它可以查看当前的实时在线数、给指定客户端推送消息等。 推送消息则需要经过一个推送路由(push-server)找到真正的推送节点。
其余的中间件如: Redis、ZooKeeper、Kafka、MySQL 都是为了这些功能所准备的,具体看下面的实现。
注册发现
首先第一个问题则是 注册发现,push-server 变为多台之后如何给客户端选择一台可用的节点是第一个需要解决的。
这块的内容其实已经在 分布式(一) 搞定服务注册与发现中详细讲过了。 所有的 push-server 在启动时候需要将自身的信息注册到 ZooKeeper 中。
注册鉴权模块会订阅 ZooKeeper 中的节点,从而可以获取最新的服务列表,结构如下:

以下是一些伪代码:应用启动注册 ZooKeeper。
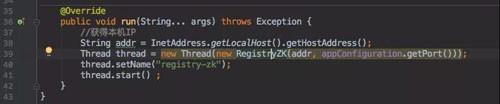

对于注册鉴权模块来说只需要订阅这个 ZooKeeper 节点:
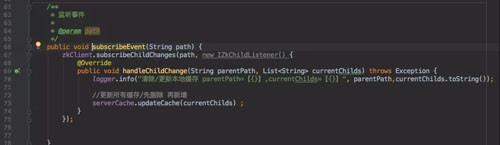
路由策略
既然能获取到所有的服务列表,那如何选择一台刚好合适的 push-server 给客户端使用呢?
这个过程重点要考虑以下几点:
尽量保证各个节点的连接均匀。
增删节点是否要做 Rebalance。
首先保证均衡有以下几种算法:
轮询。 挨个将各个节点分配给客户端。但会出现新增节点分配不均匀的情况。
Hash 取模的方式。 类似于 HashMap,但也会出现轮询的问题。当然也可以像 HashMap 那样做一次 Rebalance,让所有的客户端重新连接。不过这样会导致所有的连接出现中断重连,代价有点大。
由于 Hash 取模方式的问题带来了一致性 Hash 算法,但依然会有一部分的客户端需要 Rebalance。
权重。 可以手动调整各个节点的负载情况,甚至可以做成自动的,基于监控当某些节点负载较高就自动调低权重,负载较低的可以提高权重。
还有一个问题是: 当我们在重启部分应用进行升级时,在该节点上的客户端怎么处理?
由于我们有心跳机制,当心跳不通之后就可以认为该节点出现问题了。那就得重新请求注册鉴权模块获取一个可用的节点。在弱网情况下同样适用。
如果这时客户端正在发送消息,则需要将消息保存到本地等待获取到新的节点之后再次发送。
有状态连接
在这样的场景中不像是 HTTP 那样是无状态的,我们得明确的知道各个客户端和连接的关系。
在上文的单机版中我们将这个关系保存到本地的缓存中,但在分布式环境中显然行不通了。
比如在平台向客户端推送消息的时候,它得首先知道这个客户端的通道保存在哪台节点上。
借助我们以前的经验,这样的问题自然得引入一个第三方中间件用来存放这个关系。
也就是架构图中的存放路由关系的 Redis,在客户端接入 push-server 时需要将当前客户端唯一标识和服务节点的 ip+port 存进 Redis。
同时在客户端下线时候得在 Redis 中删掉这个连接关系。这样在理想情况下各个节点内存中的 Map 关系加起来应该正好等于 Redis 中的数据。
伪代码如下:
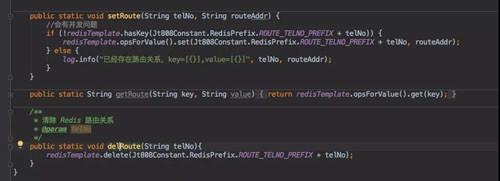
这里存放路由关系的时候会有并发问题,最好是换为一个 Lua 脚本。
推送路由
设想这样一个场景:管理员需要给最近注册的客户端推送一个系统消息会怎么做?
结合架构图,假设这批客户端有 10W 个,首先我们需要将这批号码通过平台下的 Nginx 下发到一个推送路由中。
为了提高效率甚至可以将这批号码再次分散到每个 push-route 中。 拿到具体号码之后再根据号码的数量启动多线程的方式去之前的路由 Redis 中获取客户端所对应的 push-server。
再通过 HTTP 的方式调用 push-server 进行真正的消息下发(Netty 也很好的支持 HTTP 协议)。
推送成功之后需要将结果更新到数据库中,不在线的客户端可以根据业务再次推送等。
消息流转
也许有些场景对于客户端上行的消息非常看重,需要做持久化,并且消息量非常大。
在 push-sever 做业务显然不合适,这时完全可以选择 Kafka 来解耦。 将所有上行的数据直接往 Kafka 里丢后就不管了。再由消费程序将数据取出写入数据库中即可。
分布式问题
分布式解决了性能问题但却带来了其他麻烦。
应用监控
比如如何知道线上几十个 push-server 节点的健康状况? 这时就得监控系统发挥作用了,我们需要知道各个节点当前的内存使用情况、GC。
以及操作系统本身的内存使用,毕竟 Netty 大量使用了堆外内存。 同时需要监控各个节点当前的在线数,以及 Redis 中的在线数。理论上这两个数应该是相等的。
这样也可以知道系统的使用情况,可以灵活的维护这些节点数量。
日志处理
日志记录也变得异常重要了,比如哪天反馈有个客户端一直连不上,你得知道问题出在哪里。
最好是给每次请求都加上一个 traceID 记录日志,这样就可以通过这个日志在各个节点中查看到底是卡在了哪里。 以及 ELK 这些工具都得用起来才行。
总结
本次是结合我日常经验得出的,有些坑可能在工作中并没有踩到,所以还会有一些遗漏的地方。
就目前来看想做一个稳定的推送系统是比较麻烦的,其中涉及到的点非常多,只有真正做过之后才会知道。
这里推荐一下我的Java后端高级技术群:479499375,群里有(Java高架构、分布式架构、高可扩展、高性能、高并发、性能优化、Spring boot、Redis、ActiveMQ、等学习资源)进群免费送给每一位Java小伙伴,不管你是转行,还是工作中想提升自己能力都可以!