本文由 沈庆阳 所有,转载请与作者取得联系!
TensorFlow相关概念
计算图(Graph)
计算图是TensorFlow中最基本的一个概念。在TensorFlow的程序中,所有的计算操作都会被转化为一张计算图上面的一个节点。使用TensorBoard可以清晰地查看TensorFlow程序生成的计算图。
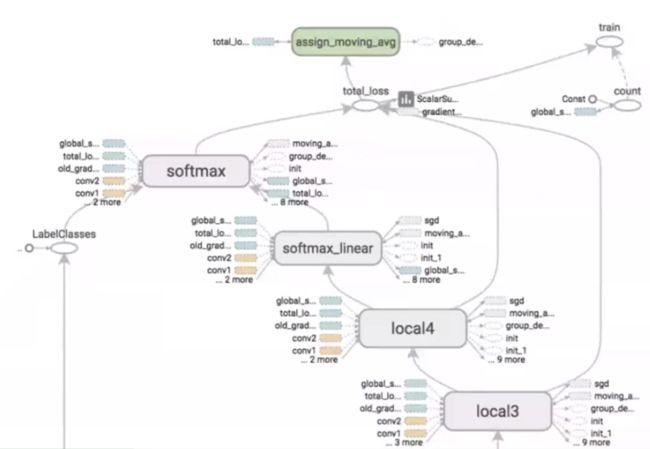
计算图的使用
TensorFlow的程序一般分为2个部分。第一个部分是定义部分,其定义了计算图中所有的计算。第二个部分则是运行部分,在该部分执行计算。如求a,b两个变量的和,在TensorFlow的程序中代码如下:
a = tf.constant([1.0, 2.0], name='a')
b = tf.constant([3.0, 4.0], name='b')
result = tf.add(a, b, name='add')
上述代码中的tf是通过import tensorflow as tf得来的。
在TensorFlow的程序运行过程中,其会自动维护一个默认的计算图,这个计算图可以通过调用函数tf.get_default_graph函数来获得。在程序中,通过使用print(a.graph is tf.get_default_graph)来判断当前a张量属于的计算图是否是默认的计算图,其输出的是一个布尔值。
TensorFlow还支持通过调用tf.Graph函数来生成新的计算图。注意,属于不同的计算图上的张量以及运算操作不共享。
TensorFlow计算图创建与定义变量的示例:
# 创建计算图g1,并在其中定义张量v,初始值为0.
g1 = tf.Graph()
with g1.as_default():
v = tf.get_variable('v', initializer = tf.zeros_initializer(shape=[1]))
# 创建计算图g2,并在其中定义张量v,初始值为1.
g2 = tf.Graph()
with g2.as_default():
v = tf.get_variable('v', initializer = tf.ones_initializer(shape=[1]))
TensorFlow中计算图读取张量的示例:
# 读取计算图g1中的变量v的值
with tf.Session(graph=g1) as sess:
tf.global_variables_initializer().run()
with tf.variable_scope('', reuse=True):
print(sess.run(tf.get_variable('v')))
# 读取计算图g2中的变量v的值
with tf.Session(graph=g2) as sess:
tf.global_variables_initializer().run()
with tf.variable_scope('', reuse=True):
print(sess.run(tf.get_variable('v')))
由于计算图g1中的v的值是0,g2中的v的值是1,因此上述程序的输出应该是:
[0.]
[1.]
张量(Tensor)
TensorFlow的名字也来源于张量。在TensorFlow中,所有的数据都是以张量的形式来表示的。简单的说,张量就是一个多维数组,但其在TensorFlow中的存储并非以数组的形式来存储的。张量并未真正地保存数值,而是保存的如何得到数值的计算过程。以简单地加法(add)运算为例:
a = tf.constant([1.0, 2.0], name='a')
b = tf.constant([3.0, 4.0], name='b')
result = tf.add(a, b, name='add')
print(result)
其输出为:
Tensor("add:0", shape=(2,), dtype=float32)
很显然,result是一个张量,这从程序的输出便能看得出。此外,我们还能从输出得到其他的信息:一个张量有3个属性。第一,张量的名称(name);第二,张量的维度(shape);第三,张量的类型(type)。
张量result的名称为'add',而输出的结果'add:0'指的是result节点'add'输出的第一个结果。张量的属性名称并不是张量的唯一的标识符,其名称也表明了这个张量是如何计算而来的。张量的命名方式为'node:src_output',其中node为节点的名称,src_output指明当前张量来自节点的第几个输出(从0开始计数)。
张量的维度(shape)表明了张量的维度信息。上述result输出的shape=(2,)表示的是长度为2的一维数组。
最后便是类型,每个张量的类型都是唯一的。如果出现类型不匹配则会报错,这个错误在TensorFlow的程序中很常见。举例,如果将上述的程序改为如下形式:
a = tf.constant([1, 2], name='a')
b = tf.constant([3.0, 4.0], name='b')
result = tf.add(a, b, name='add')
运行上面的代码则会报错
TypeError: Input 'y' of 'Add' Op has type float32 that does not match type int32 of argument 'x'.
很明显,我们的a张量是int32型的,而b是float32型的,不同的类型无法进行运算操作。如果将a = tf.constant([1, 2], name='a')进行简单修改,声明其张量类型a = tf.constant([1, 2], name='a', dtype=tf.float32)那么程序就可以运行了。
TensorFlow有14种不同的类型,而最常见的有实数(float32、float64)、整数(int8、int16、int32、int64和uint8)、布尔型(bool)和复数(complex64、complex128)。
会话(Session)
在一个TensorFlow的程序中,我们定义好了变量和计算之后,需要通过会话来执行运算。会话拥有并负责管理TensorFlow运行时的所有资源。在会话运行结束之后,需要调用sess.close()来关闭会话从而释放会话中占用的资源(内存、显存等),如果没有做到的话则会产生资源泄露等问题。
通过Python的上下文管理器来使用会话则省去了关闭会话的操作,实现代码如下:
with tf.Session() as sess
sess.run()
...
通过这种方式来创建对话Python的上下文管理器会在程序退出时自动释放所有占用的资源。而且,当程序异常退出/崩溃时,Python也会自动释放资源,因此提倡用这种方式来创建Session。
在TensorFlow的程序中会生成一个默认的计算图,如果没有对运算进行特别指定的话,那么运算则会自动加入到这个计算图当中。通过tf.Tensor.eval函数可以计算一个张量的取值,例子如下:
sess = tf.Session()
with sess.as_default():
print(result.eval())
有很多TensorFlow的程序是写在Jupyter Notebook中,或在交互式的Python Shell中运行,此时通过tf.InteractiveSession来构建默认会话则会更加方便。使用tf.InteractiveSession可以省去将会话注册为默认会话的过程。
TensorFlow提供了通过ConfigProto Protocol Buffer来配置生成的会话的方法。使用ConfigProto配置会话的例子如下:
config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)
# 生成两种会话
sess1 = tf.InteractiveSession(config=config)
sess2 = tf.Session(config=config)
ConfigProto可以配置的的参数很多,如GPU分配的策略、并行的线程数、运算超过时间等。其中,allow_soft_placement与log_device_placement最为常用。
allow_soft_placement决定着程序是否可以在CPU上运行。当其取值为True时:当程序无法在GPU上运行时、指定GPU不存在或运算输入包含对CPU计算结果的引用,上述三个条件满足其一时,GPU上的运算可以放到CPU上运行。通常allow_soft_placement会设置为True,这是为了让程序可以在某些运算GPU不支持的时候自动调整到CPU上运行,而不是报错。
第二个参数log_device_placement设置为True的时候日志中则会记录每个节点被安排在哪个设备上,以方便调试。
使用TensorFlow实现简单的神经网络
在从零开始机器学习-16 初探神经网络(Neural Network)和从零开始机器学习-17 神经网络的训练过程中,介绍了关于神经网络的前向传播算法和反向传播算法。在这里,我们尝试用TensorFlow来实现神经网络的前向传播和反向传播,搭建一个完整的神经网络。
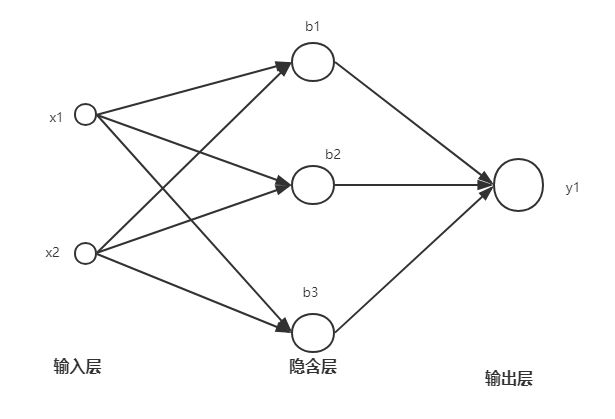
我们的目标是实现上图的神经网络模型。这个神经网络有2个输入,x1和x2;1个输出y1。在上面的模型中,每个箭头上都有一个权重值,在这里没有标出。关于神经网络的前向传播算法在这里不再赘述。
我们将输入层连接到隐藏层神经元的权重以矩阵的形式表示出来,命名为W1,将隐藏层连接到输入层的权重命名为W2,输入层矩阵命名为X。这样,W1是一个2*3的矩阵,W2是一个1*3的矩阵,X是一个1*2的矩阵。由此,用TensorFlow来表示前向传播结果的代码如下:
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
矩阵的乘法在TensorFlow中使用tf.matmul函数来实现。
TensorFlow与神经网络参数
在神经网络中,参数的初始值通常是随机数。TensorFlow的变量tf.Variable的作用则是保存和更新神经网络中的参数。TensorFlow具有如下的随机数生成函数:
| 函数名 | 随机数分布方式 | 参数 |
|---|---|---|
| tf.random_normal | 正态分布 | 平均值、标准差、取值类型 |
| tf.truncated_normal | 正态分布,但随机数如果超过2倍标准差则重新随机 | 平均值、标准差、取值类型 |
| tf.random_uniform | 平均分布 | 最小、最大值、取值类型 |
| tf.randon_gamma | Gamma分布 | 形状参数Alpha、尺度参数Beta、取值类型 |
除了随机生成之外,TensorFlow还支持使用常数来填充:
| 函数名 | 功能 | 例子 |
|---|---|---|
| tf.zeros | 生成全是0的数组 | tf.zeros([2, 3], int32) -> [[0, 0, 0], [0, 0, 0]] |
| tf.ones | 生成全是1的数组 | tf.ones([2, 3], int32) -> [[1, 1, 1], [1, 1, 1]] |
| tf.fill | 使用特定数字填充 | tf.fill([2, 3], 2) -> [[2, 2, 2], [2, 2, 2]] |
| tf.constant | 产生一个给定的常量 | tf.constant([1, 2]) -> [1, 2] |
在TensorFlow中,给神经网络权重初始值的示例如下:
weights = tf.Variable(tf.randon_normal([2, 3], stddev=2))
TensorFlow还支持通过其他变量的初始值来初始化新的变量:
w1 = tf.Variable(weights.initialized_value())
w2 = tf.Variable(weights.initialized_value() * 2)
上述代码中,w1使用了weights的初始值来初始化,w2使用了2倍的weights的初始值进行初始化。
综上,前向传播的算法,在TensorFlow中的代码如下:
import tensorflow as tf
# 声明w1和w2两个变量,正态分布随机数填充
w1 = tf.Variable(tf.random_normal((2, 3), mean=0, stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal((3, 1), mean=0, stddev=1, seed=1))
# 将输入特征先用常量定义
x = tf.constant([[0.5, 0.6]])
# 前向传播
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
# 初始化变量并运行
with tf.Session() as sess:
sess.run(w1.initializer)
sess.run(w2.initializer)
print(sess.run(y))
在上述代码中,可以看到在计算输出Y之前,我们需要给w1和w2分别执行初始化操作。在一个简单的神经网络中,我们也许只需要执行两三次,但当一个网络十分庞大,参数十分巨大的时候,这样便变得十分繁琐,使得代码维护性变差。因此,TensorFlow提供了tf.global_Variable_initializer函数来实现所有变量的初始化。这样一来,上面的两句初始化w1和w2的语句就可以精简为如下:
init_op = tf.global_Variable_initializer()
sess.run(init_op)
TensorFlow实现神经网络训练过程
神经网络的训练过程简言之就是设置神经网络参数的过程。
让我们再来回顾一下反向传播算法:
算法过程:
1:在(0,1)区间内随机初始化网络中的所有连接权值和阈值
2:repeat
3: for all (xk,yk) ∈ D do
4: 根据当前参数和公式计算输出
5: 计算输出层神经元的梯度项gj
6: 计算隐藏层神经元的梯度项eh
7: 计算和更新连接权值ωhj、νih和阈值θj γh
8: end for
9:until 达到停止训练的条件
在每次迭代开始的时候,我们需要选取训练数据。而对于训练数据的选取,通常选择整个数据集中的一小部分,这一小部分也叫作Batch。选择好Batch之后,通过前向传播得到神经网络的预测结果,通过预测与真实情况的差距来决定如何更新参数。
在前面实现前向传播算法的时候,我们使用了tf.constant来给特征赋值,当然这只是权宜之计。因为面对几十个常量来说还好,但一个数据集通常都是巨大的,如果使用tf.constant则会占用大量的资源,造成程序无法运行。幸运的是,TensorFlow提供了解决方案。
TensorFlow提供了placeholder占位符来提供数据的输入。placeholder定义的是一个位置,至于这个位置的数据则是在程序运行的时候再给出。这样,输入数据占用的资源也就要少了很多。在定义placeholder的时候,需要指定这个位置的数据类型,这个数据类型与张量的定义一样是不可以改变的。placeholder的维度信息可以根据提供的数据推导出,因此不一定需要提前指定。我们再使用placeholder将前向传播算法实现一遍:
import tensorflow as tf
# 声明w1和w2两个变量,正态分布随机数填充
w1 = tf.Variable(tf.random_normal((2, 3), mean=0, stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal((3, 1), mean=0, stddev=1, seed=1))
# 将输入特征用placeholder指定
x = tf.placeholder(tf.float32, shape=(1, 2), name='input')
# 前向传播
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
# 初始化变量并运行
with tf.Session() as sess:
# 全局 变量初始器
init_op = tf.global_variables_initializer()
sess.run(init_op)
print(sess.run(y, feed_dict={x: [[0.5, 0.6]]}))
在sess.run(y, feed_dict={x: [[0.5, 0.6]]})中,我们不再像上一个程序一样直接使用sess.run(y)便可以得到结果,而是需要通过feed_dict给输入指定值。feed_dict是一个字典,在字典中需要给出每个placeholder的取值。
上述字典向placeholder输入的是一个1*2的矩阵,如果我们输入2个、3个或以上的数据时,可以这样写:
feed_dict={x:[[0.1, 0.2], [0.3, 0.4], [0.5, 0.6]]}
对于反向传播算法,我们得到一个训练集的Batch之后,需要使用损失函数来评价当前的预测值与实际的差距,然后再调整神经网络的参数。在TensorFlow中的反向传播算法表示如下:
# 将输出y通过S函数映射到0到1上
y = tf.sigmoid(y)
# 定义交叉熵来作为损失函数
cross_entropy = - tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0))
+ (1-y) * tf.log(tf.clip_by_value(1-y, 1e-10, 1.0)))
learning_rate = 0.001
# 定义BP算法的优化参数
train_step = tf.train.AdadeltaOptimizer(learning_rate).minimize(cross_entropy)
TensorFlow实现的神经网络代码
在TensorFlow的程序中,实现神经网络算法的步骤主要如下:
1、定义神经网络的结构和前向传播的结果
2、定义损失函数和反向传播优化算法
3、生成会话并迭代运行反向传播算法
完整的TensorFlow实现的神经网络的代码如下:
import tensorflow as tf
# 使用Numpy的随机数生成训练数据
from numpy.random import RandomState
# 批量大小
batch_size = 16
# 学习速率
learning_rate = 0.001
# 设定训练多少轮
STEPS = 10000
# 声明w1和w2两个变量,正态分布随机数填充
w1 = tf.Variable(tf.random_normal((2, 3), mean=0, stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal((3, 1), mean=0, stddev=1, seed=1))
# 将输入特征用placeholder指定
x = tf.placeholder(tf.float32, shape=(None, 2), name='x-input')
y_ = tf.placeholder(tf.float32, shape=(None, 1), name='y-input')
# 前向传播过程
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
# 反向传播过程
# 将输出y通过S函数映射到0到1上
y = tf.sigmoid(y)
# 定义交叉熵来作为损失函数
cross_entropy = - tf.reduce_mean(y * tf.log(tf.clip_by_value(y, 1e-10, 1.0))
+ (1-y) * tf.log(tf.clip_by_value(1-y, 1e-10, 1.0)))
# 定义BP算法的优化参数
train_step = tf.train.AdadeltaOptimizer(learning_rate).minimize(cross_entropy)
# 生成一个训练数据集
rand = RandomState(1)
dataset_size = 512
X = rand.rand(dataset_size, 2)
# 如果x1+x2<1则为正样本,反之为负样本。使用1代表正样本,0代表负样本。
Y = [[int(x1 + x2 < 1)] for (x1, x2) in X]
# 初始化变量并运行
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
print('训练之前的权重值为:')
print(sess.run(w1))
print(sess.run(w2))
for i in range(STEPS):
# 选取训练样本
start = (i * batch_size) % dataset_size
end = min(start + batch_size, dataset_size)
# 训练神经网络并更新参数
sess.run(train_step,
feed_dict={x: X[start:end], y_: Y[start:end]})
if i % 1000 == 0:
# 每隔一段时间计算交叉熵并输出
total_cross_entropy = sess.run(cross_entropy,
feed_dict={x: X, y_: Y})
print('在训练%d步后,总交叉熵为%g' % (i, total_cross_entropy))
print('训练完成之后的权重值为:')
print(sess.run(w1))
print(sess.run(w2))
运行输出结果如下:
2018-07-06 14:45:08.802697: I C:\tf_jenkins\workspace\tf-nightly-windows\M\windows\PY\36\tensorflow\core\platform\cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
训练之前的权重值为:
[[-0.8113182 1.4845988 0.06532937]
[-2.4427042 0.0992484 0.5912243 ]]
[[-0.8113182 ]
[ 1.4845988 ]
[ 0.06532937]]
在训练0步后,总交叉熵为0.297232
在训练1000步后,总交叉熵为0.296764
在训练2000步后,总交叉熵为0.29613
在训练3000步后,总交叉熵为0.295387
在训练4000步后,总交叉熵为0.294566
在训练5000步后,总交叉熵为0.293689
在训练6000步后,总交叉熵为0.292765
在训练7000步后,总交叉熵为0.291805
在训练8000步后,总交叉熵为0.290816
在训练9000步后,总交叉熵为0.289806
训练完成之后的权重值为:
[[-0.82267827 1.4959371 0.07675438]
[-2.454002 0.11048034 0.60258645]]
[[-0.82463264]
[ 1.4965477 ]
[ 0.07755461]]
可以看到,经过简单的训练之后,训练之前和训练之后的权重不同,交叉熵也稍微降低了。
觉得写的不错的朋友可以点一个 喜欢♥ ~
谢谢你的支持!