1、HDFS(Hadoop Distributed File System) 分布式文件存储系统,批处理、高吞吐量而非低延迟。它只支持文件追加和删除(一次写多次读),应用距离数据越近,操作速度越快。
2、HDFS三大守护进程(deamon processe)
NameNode :
A:NameNode是HDFS的命名空间,里面存储着整个HDFS的所有文件的元数据信息,这些信息都会加载到内存中,元数据信息分为两部分,第一部分是文件系统树及整棵树内所有的文件和目录,第二部分是每个文件的各个组成块所在的数据节点信息。第一部分会落地形成文件(命名空间镜像文件和编辑日志文件)永久保存,第二部分的信息是在HDFS启动时,DataNode自动报送给NameNode,所以这个不会永久保存。元数据格式如下(/test/a.log是在hdfs文件系统中的路径,3是这个文件的副本数(副本数可以通过在配置文件中的配置来修改的)。在hdfs中,文件是进行分块存储的,如果文件过大,就要分成多块存储,每个块在文件系统中存储3个副本,以上图为例,就是分成blk_1和blk_2两个块,每个块在实际的节点中有3个副本,比如blk_1的3个副本分别存储在h0,h1,h3中)

此时存在一个问题,随着文件数目的增加,NameNode存在内存中的信息也越来越大,如何保证内存不溢出?
DataNode :
负责存储数据,最小的单位是block , 默认的bocksize=128M , 若文件258M,则共有block=3,实际占有存储258M,最后一块 只占用2M。每个DataNode最多存储的块数=(repication-1)/ (机架数+2),放置位置随机。
每隔3秒向NameNode发一次心跳,每隔dfs.blockreport.intervalMsec=6h(默然单位ms)向NameNode发送一次blockReport,
心跳:DataNode向NameNode报告自身信息,如DataNode容量,DataNode DFS容量等,然后NameNode向DataNode返 回DataNode Command,控制DataNode进行一些操作。
dfs.heartbeat.interval = 3s , heartbeat.recheck.interval = 300000ms (重新检查时间)
与DataNode连接超时时间= heartbeat*10 + recheck*2,
sendHeartbeat的具体实现:
1. 首先从datanodeMap中获取发送“心跳”的datanodeDescriptor。在获取的过程中,如果datanodeMap获取的Datanode的hostname与正在发送“心跳”的Datanode的hostname不一致,则抛出异常,并向该Datanode返回DNA_REGISTER 命令。
2. 如果从datanodeMap中获取的DatanodeDescriptor不为空,但是该Datanode的是需要shutdown的节点,则将该节点置为dead。
3. 如果获取的DatanodeDescriptor为空,或者DataNodeDescriptor的状态为not live,则向并向该Datanode返回DNA_REGISTER 命令。
4. 如果DatanodeDescriptor正常,则更新FSNamespace以及DatanodeDescriptor的状态,主要包括capacity、dfsUsed、remaining和xceiverCount。
5. 然后,依次获取DNA_RECOVERBLOCK 、DNA_TRANSFER、DNA_INVALIDATE、KeyUpdateCommand、BalancerBandwidthCommand执行命令返回给Datanode。
6. 最后,判断是不是有UpgradeCommand命令,如果有返回给Datanode进行执行。
追加内容后块的变化,怎么追加,怎么重新设置块大小和replication数目。
SecondaryNameNode :
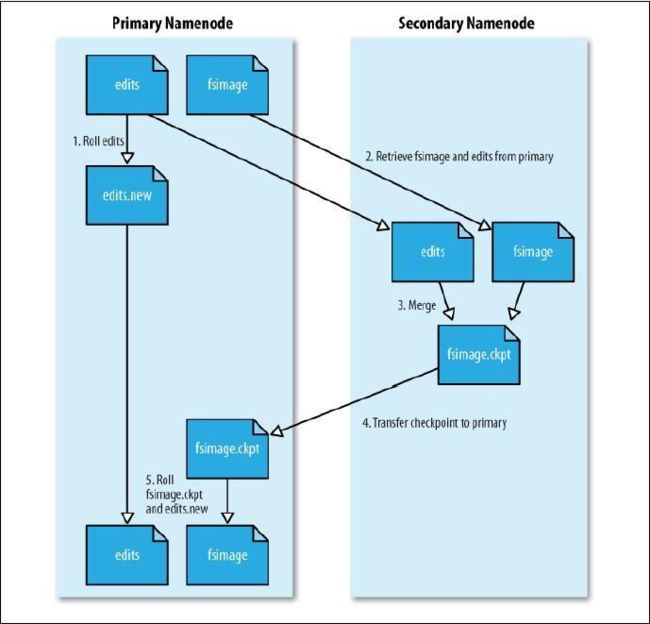
fsimage : 存储NameNode元数据的镜像文件
edits : 存储NameNode的操作日志
fstime : 保存最近一次的checkpoint时间 , checkpoint为fstime和edits文件的合并时间点
检查点:core-site.xml fs.checkpoint.period=3600(s) 或者 fs.checkpoint.size=64(M) (edits文件)
(1)检查点到来时,NameNode 生成edits.new文件记录新的操作日志(元数据操作),
(2)原edits文件和fsimage文件下载到本地,在内存中合并为fsimage.ckpt文件
(3)DataNode通知NameNode文件fsimage.ckpt已生成,NameNode下载fsimage.ckpt,并替换为fsimage
(4)edit.new文件替换为edit文件
如何恢复NameNode
HDFS架构总图
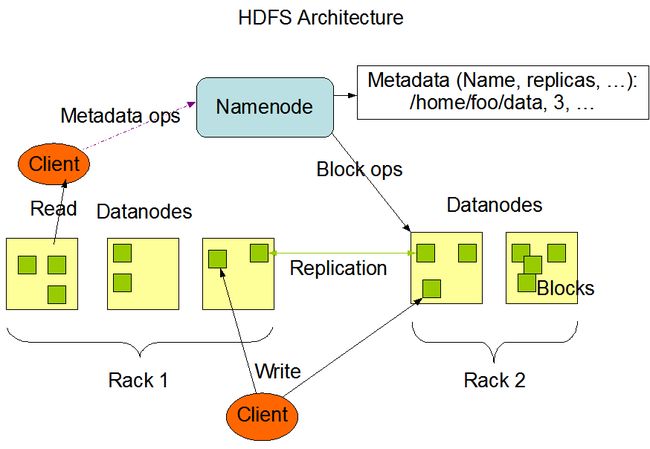
(1) Client与NameNode通信,NameNode获取数据信息,供Client进行读写操作。