转载自:https://hackernoon.com/spotifys-discover-weekly-how-machine-learning-finds-your-new-music-19a41ab76efe,有删节。
【嵌牛导读】:AI 时代音乐 App 的个人推荐系统背后有着什么样的技术?本文将以 Spotify 为例为你作出解答。
【嵌牛鼻子】:音乐app 每周推荐 协同过滤模型 NLP模型
【嵌牛提问】:每周推荐有什么数学模型?如何更加精准?
【嵌牛正文】:
在线音乐 App 发展简史

21 世纪初,Songza 开启了在线音乐服务时代,那个时候,App 还是通过人工管理为用户提供播放列表的。「人工管理」意味着存在一个「音乐专家」团队或其他监管者在挑选歌曲编写播放列表,而用户拿到的歌单多少取决于个人喜好(后来,Beats Music 也使用了相同的策略)。手工编辑的歌单本身没有问题,但它们很难符合每位用户的音乐喜好。
和 Songza 一样,Pandora 也是在线音乐服务的元老之一,它使用了稍稍先进一些的方法来代替手动编出的歌单——标记歌曲风格。通过让听完音乐的用户为每首歌打上标签,Pandora 可以简单地通过筛选标签的方式来制作播放列表。
与此同时,在著名的 MIT Media Lab 中,Echo Nest 诞生了,它是一个更为先进的个性化音乐推荐系统。Echo Nest 使用算法分析歌曲的声音和文本内容,这意味着它可以完成音乐识别、个性化推荐、创建歌单和分析等功能。
最后,Last.fm 又采用了另一种方法并一直沿用到了今天,这种被称为「协同过滤」的方法与其他方法略有不同。
以上是大多数其他流媒体音乐服务采用的推荐形式,Spotify 神奇的推荐引擎似乎比其他方法更加准确,后者是如何做到的呢?
Spotify 的两种推荐模型
Spotify 其实并没有发展出依靠单一算法的推荐模型——它参考了其他服务采用的方法,并整合出了自己的最佳策略,构建了名为 Discovery 的引擎。
为了创建 Discovery Weekly 歌单,Spotify 主要使用了三种推荐系统:
协同过滤模型(与 Last.fm 使用的类似),通过分析你的行为和其他用户的行为来工作。
自然语言处理(NLP)模型,通过分析文本来工作。
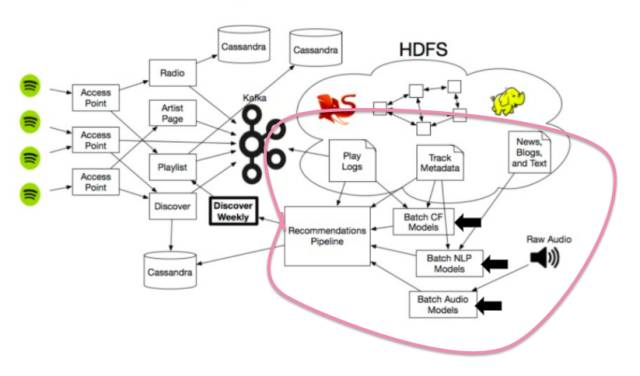
让我们来深入了解一下这些推荐模式的运作方式吧。
推荐模型 #1:协同过滤
什么是协同过滤?它是如何工作的?简而言之,就像 Daft Punk 所演示的

这里面发生了什么?两个人都有一些自己喜欢的歌,左边那位喜欢 P、Q、R 和 S,右边那位喜欢 Q、R、S 和 T。
协同过滤使用以上数据我们可以这样认为:
「看来你们都喜欢 Q、R 和 S,所以你们很可能是相同类型的用户。所以你们应该听听对方喜欢——而自己没听过的那几首歌。」
所以我们应该给 Thomas(左)推荐歌曲 P,给 Guy-Manuel(右)推荐歌曲 T,很简单是不是。
但是把这个方法套用在 Spotify 上,实际上需要分析的是数百万用户的喜好,推荐的也是数百万用户的歌单,所以我们需要用上 Python 库。
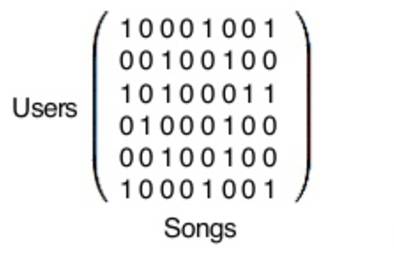
在这里,你看到的矩阵是庞大的。每一行代表 Spotify 的 1.4 亿用户的一个(如果你是 Spotify 的用户,你在里面有自己的位置),每一列代表 Spotify 3000 万歌曲库里的一首。
在矩阵交点处,当某用户听过一首歌后标记为 1,否则为 0。如果我听了Michael Jackson 的《Thriller》,那么在我这行里代表 Thriller 的位置会标记为 1。(注意:Spotify 已经在尝试让其中的数字更加复杂,不再仅限 1 和 0)
随后我们得到了一个非常稀疏的矩阵——所有人听过的歌都没有未听过的歌多,所以这个矩阵的大部分位置都会被「0」填充。但是,少量的「1」包含着决定性的信息。
随后,Python 库会运行下面这个公式:
当这项工作完成后,我们会得到两种类型的向量,分别由 X 和 Y 来代表。X 是用户向量,代表一个用户的歌曲喜好,Y 是歌曲向量,代表一首歌的热度。
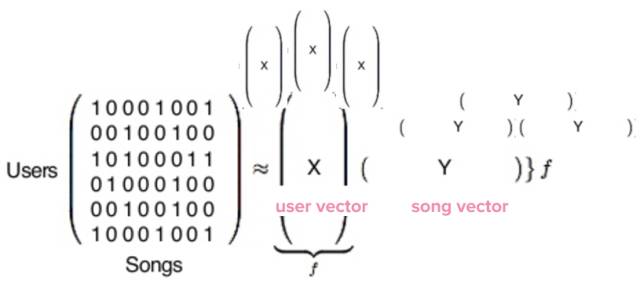
用户/歌曲矩阵产生两种类型的向量:用户向量和歌曲向量。
现在我们拥有了 1.4 亿个用户向量和 3000 万歌曲向量了。它们本身只是一些数字,但我们可以使用它们来进行很多比较。为了使用这些数据找到与我相近的用户,协同过滤使用点积比较了我的向量与所有其他用户的向量。同样的事情也发生在歌曲向量上,你可以用这种方法来找同类型的歌曲。
协同过滤是一个不错的方法,不过 Spotify 还要做得更好。
推荐模型 #2:自然语言处理(NLP)
Spotify 采用的第二种推荐模型是自然语言处理(NLP)模型。顾名思义,这种模型的数据源来自元数据、新闻、博客、评论和网络上能找到的其他各种文本。

自然语言处理是让计算机理解人类语言含义的技术,在业界通常通过情绪分析 API 来实现,NLP 是人工智能下的一个庞大领域。
NLP 背后的技术本文无法详细解释,但在此可以介绍一下高级层面上发生的事情:Spotify 会不断浏览网页,不断寻找有关音乐的博客和其他文本,然后试图分析人们对于特定的艺术家和歌曲评价如何——对于这些歌曲,他们都用了哪些形容词?在讨论歌曲本身的同时,其他哪些艺术家和歌曲被同时提到了?
在这之中 Spotify 最长提到的就是「文化向量(cultural vector)」或「顶级叙述词(top term)」了。每个艺人和每首歌曲都有数千个顶级叙述词。每个词都有相应的权重,权重则揭示了叙述词的重要性。(大概是人们用这个词形容这种音乐的概率)

随后,与协同过滤类似,NLP 模型会将这些叙述词的权重生成向量,代表歌曲的属性,同时比较出类似的歌曲。就是这样。
当然,这些推荐模型也与 Spotify 的整个生态系统链接,其中包含大量数据,使用大量 Hadoop 聚集推荐结果,并让这些模型能够稳定运行在大量数据组成的矩阵、无数网络文字以及音乐文件之上。现在,每个人都可以拥有自己的专属新歌单了。