什么是深拷贝,什么是浅拷贝
说到深浅拷贝,就不得不提到另外一个知识点,那就是引用类型和基本类型以及堆和栈的区别。
再复习一遍~
1)堆比栈大,栈比堆速度快;
2)基本数据类型比较稳定,而且相对来说占用的内存小;
3)引用数据类型大小是动态的,而且是无限的,引用值的大小会改变,不能把它放在栈中,否则会降低变量查找的速度,因此放在变量栈空间的值是该对象存储在堆中的地址,地址的大小是固定的,所以把它存储在栈中对变量性能无任何负面影响;
4)堆内存是无序存储,可以根据引用直接获取;
基本类型:undefined、null、string、number、boolean、symbol(es6)
引用类型:Object及各种Object的衍生类型,Array、RegExp、Date、Function、特殊的基本包装类型(String、Number、Boolean)以及单体内置对象(Global、Math)。
记住这一点:基本数据类型值不可变。
对于基本类型,其实是不存在深拷贝与浅拷贝的区别的。基本类型保存在栈内存中,复制变量值时,基本类型会在变量对象上创建一个新值,再复制给新变量。此后,两个变量的任何操作都不会影响到对方。
而引用类型保存在堆内存中,在创建一个对象类型时,计算机会在内存中开辟一个空间来存放值,我们要找到这个空间,需要知道这个空间的地址,这个地址是存放在栈内存中的,变量存放的就是这个地址,复制变量时其实就是将地址复制了一份给新变量,两个变量的值都指向存储在堆中的一个对象,也就是说,其实他们引用了同一个对象,改变其中一个变量就会影响到另一个变量。因此,深拷贝和浅拷贝只针对像 Object, Array 这样的复杂对象的。
那么再来定义一下深拷贝与浅拷贝。
浅拷贝:创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值,如果属性是引用类型,拷贝的就是内存地址,所以如果其中一个对象改变了这个地址,就会影响到另一个对象。
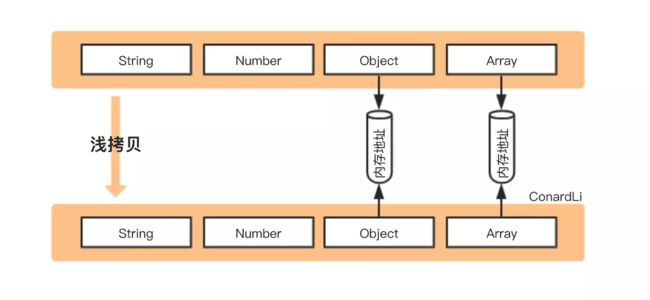
深拷贝:将一个对象从内存中完整的拷贝一份出来,从堆内存中开辟一个新的区域存放对象,且修改新对象不会影响原对象。
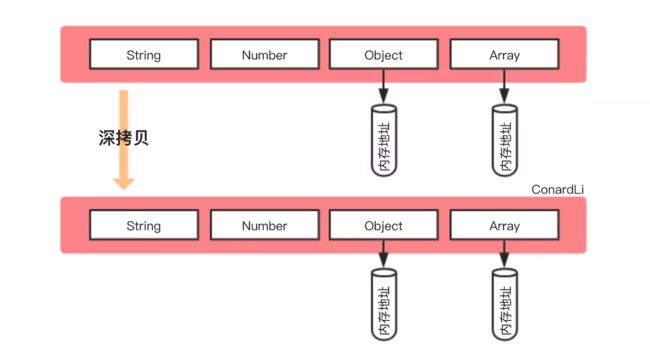
我们先举一个例子:
var obj1 = {
'name' : 'zhangsan',
'age' : '18',
'language' : [1,[2,3],[4,5]],
};
var obj2 = obj1;
var obj3 = shallowCopy(obj1);
function shallowCopy(src) {
var dst = {};
for (var prop in src) {
if (src.hasOwnProperty(prop)) {
dst[prop] = src[prop];
}
}
return dst;
}
obj2.name = "lisi";
obj3.age = "20";
obj2.language[1] = ["二","三"];
obj3.language[2] = ["四","五"];
console.log(obj1);
//obj1 = {
// 'name' : 'lisi',
// 'age' : '18',
// 'language' : [1,["二","三"],["四","五"]],
//};
console.log(obj2);
//obj2 = {
// 'name' : 'lisi',
// 'age' : '18',
// 'language' : [1,["二","三"],["四","五"]],
//};
console.log(obj3);
//obj3 = {
// 'name' : 'zhangsan',
// 'age' : '20',
// 'language' : [1,["二","三"],["四","五"]],
//};
可以看出,对于obj2是直接通过赋值传递,这样无论修改obj2的任一属性,都会影响到原有数据obj1。对于obj3采用了浅拷贝,即遍历原数据上的所有自有属性并赋值给一个新的变量。这样对于obj3中值类型的数据的修改都不会影响原始数据,但是修改其中的引用类型属性还是会改变原始数据。这也说明了浅拷贝只复制了对象中第一层的属性,并不包括对象里面的为引用类型的数据。
基于上面的理解,我们能够大形成一个深拷贝的思路,那就是遇到引用类型的时候继续复制其子对象,对对象及对象的所有子对象进行拷贝。
最常用版本
在我们日常开发中如果不使用第三方库或者自己写一个通用深拷贝方法时,最常用的深拷贝对象的方法就是通过
JSON.parse(JSON.stringify());
这种写法非常简单,而且可以应对大部分的应用场景,其过程说白了 就是利用JSON.stringify 将js对象序列化(JSON字符串),再使用JSON.parse来反序列化(还原)js对象。
但是它还是有很大缺陷的:
- 如果obj里面有时间对象,则JSON.stringify后再JSON.parse的结果,时间将只是字符串的形式。而不是时间对象;
var test = {
name: 'a',
date: [new Date(1536627600000), new Date(1540047600000)],
};
let b;
b = JSON.parse(JSON.stringify(test))
//test 输出结果
{name: "a", date: Array(2)}
date: (2) [Tue Sep 11 2018 09:00:00 GMT+0800 (中国标准时间), Sat Oct 20 2018 23:00:00 GMT+0800 (中国标准时间)]
name: "a"
__proto__: Object
//b输出结果
{name: "a", date: Array(2)}
date: (2) ["2018-09-11T01:00:00.000Z", "2018-10-20T15:00:00.000Z"]
name: "a"
__proto__: Object
2、如果obj里有RegExp、Error对象,则序列化的结果将只得到空对象
const test = {
name: 'a',
date: new RegExp('\\w+'),
};
// debugger
const copyed = JSON.parse(JSON.stringify(test));
test.name = 'test'
console.error('ddd', test, copyed) //copyed 中data为空
3.如果obj里有函数,undefined,则序列化的结果会把函数或 undefined丢失
const test = {
name: 'a',
date: function hehe() {
console.log('fff')
},
};
// debugger
const copyed = JSON.parse(JSON.stringify(test));
test.name = 'test'
console.error('ddd', test, copyed)


4、如果obj里有NaN、Infinity和-Infinity,则序列化的结果会变成null

5、JSON.stringify()只能序列化对象的可枚举的自有属性,例如 如果obj中的对象是有构造函数生成的, 则使用JSON.parse(JSON.stringify(obj))深拷贝后,会丢弃对象的constructor;
function Person(name) {
this.name = name;
console.log(name)
}
const liai = new Person('liai');
const test = {
name: 'a',
date: liai,
};
// debugger
const copyed = JSON.parse(JSON.stringify(test));
test.name = 'test'
console.error('ddd', test, copyed)
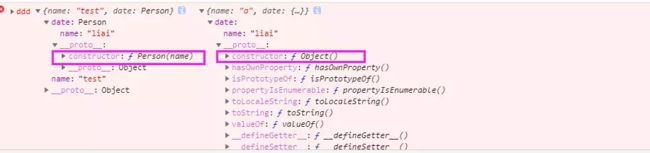
6.如果对象中存在循环引用的情况也无法正确实现深拷贝;
以上,如果拷贝的对象不涉及上面讲的情况,可以使用JSON.parse(JSON.stringify(obj))实现深拷贝。
但是如果有以上情况的就需要另寻他路了。而且面试的时候如果只说出这一种解法,相信面试官也不会特别满意。
注:后续大量引用《如何写出一个惊艳面试官的深拷贝》一文,作者思路清晰,面面俱到,值得推荐,原文:https://juejin.im/post/5d6aa4f96fb9a06b112ad5b1
基础版本
如果是浅拷贝的话,我们可以很容易写出下面的代码:
function clone(target) {
let cloneTarget = {};
for (const key in target) {
cloneTarget[key] = target[key];
}
return cloneTarget;
};
创建一个新的对象,遍历需要克隆的对象,将需要克隆对象的属性依次添加到新对象上,返回。
如果是深拷贝的话,考虑到我们要拷贝的对象是不知道有多少层深度的,我们可以用递归来解决问题,稍微改写上面的代码:
- 如果是原始类型,无需继续拷贝,直接返回
- 如果是引用类型,创建一个新的对象,遍历需要克隆的对象,将需要克隆对象的属性执行深拷贝后依次添加到新对象上。
function clone(target) {
if (typeof target === 'object') {
let cloneTarget = {};
for (const key in target) {
cloneTarget[key] = clone(target[key]);
}
return cloneTarget;
} else {
return target;
}
};
这是一个最基础版本的深拷贝,这段代码可以让你向面试官展示你可以用递归解决问题,但是显然,他还有非常多的缺陷,比如,还没有考虑数组。
兼容数组
function clone(target) {
if (typeof target === 'object') {
let cloneTarget = Array.isArray(target) ? [] : {};
for (const key in target) {
cloneTarget[key] = clone(target[key]);
}
return cloneTarget;
} else {
return target;
}
};
考虑循环引用
如果存在循环引用的情况,即对象的属性间接或直接的引用了自身的情况,则会导致上述代码进入死循环从而导致栈内存溢出。
解决循环引用问题,我们可以额外开辟一个存储空间,来存储当前对象和拷贝对象的对应关系,当需要拷贝当前对象时,先去存储空间中找,有没有拷贝过这个对象,如果有的话直接返回,如果没有的话继续拷贝,这样就巧妙化解的循环引用的问题。
- 检查map中有无克隆过的对象
- 有 - 直接返回
- 没有 - 将当前对象作为key,克隆对象作为value进行存储
- 继续克隆
function clone(target, map = new Map()) {
if (typeof target === 'object') {
let cloneTarget = Array.isArray(target) ? [] : {};
if (map.get(target)) {
return map.get(target);
}
map.set(target, cloneTarget);
for (const key in target) {
cloneTarget[key] = clone(target[key], map);
}
return cloneTarget;
} else {
return target;
}
};
接下来,我们可以使用,WeakMap提代Map来使代码达到画龙点睛的作用。
function clone(target, map = new WeakMap()) {
// ...
};
WeakMap 对象是一组键/值对的集合,其中的键是弱引用的。其键必须是对象,而值可以是任意的。
弱引用---在计算机程序设计中,弱引用与强引用相对,是指不能确保其引用的对象不会被垃圾回收器回收的引用。 一个对象若只被弱引用所引用,则被认为是不可访问(或弱可访问)的,并因此可能在任何时刻被回收。
简单而言,我们默认创建一个对象:const obj = {},就默认创建了一个强引用的对象,我们只有手动将obj = null,它才会被垃圾回收机制进行回收,如果是弱引用对象,垃圾回收机制会自动帮我们回收。
设想一下,如果我们要拷贝的对象非常庞大时,使用Map会对内存造成非常大的额外消耗,而且我们需要手动清除Map的属性才能释放这块内存,而WeakMap会帮我们巧妙化解这个问题。
其他数据类型
在上面的代码中,我们其实只考虑了普通的object和array两种数据类型,实际上所有的引用类型远远不止这两个,还有很多,下面我们先尝试获取对象准确的类型。
首先,判断是否为引用类型,我们还需要考虑function和null两种特殊的数据类型:
function isObject(target) {
const type = typeof target;
return target !== null && (type === 'object' || type === 'function');
}
if (!isObject(target)) {
return target;
}
// ...
获取数据类型
我们可以使用toString来获取准确的引用类型:
每一个引用类型都有toString方法,默认情况下,toString()方法被每个Object对象继承。如果此方法在自定义对象中未被覆盖,toString() 返回 "[object type]",其中type是对象的类型。
注意,上面提到了如果此方法在自定义对象中未被覆盖,toString才会达到预想的效果,事实上,大部分引用类型比如Array、Date、RegExp等都重写了toString方法。
我们可以直接调用Object原型上未被覆盖的toString()方法,使用call来改变this指向来达到我们想要的效果。
function getType(target) {
return Object.prototype.toString.call(target);
}

我们可以抽离出一些常用的数据类型以便后面使用:
const mapTag = '[object Map]';
const setTag = '[object Set]';
const arrayTag = '[object Array]';
const objectTag = '[object Object]';
const boolTag = '[object Boolean]';
const dateTag = '[object Date]';
const errorTag = '[object Error]';
const numberTag = '[object Number]';
const regexpTag = '[object RegExp]';
const stringTag = '[object String]';
const symbolTag = '[object Symbol]';
在上面的集中类型中,我们简单将他们分为两类:
- 可以继续遍历的类型
- 不可以继续遍历的类型
可继续遍历的类型
上面我们已经考虑的object、array都属于可以继续遍历的类型,因为它们内存都还可以存储其他数据类型的数据,另外还有Map,Set等都是可以继续遍历的类型,这里我们只考虑这四种,如果你有兴趣可以继续探索其他类型。
有序这几种类型还需要继续进行递归,我们首先需要获取它们的初始化数据,例如上面的[]和{},我们可以通过拿到constructor的方式来通用的获取。
例如:const target = {}就是const target = new Object()的语法糖。另外这种方法还有一个好处:因为我们还使用了原对象的构造方法,所以它可以保留对象原型上的数据,如果直接使用普通的{},那么原型必然是丢失了的。
function getInit(target) {
const Ctor = target.constructor;
return new Ctor();
}
下面,我们改写clone函数,对可继续遍历的数据类型进行处理:
// 克隆原始类型
if (!isObject(target)) {
return target;
}
// 初始化
const type = getType(target);
let cloneTarget;
if (deepTag.includes(type)) {
cloneTarget = getInit(target, type);
}
// 防止循环引用
if (map.get(target)) {
return map.get(target);
}
map.set(target, cloneTarget);
// 克隆set
if (type === setTag) {
target.forEach(value => {
cloneTarget.add(clone(value,map));
});
return cloneTarget;
}
// 克隆map
if (type === mapTag) {
target.forEach((value, key) => {
cloneTarget.set(key, clone(value,map));
});
return cloneTarget;
}
// 克隆对象和数组
const keys = type === arrayTag ? undefined : Object.keys(target);
forEach(keys || target, (value, key) => {
if (keys) {
key = value;
}
cloneTarget[key] = clone(target[key], map);
});
return cloneTarget;
}
不可继续遍历的类型
其他剩余的类型我们把它们统一归类成不可处理的数据类型,我们依次进行处理:
Bool、Number、String、String、Date、Error这几种类型我们都可以直接用构造函数和原始数据创建一个新对象:
function cloneOtherType(targe, type) {
const Ctor = targe.constructor;
switch (type) {
case boolTag:
case numberTag:
case stringTag:
case errorTag:
case dateTag:
return new Ctor(targe);
case regexpTag:
return cloneReg(targe);
case symbolTag:
return cloneSymbol(targe);
default:
return null;
}
}
克隆Symbol类型:
function cloneSymbol(targe) {
return Object(Symbol.prototype.valueOf.call(targe));
}
克隆正则:
function cloneReg(targe) {
const reFlags = /\w*$/;
const result = new targe.constructor(targe.source, reFlags.exec(targe));
result.lastIndex = targe.lastIndex;
return result;
}
克隆函数
这一块可以直接前往原文链接查看:https://juejin.im/post/5d6aa4f96fb9a06b112ad5b1#heading-10
总结
不难看出,简单的一个深拷贝浅拷贝的问题包含了很多知识点,有基础的也有高阶的。其他的面试题也大多如此,也正是看了作者原文中的各种思路让我重新思考了以往对一些题目片面的了解是不够的,需要将知识点都串联起来,不仅能帮助自己把整个js框架掌握的更熟练,也提升了自己分析问题解决问题的能力,还可以让面试官刮目相看。引用原文的知识点提炼,各位共勉啊~!
基本实现
递归能力循环引用
考虑问题的全面性
理解weakmap的真正意义多种类型
考虑问题的严谨性
创建各种引用类型的方法,JS API的熟练程度
准确的判断数据类型,对数据类型的理解程度
通用遍历:
写代码可以考虑性能优化
了解集中遍历的效率
代码抽象能力拷贝函数:
箭头函数和普通函数的区别
正则表达式熟练程度
参考文章:
- JS深拷贝和浅拷贝的实现--https://www.jianshu.com/p/cf1e9d7e94fb
- js 深拷贝 vs 浅拷贝--https://juejin.im/post/59ac1c4ef265da248e75892b
- 如何写出一个惊艳面试官的深拷贝--公众号-code秘密花园
- 关于JSON.parse(JSON.stringify(obj))实现深拷贝应该注意的坑--https://www.jianshu.com/p/b084dfaad501