架构师和后厨一个道理,都是炒菜的,只是架构师不炒菜,他因为炒的好,在后厨告诉其他的厨师用啥料炒
云计算好比大排档的烧烤师傅,过去一个一个单枪匹马,现在都在一起烤,张三师傅烤不过来。李四师傅给你烤,最后你专心的吃串就可以了
云计算其实是这样的,原来的编程思维都是一个逻辑主机的思维来计算,云计算是就是按多台逻辑主机的思维来计算的
云服务和云计算是两个概念。我是这样理解的,云服务其实是对计算机物理资源的逻辑抽象化,然后根据需求来提供相应的资源。而云计算指的是分布式计算。如hadoop和Spark。从目前来看。Spark这个计算框架比hadoop的MR要好用太多了
Hadoop是基于io,对硬盘要求比较高;
Spark对内存要求高。
spark攻克的难点在什么地方?
堆外内存
执行引擎的优化
把虚函数的调用和句柄都构成一个树,目的是避免oom风险
spark streaming比storm好多了
spark streaming事实上却是爽多了,尤其是API的统一,和中间输出的tuple突破
内存迭代计算
线程复用
其实很多
Rdd(弹性分布式数据集)
我觉得spark一直在不断的突破自己的极限,特别是tunsgen计划
人工智能
人工智能研究的方向之一,是以所谓“专家系统”为代表的,用大量“如果-就”(If - Then)规则定义的,自上而下的思路。
人工神经网络(Artifical Neural
Network),标志着另外一种自下而上的思路。
神经网络没有一个严格的正式定义。它的基本特点,是试图模仿大脑的神经元之间传递,处理信息的模式。
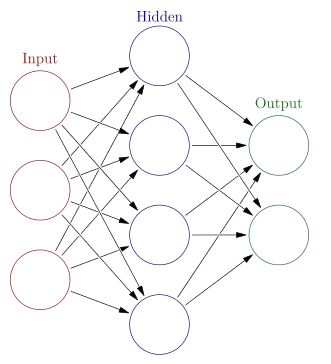
每个神经元,通过某种特定的输出函数(也叫激励函数activation function),计算处理来自其它相邻神经元的加权输入值
神经元之间的信息传递的强度,用所谓加权值来定义,算法会不断自我学习,调整这个加权值
在此基础上,神经网络的计算模型,依靠大量的数据来训练,还需要:
成本函数(cost function):用来定量评估根据特定输入值,计算出来的输出结果,离正确值有多远,结果有多靠谱
学习的算法(learning algorithm):这是根据成本函数的结果,自学,纠错,最快地找到神经元之间最优化的加权值
用小明、小红和隔壁老王们都可以听懂的语言来解释,神经网络算法的核心就是:计算、连接、评估、纠错、疯狂培训。
随着神经网络研究的不断变迁,其计算特点和传统的生物神经元的连接模型渐渐脱钩。
但是它保留的精髓是:非线性、分布式、并行计算、自适应、自组织。
计算机方向很多,挑一个喜欢的就好了,比如大数据,比如机器学习(神经网络)、计算机视觉、云计算等等
其他的有个大概了解就行了
但是Weka这个是真的好,类似的软件还有Orange、Knime、RapidMining!是机器学习和大数据挖掘结合的,都是开源的。Yale(RapidMining)有开源版的,功能有限
//Eclipse编译错误Access restriction:The type *** is not
accessible due to restriction on...解
//决方案
//Eclipse编译时报错:
//Accessrestriction:The type JPEGCodec is not accessible due to restriction on
//required library C:/Program Files/Java/jre6/lib/rt.jar
//解决方法:
//Project
-> Properties -> libraries,
//先remove掉JRE System Library,然后再Add Library重新加入。