webmagic,一个简洁但功能齐全的爬虫框架,其官方文档已经非常详尽,但偏重于使用,该文从源码结构以及细节上进行分析
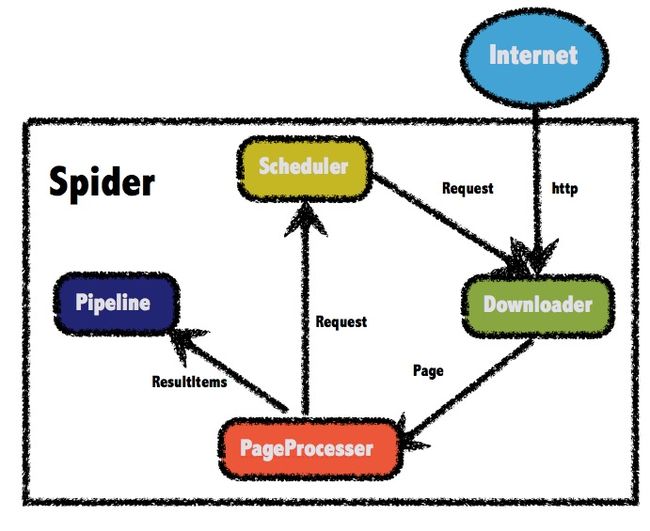
webmagic组件
webmagic的各个功能分别通过组件来实现,很好的实现了各功能之间的解耦,主要包括四大组件:Scheduler、Downloader、Pipeline、PageProcessor,四大组件通过Spider类进行相互协作完成框架功能
一、Scheduler
抓取url的管理,包含添加待抓取url以及取出需要抓取的url功能,分别通过push方法和poll方法完成两项功能,抓取url进行了抽象,以Request进行表示。
实现类
QueueScheduler:内部以LinkedBlockingQueue实现url队列,添加待抓取url直接以queue.add方法实现,取出抓取url以queue.poll实现。该类继承于DuplicateRemovedScheduler,因此有自动去重的功能。
PriorityScheduler:以优先级作为取出待抓取url的条件,内部以PriorityBlockingQueue作为队列的实现,同样继承于DuplicateRemovedScheduler,拥有去重功能
二、PageProcessor
如何对一个页面内容进行处理,是用户主要需要实现的接口,一般用户需要实现对页面内容的抽取以及更多待抓取url的获取
实现类
SimplePageProcessor:配置一个url正则表达式,自动从页面内容中抽取出对应的url加入抓取队列
三、Pipeline
对PageProcessor的抽取结果进行持久化处理,比如写入文件、存入数据库、或者简单的打印到控制台
实现类
ConsolePipeline:直接将结果输出到控制台
FilePipeline:将抽取结果写入文件进行持久化
四、Downloader
负责对待抓取的url进行下载,可配置下载线程数
实现类
HttpClientDownloader:使用apache HttpClient进行页面的下载功能,实现了代理配置功能
辅助类
一、CountableThreadPool
负责spider的线程管理,实现了一个堵塞线程池,可以实时获取线程池中正在使用的线程以及等待状态的线程数量,线程数的统计以AtomicInteger实现线程安全,内部默认的ExecutorService通过Executors.newFixedThreadPool生成,主要方法execute接受一个Runnable对象作为待执行任务,线程池中无可用线程时会进入阻塞状态
二、Proxy
进行spider的代理管理,抽取为单独的组件可以实现解耦
三、Selector
实现对下载后的页面内容进行选择的功能,主要实现有xpath、css、regex以及jsonPath
四、Request
对抓取url的封装
五、Page
存储抽取的内容以及抓取的url(非线程安全)
配置类
一、Spider
爬虫的入口,对各个组件进行协调,包含一个Downloader,一个PageProcessor,一个Scheduler以及一个PipeLine列表,抓取任务的执行线程调度以CountableThreadPool完成
二、site
抓取站点的配置,包括域名、ua、默认cookie、默认编码、默认http头等
webmagic关于多线程的处理
爬虫程序必然牵涉到多线程处理以实现并行的抓取任务,在webmagic中主要有三处需要对多线程情况进行处理
Scheduler
在同一时间可能会有多个线程对Scheduler进行操作,webmaigic的QueueScheduler实现直接以LinkedBlockingQueue解决该问题
HttpClientDownloader
在对httpclient的获取中,主要是在生成新的httpClient时需要进行多线程的处理,主要代码

当需要获取的httpclient不存在时进开始进行同步处理,在同步代码块中判断是否有对应的httpclient存在,如果没有则生成对应httpclient并加入列表中,该处使用双重检查保证不会重复放入httpclient,进行双重检测是由于未对整个方法进行同步处理,目的是为了性能优化,即不会对存在相应的httpclient进行同步,只对获取不到该对象的情况进行同步
Spider
spider负责对整个抓取过程进行协调,自然避免不了对多线程的处理,该类主要通过ReentrantLock和Condition进行多线程的处理。当爬虫开始执行时,spider持续从scheduler中获取待抓取的url,当待抓取url为空时,该线程进行等待状态,通过waitNewUrl实现

该阻塞状态通过signalNewUrl方法进行解除
