在大数据盛行的时代,作为一位数据人或是IT人,难免遇上各种不同的算法。你知道日常一些基础实用的算法的优势和步骤吗?今天,大圣众包威客平台(www.dashengzb.cn)将深入浅出地为大家介绍5种常见的算法。

1.二分查找算法
【概念解析】:
二分查找算法,是一种在有序数组中查找某一特定元素的搜索算法。
【算法优势】:
二分查找算法,使得每一次比较都令搜索范围缩小一半,它的时间复杂度为Ο(logn)。
【算法步骤】:
1.搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;
2.如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且和开始一样,从中间元素开始比较;
3.如果在某一步骤数组为空,则代表找不到。

2.堆排序算法
【概念解析】:
堆排序(Heapsort)是指利用“堆”这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足了堆积的性质——子结点的键值或索引总是小于(或者大于)它的父节点。
【算法优势】:
堆排序的平均时间复杂度为Ο(nlogn)。
【算法步骤】:
1.创建一个堆H[0..n-1];
2.把堆首(最大值)和堆尾互换;
3.把堆的尺寸缩小1,并调用shift_down(0),目的是把新的数组顶端数据调整到相应位置;
4.重复步骤2,直到堆的尺寸为1。
3.DFS(深度优先搜索)算法
【概念解析】:
深度优先搜索算法(Depth-First-Search),是搜索算法的一种。
【算法优势】:
DFS算法是图论中的经典算法,利用这种算法可以产生目标图的相应拓扑排序表。而利用拓扑排序表可以方便地解决很多相关的图论问题。DFS属于盲目搜索,一般用堆数据结构来辅助实现。
【算法步骤】:
1.访问顶点v;
2.依次从v的未被访问的邻接点出发,对图进行深度优先遍历,直至图中和v有路径相通的顶点都被访问过;
3.若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止。

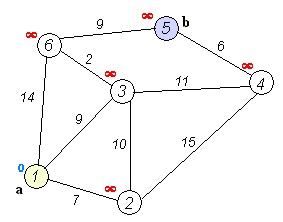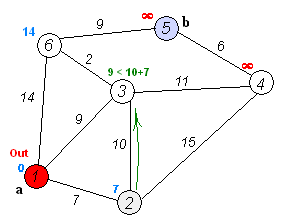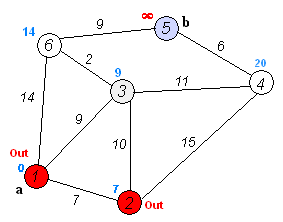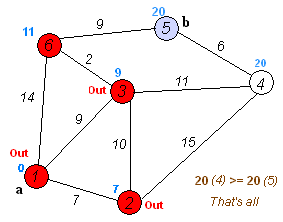
4.Dijkstra算法
【概念解析】:
戴克斯特拉算法(Dijkstra'salgorithm)是由荷兰计算机科学家艾兹赫尔·戴克斯特拉提出的,该算法常用于路由算法或者作为其他图算法的一个子模块。
【算法优势】:
Dijkstra算法使用了广度优先搜索,以解决非负权有向图的单源最短路径问题,算法最终得到一个最短路径树。对于不含负权的有向图,Dijkstra算法是目前已知的最快的单源最短路径算法。
【算法步骤】:
1.初始时,令S={V0},T={其余顶点},T中顶点对应的距离值:
若存在,d(V0,Vi)为弧上的权值;
若不存在,d(V0,Vi)为∞;
2.从T中选取一个距离值为最小的顶点W且不在S中,加入S;
3.对其余T中顶点的距离值进行修改:若加进W作中间顶点,从V0到Vi的距离值缩短,则修改此距离值;
4.重复上述步骤2、3,直到S中包含所有顶点,即W=Vi为止。
5.朴素贝叶斯分类算法
【概念解析】:
朴素贝叶斯分类算法,是一种基于贝叶斯定理的简单概率分类算法。
【算法优势】:
朴素贝叶斯分类器依靠精确的自然概率模型,在有监督学习的样本集中能获取非常好的分类效果。在许多实际应用中,朴素贝叶斯模型参数估计使用最大似然估计方法,换言之朴素贝叶斯模型能工作并没有用到贝叶斯概率或者任何贝叶斯模型。尽管是带着这些朴素思想和过于简单化的假设,但朴素贝叶斯分类器在很多复杂的现实情形中仍能够取得相当好的效果。
【算法步骤】:
贝叶斯分类的基础是概率推理——在各种条件存在不确定、仅知其出现概率的情况下,如何完成推理和决策任务。概率推理是与确定性推理相对应的。而朴素贝叶斯分类器是基于独立假设的,即假设样本每个特征与其他特征都不相关。
艺多不压身,希望以上算法干货能让你在大数据海洋里驰骋纵横。
(更多大数据与商业智能领域干货、电子书,添加大圣花花个人微信号(dashenghuaer))