简介
在LLVM的官方文档中对Swift的编译器设计描述如下: Swift编程语言是在LLVM上构建,并且使用LLVM IR和LLVM的后端去生成代码。但是Swift编译器还包含新的高级别的中间语言,称为SIL。SIL会对Swift进行较高级别的语义分析和优化。 我们下面分析一下SIL设计的动机和SIL的应用,包括高级别的语义分析,诊断转换,去虚拟化,特化,引用计数优化,TBAA(Type Based Alias Analysis)等。并且会在某些流程中加入对SIL和LLVM IR对比。
SIL介绍
SIL是为了实现swift编程语言而设计的,包含高级语义信息的SSA格式的中间语言.SIL包含以下功能:
一系列的高级别优化保障,用于对运行时和诊断行为提供可预测的底线
对swift语言数据流分析强制要求,对不满足强制要求的问题产生诊断。例如变量和结构体必须明确初始化,代码可达性即方法return的检测,switch的覆盖率
确保高级别优化。包含retain/release优化,动态方法的去虚拟化(devirtualization,不了解虚函数可以查看之前文章static vs dynamic dispatch),闭包内联,内存初始化提升和泛型方法实例 化.
可用于分配"脆弱"内联的稳定分配格式,将Swift库组件的泛型优化为二进制。
和LLVM IR不同,SIL一般是target无关的独立格式的表示,可用于代码分发.但是也可以和LLVM一样表达具体target概念. 如果想查看更多SIL的实现和SIL通道的开发信息,可以查看SIL开发手册(原英文文档为SILProgrammersManual.md)。
我们下面对Clang的Swift编译器的传递流程进行对比:
编译流程对比
Clang编译器流程

Clang编译流程存在以下问题:
在源码和LLVM IR直接存在非常大的抽象鸿沟
IR不适用对源码进行分析和检查 使用了Analysis通过CFG进行分析,分析和代码生成是两部分
CFG(控制流图)不够精确
CFG不是主道(hot path)
在CFG和IR降级中会出现重复分析,做无用功
Swift编译器流程
Swift作为一个高级别和安全的语言具有以下特点:
高级别语言
通过代码充分的展示语言的特性
支持基于协议的泛型
安全语言
充分的数据流检查:未初始化变量,函数返回处理检测,这些项在检测不合格时会产生对应的编译错误
边界和溢出的检测
Swift编译流程图如下:
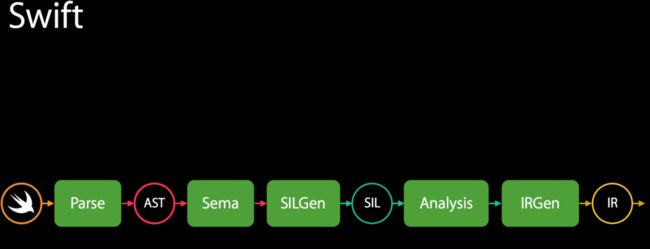
Swift编译器提供的SIL具有以下优势:
对程序语义信息重复表示
可以用于代码生成和分析 Clang不可以
处于编译器的主道
可以连接源码和LLVM的抽象鸿沟
SIL的设计
SIL流程分析
Swift编译器作为高级编译器,具有以下严格的传递流程结构。 Swift编译器的流程如下
Parse: 语法分析组件从Swift源码构成AST
语义分析组件对AST进行类型检查,并对其进行类型信息注释。
SILGen组件从AST形成"生的(raw)"SIL
一系列在 生 SIL上运行的,用于确定优化和诊断合格,对不合格的代码嵌入特定的语言诊断。这些操作一定会执行,即使在
-Onone选项下也不例外。之后产生 正式(canonical) SIL.一般情况下,是否在正式
SIL上运行SIL优化是可选的,这个检测可以提升结果可执行文件的性能.可以通过优化级别来控制,在-Onone模式下不会执行.IRGen会将
正式SIL降级为LLVM IR.LLVM后端提供LLVM优化,执行LLVM代码生成器并产生二进制码.
SIL操作流程分析
SILGen
SILGen遍历Swift进行了类型检查的AST,产生 raw SIL.SILGen产生的SIL格式具有如下属性:
属性会被加载和存储在可变内存地址,而不是使用严格的SSA(静态单赋值形式:每个变量仅被赋值一次)。这和Clang前端产生的繁重的LLVM IR(例如初始化
alloca)类似。但是Swift的变量在大多数情况下使用了引用计数器,使得变量可以被retained,release和被闭包引用。数据流检测。例如明确的内存分配,方法return检查,switch覆盖等.此环节目前不是强制执行的
transparent函数优化目前未实现.
这些特性会被接下来的确保优化和诊断检查使用,这两项在 raw SIL上一定会运行。
确保优化和诊断检查
在SILGen之后,会在raw SIL上运行确定顺序的优化。我们并不希望编译器产生的诊断改变编译器的进展,所以这些优化的设计是简单和可预测.
-
Mandatory inlining: 强制内联对于transparent函数进行内联。
透明函数即,如果一个函数只会受到入参的变化,那么这个函数每次的调用都会是相同的,同样的入参一定会返回一样的返回值,在确定入参的时候,返回值是可预测的。这样的函数,就可以进行内联优化。
-
内存提升实现分为两个优化阶段:
将
alloc_box结构优化为alloc_stack提升无暴露地址(
non_address-exposed)的alloc_stack说明到SSA注册. 常数传播: Constant propagation折叠常量表达,繁殖常量值.如果在计算常量表达式时出现算术溢出,就会产生警告.
返回分析查证每个方法在每个代码路径只返回一个值,并且不会在定义的末端出现无返回值的错误.如果不需要返回值的函数return了也会报错.
临界拆分: critical edge splitting不支持任意的基础block参数通过终端进行临界拆分. 在 Advanced Compiler Design & Implementation的第13.3章节,第407,408页这样描述临界分裂
这个算法的核心作用体现为:流程图中的临界如果在流分析前被拆分的话,会使得运算更近高效. 原文: A key point in the algorithm is that it can be much more effective if the critical edges in the flowgraph have been split before the flow analysis is performed.
如果诊断通道完成后,会产生规范SIL.
泛型特化: Generic specialization
在
-Onone模式下的ARC性能优化.
说完了处理raw SIL的特定流程,我们对上面提到的优化通道: optimization passes进行下说明.
泛型优化
SIL获取语言特定的类型信息,使得无法在LLVM IR实现的高级优化在swift编译器中得以实现.
- 泛型特化分析泛型函数的特定调用,并生成新的特定版本的函数.然后将泛型的特定用法全部重写为对应的特定函数的指甲调用. 例如
func min(x: T, y: T) -> T {
return y < x ? y : x
}
从普通的泛型展开
func min(x: T, y: T, FTable: FunctionTable) -> T {
let xCopy = FTable.copy(x)
let yCopy = FTable.copy(y)
let m = FTable.lessThan(yCopy, xCopy) ? y : x
FTable.release(x)
FTable.release(y)
return m
}
在确定入参类型时,比如Int,可以优化为
func min(x: Int, y: Int) -> Int {
return y < x ? y : x
}
从而减少泛型调用的开销
witness和虚函数表的去虚拟化优化通过给定类型去查找关联的类的虚函数表或者类型的witness表,并将虚函数调用替换为调用函数映射
性能内联
引用计数优化
内存提升/优化
高级领域特定优化swift编译器对基础的swift类型容器(类似Array或String)实现了高级优化.领域特定优化需要在标准库和优化器之间定义交互.详情可以参考 :ref:
HighLevelSILOptimizations
SIL语法
SIL依赖于swift的类型系统和声明,所以SIL语法是swift的延伸.一个.sil文件是一个增加了SIL定义的swift源文件.swift源文件只会针对声明进行语法分析.swift的func方法体(除了嵌套声明)和最高阶的代码会被SIL语法分析器忽略.在.sil文件中没有隐式import.如果使用swift或者Buildin标准组件的话必须明确的引入. 以下是一个.sil文件的示例
sil_stage canonical
import Swift
// 定义用于SIL函数的类型
struct Point {
var x : Double
var y : Double
}
class Button {
func onClick()
func onMouseDown()
func onMouseUp()
}
// 定义一个swift函数,函数体会被SIL忽略
func taxicabNorm(_ a:Point) -> Double {
return a.x + a.y
}
// 定义一个SIL函数
// @_T5norms11taxicabNormfT1aV5norms5Point_Sd 是swift函数名taxicabNorm重整之后的命名
sil @_T5norms11taxicabNormfT1aV5norms5Point_Sd : $(Point) -> Double {
bb0(%0 : $Point):
// func Swift.+(Double, Double) -> Double
%1 = function_ref @_Tsoi1pfTSdSd_Sd
%2 = struct_extract %0 : $Point, #Point.x //萃取Point结构体内的x
%3 = struct_extract %0 : $Point, #Point.y ////萃取Point结构体内的y
%4 = apply %1(%2, %3) : $(Double, Double) -> Double //冒号前为计算体实现通过引用的展开,冒号后为类型说明
return %4 : Double //返回值
}
// 定义一个SIL虚函数表,匹配的是动态分派中函数实现的id,这个动态分派是在已知的静态类的类型虚函数表中
sil_vtable Button {
#Button.onClick!1: @_TC5norms6Button7onClickfS0_FT_T_
#Button.onMouseDown!1: @_TC5norms6Button11onMouseDownfS0_FT_T_
#Button.onMouseUp!1: @_TC5norms6Button9onMouseUpfS0_FT_T_
}
SIL阶段
decl ::= sil-stage-decl
sil-stage-decl ::= 'sil_stage' sil-stage
sil-stage ::= 'raw'
sil-stage ::= 'canonical'
基于操作的不同阶段,SIL拥有不同的声明.
Raw SIL, 生的SIL是通过
SILGen产生的,并未经过保证优化或者诊断通道.Raw SIL可能没有完善结构的SSA图表.可能会包含数据流错误.一些说明可能会以非规范的方式展示,例如无地址的assign和destory_addr的数值.Raw SIL不应该用于本地代码的生成或分发.Canonical SIL,规范SIL是在保证优化和诊断之后的
SIL.数据流错误必须被消除掉,肯定说明也必须被规范化为更简单的形式.性能优化和本地代码是生成都是从这种格式衍生的.包含这种格式SIL的组件可以被分发.SIL文件通过在顶部声明sil_stage raw或sil_stage canonical来说明当前的操作阶段.一个文件之后出现一种阶段的声明.
SIL类型
sil-type ::= '/pre> '*'? generic-parameter-list? type
SIL的类型是通过$符号进行标记的。SIL的类型系统和swift的密切相关.所以$之后的类型会根据swift的类型语法进行语法分析。
类型降级: type lowering
swift的正式类型系统,倾向于对大量的类型信息进行抽象概括.但是SIL目标是展示更多的实现细节,这个区别也体现在SIL的类型系统中.所以把正式类型降级为较低类型的操作称为类型降级。
提取区别:Abstraction Difference
包含未约束类型的通用函数一定会被非直接调用.比如分配充足内存和创建地址指针指向这块地址。如下的泛型函数
func generateArray(n : Int, generator : () -> T) -> [T]
函数generator会通过一个隐式指针,指向存储在一个非直接调用的地址中,(可以参考之前static vs dynamic dispatch中虚函数表的设计和实现).在处理任意类型值时操作都是一样的.
我们不希望对
generateArray的每个T的类型去产生一个新的拷贝我们不希望对每个类型进行普遍声明
-
我们不希望通过
T的类型动态的去构造对于genetator的调用但是我们也不希望现有的通用系统对我们的非通用代码进行低效处理。例如,我们希望
()->Int可以直接返回结果。但是()->Int是()->T的代替(subsitution),对于generateArray的调用应该向generator传递()->Int。 所以一个正式类型在通用上下文中的表现可能会因为正式类型的的代替而不同.我们将这种不同成为提取区别.
SIL对于类型的提取区别的设计是,在每个级别的代替中,提取数值都可以被使用。
为了可以实现如上设计,泛型实例的正式类型应该一直使用非替换正式类型的提取方式进行降级.例如
struct Generator {
var fn : () -> T
}
var intGen : Generator
其中intGen.fn拥有代替类型()->Int,可以被降级为@callee_owned () -> Int,可以直接返回结果.但是如果更恰当的使用非代替方式,()->T就会变成@callee_owned () -> @out Int
当使用非代替的提取方式进行类型降级时,可以看做将拥有相同构造的类型中的具体类型替换为现有类型,以此来实现类型降级. 对于g 的Generator<(Int, Int) -> Float>,g.fn是使用()->T进行降级的,简单理解就是,类型是否是具体类型,如果是,才能进行提取方式进行降级,不然只能产生
@callee_owned () -> @owned @callee_owned (@in (Int, Int)) -> @out Float.
所以提取区别来代替通用函数中类型的标准是:是否是具体类型.is materializable or not 这个系统具有通过重复代替的方式实现提取方式的属性.所以可以把降级的类型看做提取方式的编码. SILGen已经拥有了使用提取方式转换类型的工序. 目前只有函数和元祖类型会通过提取区别进行改变.
合法的SIL类型
SIL类型的值应该是这样的:
可被加载的SIL类型,
$T合法SIL类型的地址
$*T或者如果T是一个合法的SIL类型需要满足以下条件 不展开,需要查看SIL语法中的Legal SIL Types
类型T满足一下条件才是一个合法的SIL类型
- 函数类型符合
SIL的约束条件 - metatype可以描述功能
- 原组的内部元素,类型也是合法的
SIL类型 - 可选
Optional,U也是合法类型 - 非函数,原组,可选类型,metatype,或者l-value类型的合法的Swift类型
- 包含合法类型的
@box
注意,在递归条件内的类型,还需要是正式类型。例如泛型内的参数,仍然是Swift类型,而不是SIL降级类型。
地址类型
地址类型$*T指针指向的是任意引用的值或者$T。
地址不是引用计数指针,不能被retained或released。
Box类型
本地变量和非直接的数值类型都是存储在堆上的,@box T是一个引用计数类型,指向的是包含了多种T的盒子。盒子使用的是Swift的原生引用计数。
Metatype类型
SIL内的metatype类型必须描述自身表示:
-
@thin意思是不需要内存 -
@thick指存储的是类型的引用或类型子类的引用 -
@objc指存储的是一个OC类对象的表示而不是Swift类型对象。
函数类型
SIL中的函数类型和Swift中的函数类型有以下区别:
SIL函数可能是泛型。例如,通过function_ref返回一个泛型函数类型。SIL函数可以声明为@noescape。@noescape函数类型必须是convention(thin)或者@callee_guatanteed。-
SIL函数类型声明了以下几种处理上下文的情景:-
@convention(thin)不要求上下文。这种类型也可以通过@noescape声明。 -
@callee_guatanteed会被认为直接参数。也意味着convention(thick)。 -
@callee_owned上下文值被认为是不拥有的直接参数。也意味着convention(thick)。 -
@convention(block)上下文值被认为是不拥有的直接参数。 - 其他函数类型会被描述为
Properties of Types和Calling Convention
-
-
SIL函数必须声明参数的协议。非直接的参数类型是*T,直接参数类型是T-
@in是非直接参数。地址必须是已经初始化的对象,函数负责销毁内部持有的值。 -
@inout是非直接参数。内存必须是已经初始化的对象。在函数返回之前,必须保证内存是被初始化的。
-
-
SIL函数需要声明返回值的协议。-
@out是非直接的结果。地址必须是未初始化的对象。
-
VTables