title: Azkaban Learning
date: 2017-01-11 11:54:03
tags: [Azkaban,调度系统,大数据组件]
categories: "调度系统"
Azkaban
关键字:Azkaban简介、大数据作业调度系统
这篇文章适合对azkaban有一定了解的人阅读。建议先粗读:
AZ开发文档:http://azkaban.github.io/azkaban/docs/latest/#overview
强子哥的源码分析:https://my.oschina.net/qiangzigege/blog/653198
(以下内容部分摘自上两个链接)
azkaban源码: git clone https://github.com/azkaban/azkaban.git
Azkaban 简介
Azkaban was implemented at LinkedIn to solve the problem of Hadoop job dependencies. We had jobs that needed to run in order, from ETL jobs to data analytics products.
Initially a single server solution, with the increased number of Hadoop users over the years, Azkaban has evolved to be a more robust solution.
Azkaban 是由Linkedln公司为了解决hadoop 作业之间的依赖而实现的。因为有一些ETL作业以及数据分析产品需要按照一定的顺序去执行。
随着hadoop用户的逐年增加,Azkaban从一个简单的服务解决方案发展成为一个更加健壮鲁棒的方案。
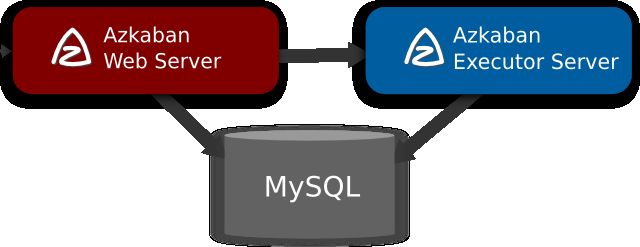
Azkaban的系统架构主要由三个组件组成:
- WebServer :暴露Restful API,提供分发作业和调度作业功能;
- ExecServer :对WebServer 暴露 API ,提供执行作业的功能;
- MySQL :数据存储,实现Web 和 Exec之间的数据共享和部分状态的同步。
多执行节点模式下,更细节一点的架构图可以如下,图中省略MySQL数据库:

非常简单而直观
WebServer
暴露Restful API
在azkaban-webserver工程中,可以非常清晰地看到对外暴露的Servlet,其中最主要的几个是:
- ExecutorServlet 主要提供立即执行作业、取消作业流、暂停作业流、获取流或节点日志等接口
- ScheduleServlet 主要提供设置调度、设置Sla报警规则、获取调度信息等接口
- HistoryServlet 主要提供查看作业流执行历史的接口
- ProjectManagerServlet 主要提供上传项目zip包、下载项目zip包、删除项目、获取流的DAG等接口
分发作业
ExecutorManager 主要承担这部分的功能,所有类型的作业(包括立即执行和调度执行),都会通过submitExecutableFlow(ExecutableFlow exflow, String userId)这个方法进行提交。
在该方法中,我们可以看到:如果是多执行节点模式下,执行实例先放进分发队列中;如果是单节点模式下,立即调用dispatch方法进行分发。
if (isMultiExecutorMode()) {
//Take MultiExecutor route
executorLoader.addActiveExecutableReference(reference);
queuedFlows.enqueue(exflow, reference);
} else {
// assign only local executor we have
Executor choosenExecutor = activeExecutors.iterator().next();
executorLoader.addActiveExecutableReference(reference);
try {
dispatch(reference, exflow, choosenExecutor);
} catch (ExecutorManagerException e) {
executorLoader.removeActiveExecutableReference(reference.getExecId());
throw e;
}
}
在多执行节点模式下,执行实例被放进分发队列。队列会被线程 QueueProcessorThread 定时处理。
/* Method responsible for processing the non-dispatched flows */
private void processQueuedFlows(long activeExecutorsRefreshWindow,
int maxContinuousFlowProcessed) throws InterruptedException,
ExecutorManagerException {
long lastExecutorRefreshTime = 0;
Pair runningCandidate;
int currentContinuousFlowProcessed = 0;
while (isActive() && (runningCandidate = queuedFlows.fetchHead()) != null) {
ExecutionReference reference = runningCandidate.getFirst();
ExecutableFlow exflow = runningCandidate.getSecond();
long currentTime = System.currentTimeMillis();
// if we have dispatched more than maxContinuousFlowProcessed or
// It has been more then activeExecutorsRefreshWindow millisec since we
// refreshed
if (currentTime - lastExecutorRefreshTime > activeExecutorsRefreshWindow
|| currentContinuousFlowProcessed >= maxContinuousFlowProcessed) {
// Refresh executorInfo for all activeExecutors
refreshExecutors();
lastExecutorRefreshTime = currentTime;
currentContinuousFlowProcessed = 0;
}
/**
*
* TODO: Work around till we improve Filters to have a notion of GlobalSystemState.
* Currently we try each queued flow once to infer a global busy state
* Possible improvements:-
* 1. Move system level filters in refreshExecutors and sleep if we have all executors busy after refresh
* 2. Implement GlobalSystemState in selector or in a third place to manage system filters. Basically
* taking out all the filters which do not depend on the flow but are still being part of Selector.
* Assumptions:-
* 1. no one else except QueueProcessor is updating ExecutableFlow update time
* 2. re-attempting a flow (which has been tried before) is considered as all executors are busy
*
*/
if(exflow.getUpdateTime() > lastExecutorRefreshTime) {
// put back in the queue
queuedFlows.enqueue(exflow, reference);
long sleepInterval =
activeExecutorsRefreshWindow
- (currentTime - lastExecutorRefreshTime);
// wait till next executor refresh
sleep(sleepInterval);
} else {
exflow.setUpdateTime(currentTime);
// process flow with current snapshot of activeExecutors
selectExecutorAndDispatchFlow(reference, exflow, new HashSet(activeExecutors));
}
// do not count failed flow processsing (flows still in queue)
if(queuedFlows.getFlow(exflow.getExecutionId()) == null) {
currentContinuousFlowProcessed++;
}
}
}
selectExecutorAndDispatchFlow 方法先是选择执行节点(选择节点的实现比较有意思),选好节点后最终也是调用了dispatch进行作业分发。
/* process flow with a snapshot of available Executors */
private void selectExecutorAndDispatchFlow(ExecutionReference reference,
ExecutableFlow exflow, Set availableExecutors)
throws ExecutorManagerException {
synchronized (exflow) {
Executor selectedExecutor = selectExecutor(exflow, availableExecutors);
if (selectedExecutor != null) {
try {
dispatch(reference, exflow, selectedExecutor);
} catch (ExecutorManagerException e) {
logger.warn(String.format(
"Executor %s responded with exception for exec: %d",
selectedExecutor, exflow.getExecutionId()), e);
handleDispatchExceptionCase(reference, exflow, selectedExecutor,
availableExecutors);
}
} else {
handleNoExecutorSelectedCase(reference, exflow);
}
}
}
因为Web 和Exec 之间是通过mysql进行数据共享的,所以dispatch进行作业分发的逻辑非常简单,就是简单地通过HTTP请求传递execId等信息,其余所需要的数据都通过数据库读写完成。
调度作业
调度作业是调度系统的最重要的功能之一,也是Azkaban里相对复杂的一个模块。调度是通过ScheduleManager对外暴露,对应着的结构是Schedule;对内是通过TriggerManager来实现,对应着的结构是Trigger。
所有的调度信息都通过ScheduleManager.scheduleFlow传入,可以看到传入参数包含了项目id、项目名字、流名字、第一次调度时间戳、时区、调度周期、下一次执行时间、提交时间、提交人。对于一个调度来说,最关键的信息无非是第一次调度时间和调度周期。
public Schedule scheduleFlow(final int scheduleId, final int projectId,
final String projectName, final String flowName, final String status,
final long firstSchedTime, final DateTimeZone timezone,
final ReadablePeriod period, final long lastModifyTime,
final long nextExecTime, final long submitTime, final String submitUser)
从scheduleFlow 往下可以看到调用了TriggerBasedScheduleLoader.insertSchedule。这个方法里边先是将Schedule转换成了Trigger,然后将Trigger放到了TriggerManager里边。scheduleToTrigger方法写的非常简洁巧妙,读者自行研究,此处不作细致分析。
@Override
public void insertSchedule(Schedule s) throws ScheduleManagerException {
Trigger t = scheduleToTrigger(s);
try {
triggerManager.insertTrigger(t, t.getSubmitUser());
s.setScheduleId(t.getTriggerId());
} catch (TriggerManagerException e) {
throw new ScheduleManagerException("Failed to insert new schedule!", e);
}
}
我们在继续看看Trigger被塞到TriggerManager做了些啥。从下边可以看到,先是调用triggerLoader写进数据库,然后就放到了一个线程runnerThread中去。
public void insertTrigger(Trigger t) throws TriggerManagerException {
synchronized (syncObj) {
try {
triggerLoader.addTrigger(t);
} catch (TriggerLoaderException e) {
throw new TriggerManagerException(e);
}
runnerThread.addTrigger(t);
triggerIdMap.put(t.getTriggerId(), t);
}
}
接下来就显而易见了,这个线程TriggerScannerThread runnerThread 定期检查Trigger是否应该触发(onTriggerTrigger)或者终止(onTriggerExpire)。
private void checkAllTriggers() throws TriggerManagerException {
long now = System.currentTimeMillis();
// sweep through the rest of them
for (Trigger t : triggers) {
try {
scannerStage = "Checking for trigger " + t.getTriggerId();
boolean shouldSkip = true;
if (shouldSkip && t.getInfo() != null && t.getInfo().containsKey("monitored.finished.execution")) {
int execId = Integer.valueOf((String) t.getInfo().get("monitored.finished.execution"));
if (justFinishedFlows.containsKey(execId)) {
logger.info("Monitored execution has finished. Checking trigger earlier " + t.getTriggerId());
shouldSkip = false;
}
}
if (shouldSkip && t.getNextCheckTime() > now) {
shouldSkip = false;
}
if (shouldSkip) {
logger.info("Skipping trigger" + t.getTriggerId() + " until " + t.getNextCheckTime());
}
if (logger.isDebugEnabled()) {
logger.info("Checking trigger " + t.getTriggerId());
}
if (t.getStatus().equals(TriggerStatus.READY)) {
if (t.triggerConditionMet()) {
onTriggerTrigger(t);
} else if (t.expireConditionMet()) {
onTriggerExpire(t);
}
}
if (t.getStatus().equals(TriggerStatus.EXPIRED) && t.getSource().equals("azkaban")) {
removeTrigger(t);
} else {
t.updateNextCheckTime();
}
} catch (Throwable th) {
//skip this trigger, moving on to the next one
logger.error("Failed to process trigger with id : " + t.getTriggerId(), th);
}
}
}
Trigger触发的时候就会调用自己的action.doAction(),调度任务的Trigger的action一般都是ExecuteFlowAction,其doAction方法如下。方法主要做了两个事情,第一个是构建执行实例ExecutableFlow,第二个是如果该调度设置了报警规则,则构建SlaTrigger。
构建执行实例完成后,可以看到调用了executorManager.submitExecutableFlow(exflow, submitUser) 进行作业分发,这样子,就跟上文提到的作业分发殊途同归。下边不再分析。
@Override
public void doAction() throws Exception {
if (projectManager == null || executorManager == null) {
throw new Exception("ExecuteFlowAction not properly initialized!");
}
Project project = projectManager.getProject(projectId);
if (project == null) {
logger.error("Project to execute " + projectId + " does not exist!");
throw new RuntimeException("Error finding the project to execute "
+ projectId);
}
Flow flow = project.getFlow(flowName);
if (flow == null) {
logger.error("Flow " + flowName + " cannot be found in project "
+ project.getName());
throw new RuntimeException("Error finding the flow to execute "
+ flowName);
}
ExecutableFlow exflow = new ExecutableFlow(project, flow);
exflow.setSubmitUser(submitUser);
exflow.addAllProxyUsers(project.getProxyUsers());
if (executionOptions == null) {
executionOptions = new ExecutionOptions();
}
if (!executionOptions.isFailureEmailsOverridden()) {
executionOptions.setFailureEmails(flow.getFailureEmails());
}
if (!executionOptions.isSuccessEmailsOverridden()) {
executionOptions.setSuccessEmails(flow.getSuccessEmails());
}
exflow.setExecutionOptions(executionOptions);
try {
executorManager.submitExecutableFlow(exflow, submitUser);
logger.info("Invoked flow " + project.getName() + "." + flowName);
} catch (ExecutorManagerException e) {
throw new RuntimeException(e);
}
// deal with sla
if (slaOptions != null && slaOptions.size() > 0) {
int execId = exflow.getExecutionId();
for (SlaOption sla : slaOptions) {
logger.info("Adding sla trigger " + sla.toString() + " to execution "
+ execId);
SlaChecker slaFailChecker =
new SlaChecker("slaFailChecker", sla, execId);
Map slaCheckers =
new HashMap();
slaCheckers.put(slaFailChecker.getId(), slaFailChecker);
Condition triggerCond =
new Condition(slaCheckers, slaFailChecker.getId()
+ ".isSlaFailed()");
// if whole flow finish before violate sla, just expire
SlaChecker slaPassChecker =
new SlaChecker("slaPassChecker", sla, execId);
Map expireCheckers =
new HashMap();
expireCheckers.put(slaPassChecker.getId(), slaPassChecker);
Condition expireCond =
new Condition(expireCheckers, slaPassChecker.getId()
+ ".isSlaPassed()");
List actions = new ArrayList();
List slaActions = sla.getActions();
for (String act : slaActions) {
if (act.equals(SlaOption.ACTION_ALERT)) {
SlaAlertAction slaAlert =
new SlaAlertAction("slaAlert", sla, execId);
actions.add(slaAlert);
} else if (act.equals(SlaOption.ACTION_CANCEL_FLOW)) {
KillExecutionAction killAct =
new KillExecutionAction("killExecution", execId);
actions.add(killAct);
}
}
Trigger slaTrigger =
new Trigger("azkaban_sla", "azkaban", triggerCond, expireCond,
actions);
slaTrigger.getInfo().put("monitored.finished.execution",
String.valueOf(execId));
slaTrigger.setResetOnTrigger(false);
slaTrigger.setResetOnExpire(false);
logger.info("Ready to put in the sla trigger");
triggerManager.insertTrigger(slaTrigger);
logger.info("Sla inserted.");
}
}
}
WebServer总结
下边用一张图简单总结

ExecServer
暴露Restful API
Azkaban3.0后就开始支持多执行节点部署。单个执行节点比较简单,对web暴露的API也比较少,主要是:
- ExecutorServlet 主要提供执行、取消、暂停、日志查询等接口。
执行作业
这里简单看下执行节点执行一个作业的流程是怎样的。我们在ExecutorServlet中看到所有的执行作业请求都经过handleAjaxExecute方法,这个方法简单地将执行id传递给FlowRunnerManager:
private void handleAjaxExecute(HttpServletRequest req,
Map respMap, int execId) throws ServletException {
try {
flowRunnerManager.submitFlow(execId);
} catch (ExecutorManagerException e) {
e.printStackTrace();
logger.error(e);
respMap.put(RESPONSE_ERROR, e.getMessage());
}
}
FlowRunnerManager 通过submitFlow方法提交工作流去执行。先是构建执行实例ExecutableFlow,然后准备执行目录setupFlow(flow),然后生成FlowRunner,然后提交到线程池去运行executorService.submit(runner)。
public void submitFlow(int execId) throws ExecutorManagerException {
// Load file and submit
if (runningFlows.containsKey(execId)) {
throw new ExecutorManagerException("Execution " + execId
+ " is already running.");
}
ExecutableFlow flow = null;
flow = executorLoader.fetchExecutableFlow(execId);
if (flow == null) {
throw new ExecutorManagerException("Error loading flow with exec "
+ execId);
}
// Sets up the project files and execution directory.
setupFlow(flow);
// Setup flow runner
FlowWatcher watcher = null;
ExecutionOptions options = flow.getExecutionOptions();
if (options.getPipelineExecutionId() != null) {
Integer pipelineExecId = options.getPipelineExecutionId();
FlowRunner runner = runningFlows.get(pipelineExecId);
if (runner != null) {
watcher = new LocalFlowWatcher(runner);
} else {
watcher = new RemoteFlowWatcher(pipelineExecId, executorLoader);
}
}
int numJobThreads = numJobThreadPerFlow;
if (options.getFlowParameters().containsKey(FLOW_NUM_JOB_THREADS)) {
try {
int numJobs =
Integer.valueOf(options.getFlowParameters().get(
FLOW_NUM_JOB_THREADS));
if (numJobs > 0 && (numJobs <= numJobThreads || ProjectWhitelist
.isProjectWhitelisted(flow.getProjectId(),
WhitelistType.NumJobPerFlow))) {
numJobThreads = numJobs;
}
} catch (Exception e) {
throw new ExecutorManagerException(
"Failed to set the number of job threads "
+ options.getFlowParameters().get(FLOW_NUM_JOB_THREADS)
+ " for flow " + execId, e);
}
}
FlowRunner runner =
new FlowRunner(flow, executorLoader, projectLoader, jobtypeManager);
runner.setFlowWatcher(watcher)
.setJobLogSettings(jobLogChunkSize, jobLogNumFiles)
.setValidateProxyUser(validateProxyUser)
.setNumJobThreads(numJobThreads).addListener(this);
configureFlowLevelMetrics(runner);
// Check again.
if (runningFlows.containsKey(execId)) {
throw new ExecutorManagerException("Execution " + execId
+ " is already running.");
}
// Finally, queue the sucker.
runningFlows.put(execId, runner);
try {
// The executorService already has a queue.
// The submit method below actually returns an instance of FutureTask,
// which implements interface RunnableFuture, which extends both
// Runnable and Future interfaces
Future future = executorService.submit(runner);
// keep track of this future
submittedFlows.put(future, runner.getExecutionId());
// update the last submitted time.
this.lastFlowSubmittedDate = System.currentTimeMillis();
} catch (RejectedExecutionException re) {
throw new ExecutorManagerException(
"Azkaban server can't execute any more flows. "
+ "The number of running flows has reached the system configured limit."
+ "Please notify Azkaban administrators");
}
}
FlowRunner本身也继承与Runnable,其run方法里边调用了 runFlow方法,方法内容如下。方法里按照树的层次结构逐层访问DAG图的每一个job,逐个去提交执行。
private void runFlow() throws Exception {
logger.info("Starting flows");
runReadyJob(this.flow);
updateFlow();
while (!flowFinished) {
synchronized (mainSyncObj) {
if (flowPaused) {
try {
mainSyncObj.wait(CHECK_WAIT_MS);
} catch (InterruptedException e) {
}
continue;
} else {
if (retryFailedJobs) {
retryAllFailures();
} else if (!progressGraph()) {
try {
mainSyncObj.wait(CHECK_WAIT_MS);
} catch (InterruptedException e) {
}
}
}
}
}
logger.info("Finishing up flow. Awaiting Termination");
executorService.shutdown();
updateFlow();
logger.info("Finished Flow");
}
对于单个job,最后构造一个JobRunner去执行之。
private void runExecutableNode(ExecutableNode node) throws IOException {
// Collect output props from the job's dependencies.
prepareJobProperties(node);
node.setStatus(Status.QUEUED);
JobRunner runner = createJobRunner(node);
logger.info("Submitting job '" + node.getNestedId() + "' to run.");
try {
executorService.submit(runner);
activeJobRunners.add(runner);
} catch (RejectedExecutionException e) {
logger.error(e);
}
;
}
private JobRunner createJobRunner(ExecutableNode node) {
// Load job file.
File path = new File(execDir, node.getJobSource());
JobRunner jobRunner =
new JobRunner(node, path.getParentFile(), executorLoader,
jobtypeManager);
if (watcher != null) {
jobRunner.setPipeline(watcher, pipelineLevel);
}
if (validateUserProxy) {
jobRunner.setValidatedProxyUsers(proxyUsers);
}
jobRunner.setDelayStart(node.getDelayedExecution());
jobRunner.setLogSettings(logger, jobLogFileSize, jobLogNumFiles);
jobRunner.addListener(listener);
if (JobCallbackManager.isInitialized()) {
jobRunner.addListener(JobCallbackManager.getInstance());
}
configureJobLevelMetrics(jobRunner);
return jobRunner;
}
每个jobRunner在执行的时候,都去插件模块里边寻找对应的插件来进行job的类型加载。每种job类型都有对应的run方法。最后就是调用run方法去执行job。各种不同类型的job可以参考azkaban默认的job类型以及 azkaban-plugin工程里边实现的一些hadoop相关作业类型。
try {
job = jobtypeManager.buildJobExecutor(this.jobId, props, logger);
} catch (JobTypeManagerException e) {
logger.error("Failed to build job type", e);
return false;
}
Azkaban Plugin
azkaban的插件机制使得可以非常方便的增加插件类型,从而支持运行更多的作业类型。azkaban的hadoop插件可以从以下仓库中找到:
git clone https://github.com/azkaban/azkaban-plugins.git
插件的实现
其中插件的类继承关系图如下。每种插件作业都会单独起一个进程去执行。其中ProcessJob就是负责起进程的一个类;JavaProcessJob继承自它,特化为Java进程;其他的hadoop插件又各自继承自JavaProcessJob。如果要自己实现插件类型,只要继承JavaProcessJob类,在继承子类里边调用插件的Wrapper类就可以了。具体细节可以看代码实现。
