官网实例
http://scikit-learn.org/stable/auto_examples/index.html
翻译
biclustering 双聚类
calibration 度量
Classification 分类
Clustering 聚类
covariance 协方差
estimation 评估
Cross decomposition 交叉分解
Ensemble 全体
gaussian 高斯的
Generalized 常用的
manifold 多样的
Plot 画图
isotonic 等分的,等张的,等压的
Scikit-learn项目最早由数据科学家 David Cournapeau 在 2007 年发起,需要NumPy和SciPy等其他包的支持,是Python语言中专门针对机器学习应用而发展起来的一款开源框架。
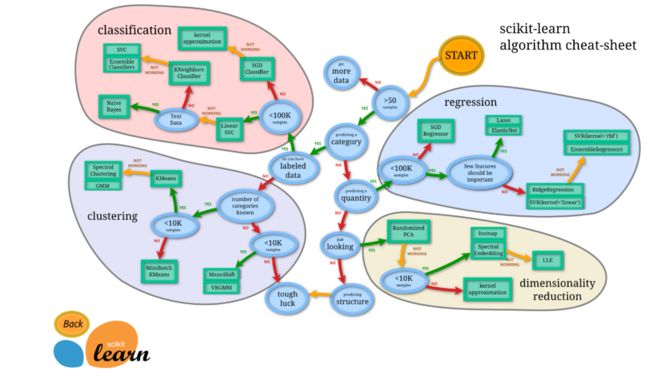
Scikit-learn的六大功能
Scikit-learn的基本功能主要被分为六大部分:分类,回归,聚类,数据降维,模型选择和数据预处理。
分类是指识别给定对象的所属类别,属于监督学习的范畴,最常见的应用场景包括垃圾邮件检测和图像识别等。目前Scikit-learn已经实现的算法包括:支持向量机(SVM),最近邻,逻辑回归,随机森林,决策树以及多层感知器(MLP)神经网络等等。
需要指出的是,由于Scikit-learn本身不支持深度学习,也不支持GPU加速,因此这里对于MLP的实现并不适合于处理大规模问题。有相关需求的读者可以查看同样对Python有良好支持的Keras和Theano等框架。
回归是指预测与给定对象相关联的连续值属性,最常见的应用场景包括预测药物反应和预测股票价格等。目前Scikit-learn已经实现的算法包括:支持向量回归(SVR),脊回归,Lasso回归,弹性网络(Elastic Net),最小角回归(LARS ),贝叶斯回归,以及各种不同的鲁棒回归算法等。可以看到,这里实现的回归算法几乎涵盖了所有开发者的需求范围,而且更重要的是,Scikit-learn还针对每种算法都提供了简单明了的用例参考。
聚类是指自动识别具有相似属性的给定对象,并将其分组为集合,属于无监督学习的范畴,最常见的应用场景包括顾客细分和试验结果分组。目前Scikit-learn已经实现的算法包括:K-均值聚类,谱聚类,均值偏移,分层聚类,DBSCAN聚类等。
数据降维是指使用主成分分析(PCA)、非负矩阵分解(NMF)或特征选择等降维技术来减少要考虑的随机变量的个数,其主要应用场景包括可视化处理和效率提升。
模型选择是指对于给定参数和模型的比较、验证和选择,其主要目的是通过参数调整来提升精度。目前Scikit-learn实现的模块包括:格点搜索,交叉验证和各种针对预测误差评估的度量函数。
数据预处理是指数据的特征提取和归一化,是机器学习过程中的第一个也是最重要的一个环节。这里归一化是指将输入数据转换为具有零均值和单位权方差的新变量,但因为大多数时候都做不到精确等于零,因此会设置一个可接受的范围,一般都要求落在0-1之间。而特征提取是指将文本或图像数据转换为可用于机器学习的数字变量。
需要特别注意的是,这里的特征提取与上文在数据降维中提到的特征选择非常不同。特征选择是指通过去除不变、协变或其他统计上不重要的特征量来改进机器学习的一种方法。
总结来说,Scikit-learn实现了一整套用于数据降维,模型选择,特征提取和归一化的完整算法/模块,虽然缺少按步骤操作的参考教程,但Scikit-learn针对每个算法和模块都提供了丰富的参考样例和详细的说明文档。
安装
conda install -n tensorflow scikit-learn
k近邻分类
import sys
print(sys.version)
'''
3.5.3 |Continuum Analytics, Inc.| (default, May 15 2017, 10:43:23) [MSC v.1900 64 bit (AMD64)]
'''
from sklearn import datasets
print('k近邻分类')
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
#加载花的数据
iris=datasets.load_iris()
iris_X=iris.data#每个图片抽取四个元素 [ 6.5 3. 5.2 2. ]
iris_Y=iris.target#标签,0,1,2三个分类
print(iris_X[:2,:])#取前两个元素
print(iris_Y)
x_train,x_test,y_train,y_test=train_test_split(iris_X,iris_Y,test_size=0.3)#0.3为分割比例
knn=KNeighborsClassifier()
knn.fit(x_train,y_train)#开始训练
print(knn.predict(x_test))#预测
print(y_test)#与实际值对比
波士顿线性回归预测
import sys
print(sys.version)
'''
3.5.3 |Continuum Analytics, Inc.| (default, May 15 2017, 10:43:23) [MSC v.1900 64 bit (AMD64)]
'''
from sklearn import datasets
from sklearn import linear_model
import matplotlib.pyplot as plt
print('波士顿线性回归预测')
data=datasets.load_boston()
data_x=data.data
data_y=data.target
model=linear_model.LinearRegression()
model.fit(data_x,data_y)
predict_data=model.predict(data_x[:4])
print(predict_data)
print(data_y[:4])
'''
y=0.3x+9
model.coef_ 0.3
model.intercept_ 9
'''
print(model.score(data_x,data_y))#模型打分
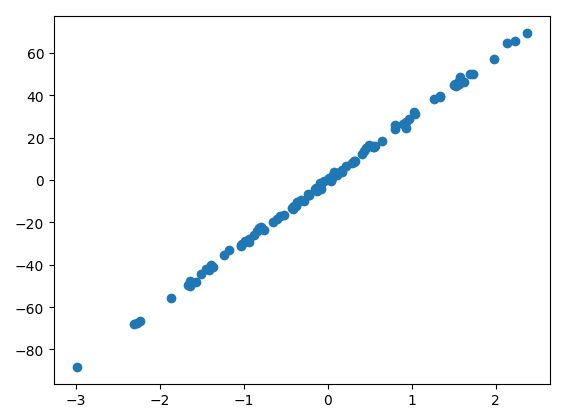
print('自己创建数据集')
x,y=datasets.make_regression(n_samples=100,n_features=1,n_targets=1,noise=1)#n_features 数据属性
plt.scatter(x,y)
plt.show()
标准化数据svm分类处理
import sys
print(sys.version)
'''
3.5.3 |Continuum Analytics, Inc.| (default, May 15 2017, 10:43:23) [MSC v.1900 64 bit (AMD64)]
'''
print('标准化数据svm分类处理')
# 标准化数据模块
from sklearn import preprocessing
# 生成适合做classification资料的模块
from sklearn.datasets.samples_generator import make_classification
# Support Vector Machine中的Support Vector Classifier
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
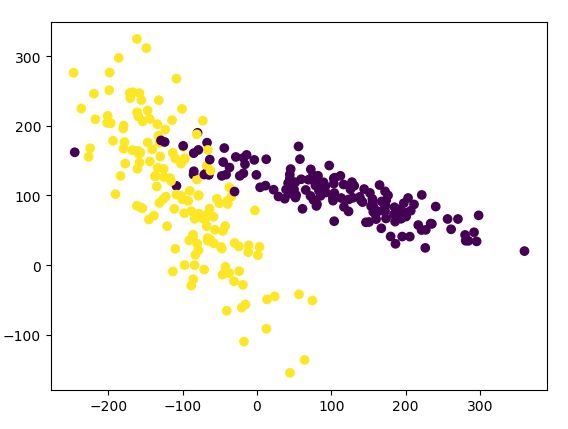
#生成具有2种属性的300笔数据,random_state随机器种子
X, y = make_classification(
n_samples=300, n_features=2,
n_redundant=0, n_informative=2,
random_state=22, n_clusters_per_class=1,
scale=100)
#可视化数据
plt.scatter(X[:, 0], X[:, 1], c=y)#X[:, 0]取数组中每行的第一个元素,c=y颜色
plt.show()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
# 0.477777777778
X = preprocessing.scale(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
# 0.9
交叉验证实战
import sys
print(sys.version)
'''
3.5.3 |Continuum Analytics, Inc.| (default, May 15 2017, 10:43:23) [MSC v.1900 64 bit (AMD64)]
'''
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score # K折交叉验证模块
print('交叉验证实战')
#加载iris数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
#分割数据并
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4)
#建立模型
knn = KNeighborsClassifier()
#训练模型
knn.fit(X_train, y_train)
#将准确率打印出
print(knn.score(X_test, y_test))
#使用K折交叉验证模块
scores = cross_val_score(knn, X, y, cv=5, scoring='accuracy')
#将5次的预测准确率打印出
print(scores)
# [ 0.96666667 1. 0.93333333 0.96666667 1. ]
#将5次的预测准确平均率打印出
print(scores.mean())
# 0.973333333333
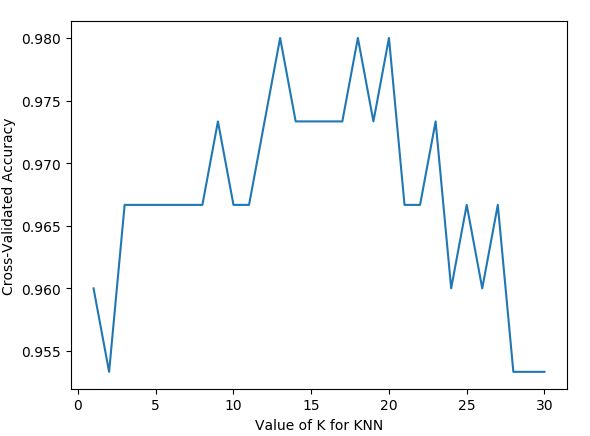
#建立测试参数集
k_range = range(1, 31)
k_scores = []
#藉由迭代的方式来计算不同参数对模型的影响,并返回交叉验证后的平均准确率
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy')
k_scores.append(scores.mean())
# 一般来说平均方差(Mean squared error)会用于判断回归(Regression)模型的好坏。
# loss = -cross_val_score(knn, X, y, cv=10, scoring='mean_squared_error')
# k_scores.append(loss.mean())
#可视化数据
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.show()
过拟合判断
import sys
print(sys.version)
'''
3.5.3 |Continuum Analytics, Inc.| (default, May 15 2017, 10:43:23) [MSC v.1900 64 bit (AMD64)]
'''
from sklearn.model_selection import learning_curve #学习曲线模块
from sklearn.datasets import load_digits #digits数据集
from sklearn.svm import SVC #Support Vector Classifier
import matplotlib.pyplot as plt #可视化模块
import numpy as np
digits = load_digits()
X = digits.data
y = digits.target
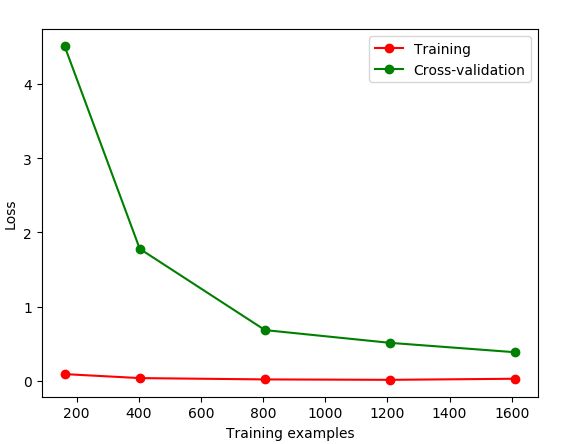
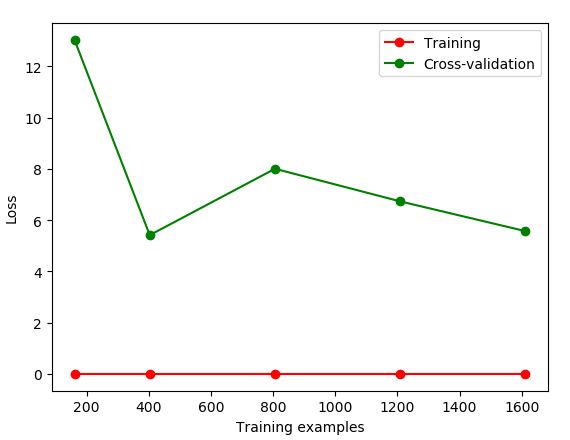
train_sizes, train_loss, test_loss = learning_curve(
SVC(gamma=0.001), X, y, cv=10, scoring='neg_mean_squared_error',
train_sizes=[0.1, 0.25, 0.5, 0.75, 1])
#平均每一轮所得到的平均方差(共5轮,分别为样本10%、25%、50%、75%、100%)
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
plt.plot(train_sizes, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(train_sizes, test_loss_mean, 'o-', color="g",
label="Cross-validation")
plt.xlabel("Training examples")
plt.ylabel("Loss")
plt.legend(loc="best")#显示标签
plt.show()
将gamma=0.01,出现过拟合
如何通过交叉验证选择合适的模型参数
import sys
print(sys.version)
'''
3.5.3 |Continuum Analytics, Inc.| (default, May 15 2017, 10:43:23) [MSC v.1900 64 bit (AMD64)]
'''
from sklearn.model_selection import validation_curve #validation_curve模块
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
#digits数据集
digits = load_digits()
X = digits.data
y = digits.target
#建立参数测试集
'''
np.logspace(0,9,10,base=2)
2的0次方-2的9次方,取10个值,如果没有设置base,则默认是10
'''
param_range = np.logspace(-6, -2.3, 5)
#使用validation_curve快速找出参数对模型的影响
train_loss, test_loss = validation_curve(
SVC(), X, y, param_name='gamma', param_range=param_range, cv=10, scoring='neg_mean_squared_error')
#平均每一轮的平均方差
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
#可视化图形
plt.plot(param_range, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(param_range, test_loss_mean, 'o-', color="g",
label="Cross-validation")
plt.xlabel("gamma")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()

发现当gamma参数在0.0005时准确率最高
保存模型
通过pickle保存,要新建文件夹save
import sys
print(sys.version)
'''
3.5.3 |Continuum Analytics, Inc.| (default, May 15 2017, 10:43:23) [MSC v.1900 64 bit (AMD64)]
'''
from sklearn import svm
from sklearn import datasets
clf = svm.SVC()
iris = datasets.load_iris()
X, y = iris.data, iris.target
clf.fit(X,y)
import pickle #pickle模块
#保存Model(注:save文件夹要预先建立,否则会报错)
with open('save/clf.pickle', 'wb') as f:
pickle.dump(clf, f)
#读取Model
with open('save/clf.pickle', 'rb') as f:
clf2 = pickle.load(f)
#测试读取后的Model
print(clf2.predict(X[0:1]))
# [0]
通过joblib保存,速度要快些,使用要简单些
import sys
print(sys.version)
'''
3.5.3 |Continuum Analytics, Inc.| (default, May 15 2017, 10:43:23) [MSC v.1900 64 bit (AMD64)]
'''
from sklearn import svm
from sklearn import datasets
clf = svm.SVC()
iris = datasets.load_iris()
X, y = iris.data, iris.target
clf.fit(X,y)
from sklearn.externals import joblib #jbolib模块
#保存Model(注:save文件夹要预先建立,否则会报错)
joblib.dump(clf, 'save/clf.pkl')
#读取Model
clf3 = joblib.load('save/clf.pkl')
#测试读取后的Model
print(clf3.predict(X[0:1]))
# [0]