一.相关的概念
Rowid的概念:rowid是一个伪列,是系统自己给加上的。 对每个表都有一个rowid的伪列,不能删除修改、插入。一旦一行数据插入数据库,则rowid在该行的生命周期内是唯一的,即即使该行产生行迁移,行的rowid也不会改变。
Driving Table(驱动表):该表又称为外层表(OUTER TABLE)。这个概念用于嵌套与HASH连接中。如果驱动表row source返回较多的行数据,则对所有的后续操作有负面影响。 一般说来,是应用查询的限制条件后,返回较少行源的表作为驱动表,所以如果一个大表在WHERE条件有有限制条件(如等值限 制),则该大表作为驱动表也是合适的。
Probed Table(被探查表):该表又称为内层表(INNER TABLE)。在我们从驱动表中得到具体一行的数据后,在该表中寻找符合连接条件的行。所以该表应当为大表(实际上应该为返回较大row source的表)且相应的列上应该有索引。
二.oracle访问数据的存取方法
1) 全表扫描(Full Table Scans, FTS)
为实现全表扫描,Oracle读取表中所有的行,并检查每一行是否满足语句的WHERE限制条件一个多块读操作可以使一次I/O能读取多块数据块,而不是只读取一个数据块,这极大的减 少了I/O总次数,提高了系统的吞吐量,所以利用多块读的方法可以十分高效地实现全表扫描,而且只有在全表扫描的情况下才能使用多块读操作。在这种访问模 式下,每个数据块只被读一次。

2) 通过ROWID的表存取(Table Access by ROWID或rowid lookup)
行的ROWID指出了该行所在的数据文件、数据块以及行在该块中的位置,所以通过ROWID来存取数据可以快速定位到目标数据上,是Oracle存取单行数据的最快方法。 这种存取方法不会用到多块读操作,一次I/O只能读取一个数据块。我们会经常在执行计划中看到该存取方法,如通过索引查询数据。 使用ROWID存取的方法:
SQL> explain plan for select * from dept where rowid = ''AAAAyGAADAAAAATAAF'';
3)索引扫描(Index Scan或index lookup)
我们先通过index查找到数据对应的rowid值(对于非唯一索引可能返回多个rowid值),然后根据rowid直接从表中得到具体的数据,这 种查找方式称为索引扫描或索引查找(index lookup)。如果表比较大,则其数据不可能全在内存中,所以其I/O很有可能是物理I/O,这 是一个机械操作,相对逻辑I/O来说,是极其费时间的。所以如果多大表进行索引扫描,取出的数据如果大于总量的5% —— 10%,使用索引扫描会效率下降很多。
BY INDEX ROWID

RANGE SCAN

排序的时候也需要索引,如果没有也可能会引发FULL TABLE ACCESS。

三、表之间的连接
Oracle中,两个表之间关联JOIN查询的话,有很多种方式,比较常用的有:
- 排序 - - 合并连接(Sort Merge Join (SMJ) )
- 嵌套循环(Nested Loops (NL) )
- 哈希连接(Hash Join)
最常见的是后两种。
简单的一个例子:
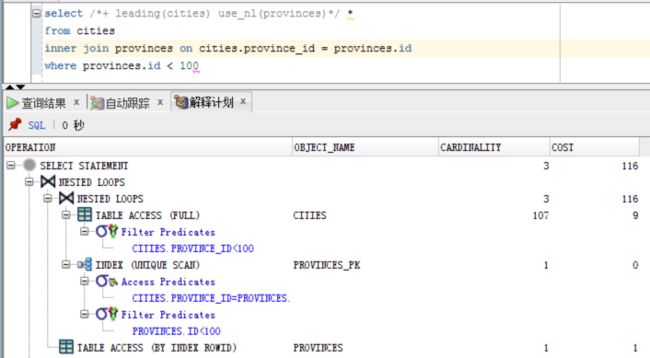
select *
from cities
inner join provinces on cities.province_id = provinces.id
where provinces.id < 100
嵌套循环(Nested Loops (NL) ),就是先做provinces检索,然后对每一个provinces的记录的id,取循环取cities的数据。
provinces id = 1 -----> cities
provinces id = 2-----> cities
provinces id = 3 -----> cities
provinces id = 4 -----> cities

所以,如果数据量很大的话,嵌套循环是一个比较耗时的操作,所以在join的过程中,一般而言千万不要把数据量大的表设置为驱动表。
刚刚的例子,对比一下,如果我强制使用数据量大一点的cities来做驱动表,COST显著由4变成了116。
注意SQL语句中的/*+ leading(cities) use_nl(provinces) */,虽然是注释语句,但是在Oracle可以起到修改执行计划的作用。
当然针对嵌套循环的不足,Oracle引入了依靠哈希连接(Hash Join),这种方式通过哈希运算来得到连接结果集的表连接方法,具体的算法不深究,它主要是避开了嵌套循环的多次查询,一次性取出足够的数据进行连接运算,大大提升了查询的效率,当然内存的消耗也会大大增加。哈希连接中驱动表的顺序是也是非常重要的,性能差别也大。据我观察,业务中,哈希连接的性能通常要优于嵌套循环,但也不是绝对。
这是上面的例子,强制使用哈希连接的方式来执行:

在使用的过程中,Oracle会非常智能的完成执行计划的优化工作,根据成本最小化的原则来确定具体使用哪种方式来操作,但是在很多极端情况,Oracle选择的方式未必是最佳的。这就要求我们在写SQL的时候思路逻辑要非常清晰,不要犯一些基本的错误,就能大大避免异常情况。
另外需要提醒的是NULL要慎用:

四、思考题
最后给大家一个思考题,看一下下面这个,来自于业务中的SQL(被我简化了),看上去写的很规整很漂亮,有没有什么问题?
select distinct brands.*
from product_prices
inner join products on products.id = product_prices.product_id
inner join brands on brands.id = products.brand_id
inner join product_batches on product_prices.batch_id = product_batches.id
where
(quotation_batches.id =289859 OR quotation_batches.group_id =289859)
and products.publish_stage IN (0,1)
and brands.status NOT IN (1,2)