题目:Robust Online Multi-Object Tracking based on Tracklet Confidence and Online Discriminative Appearance Learning
来源:CVPR 2014
论文主页(有matlab代码):https://cvl.gist.ac.kr/project/cmot.html
本文主要解决的是轨迹问题,甚至在出现严重遮挡的情况下还能有很好的轨迹。
先插播个广告哈!对理解本paper很有用!
多目标跟踪(MOT)
比如说,有一段视频,视频是由 N 个 连续帧构成的。从第一帧到最后一帧,里面有多个目标,不断地有出有进,不断地运动。我们的目的是对每个目标,能跟其他目标区分开,能跟踪它在不同帧中的轨迹。最经典的应用就是路口监控中看到的行人了。
Input: detection responses。
现在拿来一段视频,我们先用 state-of-art detectors 把各帧中的人检测出来,包括位置、大小。当然,这个检测是有 noise 的,否则也就没必要用各种 MOT 方法来处理了。每个 detection产生的结果就是 response,它还有一个可信度,比如80%可信,20%可信。
Output: Tracklets. 就是最终得到每个 target 的轨迹。
Challenges: Occlusions、similar appearance、complex motion,、false alarms
Occlusions:有三种,即被场景中的物体遮挡,被其他 target 遮挡,被自己遮挡(如变形,无法检测到)。遮挡之后,本来应该检测到的target 就检测不到了。解决的方法如根据 temporal 信息,估计出某一帧的某个位置有 target 被遮挡了。
Appearance:一是怎么把 target 与背景分开;二是怎么把不同的 target 分开。一般需要设计一个很好的外观模型,比如用 HOG、color histogram 等等。
Motion: 最简单的情况是匀速直线运动,这样我们很好预测下一帧中这个 target 在哪儿,但实际情况往往并不如此。比如可能来了个急转弯,可能突然转身往回走。解决之道,一般要设计更灵活、更复杂的运动模型。
False Alarms: detector 给出了 response,但实际上那个地方并没有 target,也就是说误检了。这就要根据可信度,以及多种 refinement (细化)方法来甄别了。
Approaches
目前比较有代表性的有两种:
1、Detection-based data association.
多目标跟踪,可以看作一个数据关联问题,连续两帧之间的tracklets or detections 做 link,形成 Longer tracklets。
最经典的框架是Nevatia 他们在2008年 ECCV 发表的论文Robust Object Tracking by Hierarchical Association of Detection Responses中提出的多层跟踪框架。
low-level:把连续帧中的 detection responses 连起来成为 short tracklets,并用阈值去掉 unsafe 的,剩下 reliable tracklets。
mid-level:对 low-level 得到的 tracklets,对每对tracklet 计算一个 link probability 或 affinity score,然后用 Hungarian 算法做 global optimal assignment,得到 longer tracklets.
high-level:这里就是对 mid-level 得到的 tracklets 做 refine 了,比如做一个 entry-exit map,估计tracklets 的 start 和 end,对于没有 reach entry-exit points 的,做一个 completion。如,寻找 moving group,并据此完善 group 中的 targets 的 tracklets。
这三层是一个基础性的、开放的框架,人们可以在每个层次中不断添加使用新的方法,可以看到,许多论文都是构建在这个框架上的。
2、Energy minimization.
很多问题都可以转化为一个能量最小化的问题:在解空间中,每个解都对应一个 cost或者说是 energy,我们要做的就是把这个 cost function 表示出来,并找到一个合适的方法求最优解。MOT 大神 Anton Milan 在2014年 PAMI 发表的Continuous Energy Minimization for Multi-Target Tracking就是一个典型。已知的是所有 detection responses,解空间就是这些个 responses 构成的所有可能的 tracklets 组合。每个组合都有一个 cost ,寻找一个最优的组合。本文清晰的阐述了 cost function 的构成以及 minimization。值得一提的是,大神的这篇文章构造了一个连续的 cost function,这样容易求解;它用了 jump move,跳出局部最优,寻找全局最优。
啊,不愧是大神啊。
广告插播结束,下面接着说论文吧。
Abstract
在线的多目标跟踪蛮难的
because of frequent occlusion by clutter or other objects, similar appearances of different objects, and other factors.
虽然难,但也不是没有解决方法。
In this paper, we propose a robust online multi-object tracking method that can handle these difficulties effectively.
具体的工作流程如下:
We first propose the tracklet confidence using the detectability(可检测性)and continuity(连续性)of a tracklet, and formulate a multi-object tracking problem based on the tracklet confidence.
The multi-object tracking problem is then solved by associating tracklets in different ways according to their confidence values.
Based on this strategy, tracklets sequentially grow with online-provided detections, and fragmented tracklets are linked up with others without any iterative and expensive associations.
Here, for reliable association between tracklets and detections, we also propose a novel online learning method using an incremental linear discriminant analysis(ILDA) for discriminating the appearances of objects.(也就是说用ILDA的作用是通过判别物体的外观确保tracklets和detections之间的可信赖的关联)
By exploiting the proposed learning method, tracklet association can be successfully achieved even under severe occlusion.
1. Introduction
The goal of multi-object tracking is to estimate the states of multiple objects while conserving their identifications under appearance and motion variations with time.(在外观和运动发生变化的情况下,MOT的作用是估计状态states和保持id)
多目标跟踪存在的挑战是:
In a complex scene, this problem is especially challenging due to frequent occlusion by clutter or other objects, similar appearances of different objects, and so on.(MOT的最大挑战就是频繁遮挡和外观相似)
现如今,提出了一种tracking-by-detection methods,在性能上有很大的改进。因为即使在拥挤的环境下也能提供可靠的detections。可见,良好的detections是有利于跟踪的。
The tracking-by-detection methods generally build long trajectories of objects by associating detections provided by detectors.
分成2类,batch and online methods。(哇哦,Multiple Object Tracking: A Literature Review上也有说耶!)
1、Batch methods
Batch methods usually utilize the detections of whole frames together to link fragmented
trajectories (i.e. tracklets) due to occlusion.
However, the performance of the batch methods is still limited under long-term occlusion because of the difficulty in distinguishing different objects.It is thus difficult to apply the batch methods to real-time applications.(因为这种方法要求huge computation due to the iterative associations for generating globally optimized tracks)
batch method这种方法:detection=>traclets=>trajectories。在发生频繁遮挡的情况下,因为难于判别不同物体,效果不是很好。
2、Online methods
Online methods can be applied to real-time applications because they sequentially(顺序) build trajectories based on frame-by-frame(逐帧)association using online information up to the present frame.
However,online methods tend to produce fragmented trajectories and to drift under occlusion.
有问题也是小case啦,本文提出的方法可以解决上述的问题。
The proposed method is based on:
(1) tracklet confidence to handle track fragments due to occlusion or unreliable detections (说明了跟踪碎片产生的原因是occlusion和unreliable detections,tracklet confidence就是用来处理跟踪碎片的)
(2) online discriminative appearance learning to handle similar appearances of different objects in tracklet association.(在进行traclet association的时候,用ILDA来处理不同物体的相似外观)
解决多目标跟踪问题的strategy:associating tracklets in different ways according to their confidence values,更加具体的讲:
reliable tracklets having high confidence are locally associated with online-provided detections,whereas fragmented tracklets having low confidence are globally associated with other tracklets and detections.
我们可以看出,the core steps of the proposed method are the local and global associations.
并且,In both steps,appearance modeling is crucial for associating tracklets and detections of the same object while distinguishing different objects.
也就是说,在局部关联和全局关联这两个步骤中,外观学习是十分重要的。
在这里,外观学习是很关键的,在这种情况下:区分不同的物体时,把同一个物体检测出来,并且把小段轨迹给关联起来。
名词:ILDA,指的是incremental linear discriminant analysis(增量线性判别分析)
To this end(为此), we also propose a novel online discriminative appearance learning taking into consideration two main issues in multi-object tracking:
在多目标跟踪领域的两个问题:
(1) online learning to update appearance models according to ongoing(持续) tracking results
(根据持续的跟踪结果在线更新外观模型)=======> appearance model update
(2)online training sample collection for discriminating appearances of multiple tracked objects
(在线训练用于区分多个跟踪对象的外观的样本集合)==========> good training samples
The proposed online learning method is designed in consideration of two issues together to learn discriminative appearance models using an incremental linear discriminant analysis (ILDA).
ILDA特别好,一下子解决了model update 和samples的问题。具体说来,This allows us to distinguish each object and also incrementally update learned appearance models with online tracking results.
By exploiting the proposed appearance learning, tracklet assocition can be successfully performed even under occlusion.(由于有个好外观,所以在发生遮挡的情况下,也能成功的进行轨迹关联)
本文的贡献点:
(i) proposition(提出) of a tracklet confidence for evaluating tracklet’s reliability(可靠性), and two-step association using the tracklet confidence for building optimal tracklets
(提出用于评估tracklet可靠性的tracklet置信度,以及使用tracklet置信度来建立最佳Tracklet的两步关联)
(ii) proposition of an online learning method for discriminating different objects and adapting learned appearances with ongoing tracking results
(提出一种用于区分不同的对象的在线学习方法,并通过持续的跟踪结果调整学习的外观)
(iii) proposition of a practical whole online tracking structure by effectively combining our methods
(通过有效结合我们的方法,提出实用的整体在线跟踪结构)
这个结构如下所示:
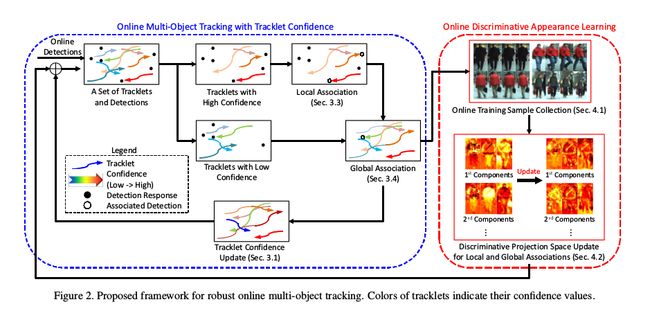
Here, since the tracklet confidence lies in [0, 1], we consider a tracklet as a reliable tracklet with high confidence when conf (T i ) > 0.5; otherwise it is considered as the fragmented tracklet with low-confidence.
2. Related Works
Some previous works related to online multi-object tracking and online appearance learning, the focus of this paper, are introduced in this section.
这部分实际上也是从两个方法介绍的:tracklets+appearance model。
对于tracklets,在线的跟踪方法在本地就frame-by-frame的把detections给build trajectories。对把detections关联成tracklets有很多方法,易drift。在发生遮挡时有一篇文章建议对一下,CVPR2012的:Part-based multiple-person tracking with partial occlusion handling.在本文中,使用一种基于部件(part)的model to correctly associate detections under partial occlusion.
对于appearance model,要是能同时区分具有相似外观的物体,并且根据跟踪结果进行model update就好了。可事实上不是这样。举个例子吧。有些方法在外观上使用了color和other feature histograms,但是却不能处理跟踪物体的外观变化。===>应该更新model。好吧,有些例子采用了用ensemble learning and online boosting的online learning methods更新了model,但是他们的方法是把一个object从background中区分的,rather than from other objects。=======>最好能学习一个Appearance model判别不同的objects,这里可以需要采集samples(collect positive samples from the same traclets and negative samples from other tracklets after low-level associations),可能用到AdaBoost或者MIL instance learning的方法。但是因为是a batch manner,学习到的这种用于判别不同物体的模型难以更新。
3. Online Tracking with Tracklet Confidence
单词释义:
velocity:速度
posterior probability:后验概率
intuitively:直观地
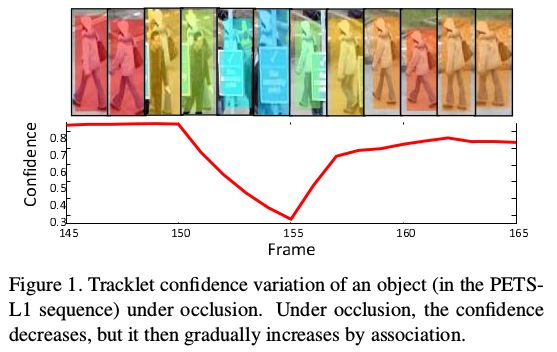
这部分关于的是小轨迹 tracklet confidence。为了理解代码,这部分要仔细研读。

物体 i 在某一帧frame t 的出现是通过a binary function来设值的,设为1或者0。当物体i出现时,物体才是有状态的,这种状态用p,s,v来表示,分别代表position,size和velocity。至此,关于Object这块儿说清楚了。(物体 = 出现?:1+状态)
对于出现的物体(有状态)可以连成轨迹T,这种轨迹往往是up to frame t, we define a tracklet of the object i as a set of states(用直到该帧的一系列状态组成轨迹)
Note that directly solving Eq. (1) is not feasible in practice because the possible combinations of T 1:t and Z 1:t is innumerable.(想要通过最大化后验概率估计的方法,在给定检测Z的情况下,寻找最优的轨迹T,根本行不通,因为T与Z的组合是无穷的)
所以,我们重新设定这种问题,使用的是小段轨迹的置信度。然后,提出了一种切实可行的解决方案。
3.1. Tracklet Confidence
Tracklet confidence can be intuitively(直观地) interpreted as how well the constructed (构建好的)tracklet matches the real trajectory of the object.
一个好的轨迹应该尽可能的与真实的轨迹相match,而这种match程度可以通过tracklet confidence来衡量。
我们所考虑的是满足下列要求的拥有高置信度的可信赖的轨迹。
Length: a short tracklet tends to be unreliable. A long tracklet is more likely to be a correct tracklet of an object.
Occlusion: a severely occluded tracklet by other tracklets is not appropriate as a reliable tracklet.
Affinity(密切关系、相似、近似、亲和力): a high affinity between a tracklet and an associated detection indicates that the tracklets is reliable.
(轨迹和相关检测之间的高亲和力表明轨迹是可靠的。)
cardinality:基数
小段轨迹置信度的相关定义如下:



System parameters: All parameters have been found experimentally, and remained unchanged for all datasets.From an extensive evaluation, we find that most parameters do not affect the overall performance of our system much.In the affinity model in Eq. (10), all parameters (i.e. positions, sizes and velocities) are automatically determined by tracking results except for O F and O B , which were set to diag[30 2 75 2 ]. The same threshold θ = 0.4 is used for the local and global association.
3.2. Formulation with Tracklet Confidence
To effectively solve the online multi-object tracking problem, we reformulate the online multi-object problem Eq. (1) by using the tracklet confidence as

现在,用Eq 3来重新设定要解决的问题,用到了小段轨迹置信度。
问题的解决分成2大阶段来进行。
阶段1:tracklets with high confidence are locally associated with online-provided detections,
阶段2:tracklets with low confidence, which are more likely to be fragmented, are globally associated with other tracklets and detections.
更具体的说,
the tracklets with high confidence are first considered to be locally associated with detections because more reliable detections originate from them rather than from tracklets with low confidence
这样的话,The local association(本地关联)between the tracklets and detections allows us to progressively(逐步)grow locally optimal tracklets with online provided detections.
再次说明一下the reformulate的成果,解决方案是:
高置信度轨迹做本地关联(用online-provided detections)
低置信度轨迹做全局关联(用other tracklets and detections),低置信度轨迹可能是碎片哦。
为了搞懂代码,以下两部分(本地关联和全局关联)必须仔细研究。
3.3. Local Association of Tracklets(超级重要)
下面我们来说说如何做local association。

本地关联中,具有高置信度的轨迹的生成离不开一系列的检测。为把detection responses和tracklets关联起来,用到了pairwise association。在t帧时刻,当h个具有高置信度的轨迹和n个detections存在的时候,就可以定义a score matrix了。之后,我们用匈牙利算法决定tracklet-detection pairs =>so that the total affinity is maximized. When the association cost of a tracklet-detection pair is less than a pre-defined threshold,检测Z就和轨迹进行关联。
对于已经和检测Z关联的轨迹,将进行如下步骤:
1)根据检测Z更新p and v。s也会被更新,通过把最近几帧的关联检测平均化。
2) 使用检测Z和公式2更新置信度conf。
需要说明的是,可以跳过本地关联直接进行全局关联,这样做的结果是计算量大且容易造成歧义,性能Is also degraded。
3.4. Global Association of Tracklets(超级重要)

下面介绍了在不同的Event 下,参数的计算方式。
The same threshold θ used in the local association is also employed to select a reliable association pair having a high affinity score.
Once the cost matrix is computed, the optimal association pairs,which minimize the global association cost in G, are determined using the Hungarian algorithm , and the tracklets and their confidence values are updated with the results.
4. Discriminative Appearance Learning
在这部分,我们就要进行判别式外观的学习了。
In the proposed learning method, online training samples are collected from tracked objects, and a discriminative projection space is updated with the collected samples using ILDA.
(在提出的学习方法中,从跟踪对象收集在线训练样本,并用ILDA法收集的样本来更新判别式投影空间。)
通过将轨迹的外观模型投射到判别式投影空间,我们使轨迹的外观更具判别性。
用新样本更新判别式外观的在线学习方法往往采用ILDA,当然也可以采用the online boosting method 。
The main reason for using ILDA is that appearances of multiple objects can be distinguished with a single updated LDA projection matrix, whereas specific classifiers of the objects are required in the boosting method.
A further benefit of using ILDA lies in its ability to memorize the discriminative information for a long time.This makes it possible to accurately identify objects even under significant pose(姿态) and appearance changes and long-term occlusion.
4.1. Training Sample Collection
在每个帧中,我们围绕轨迹的精细位置,收集不同位置和尺寸的N个图像补丁,用以判别不同的轨迹。But we only extract image patches from the tracklets with high confidence。在本文的图中Training samples from the trackets with high confidence (red) and low confidence (blue)。

我们要提取的是高置信度的图像补丁,即样本。
这里是进行多种samples的采样过程(正样本和负样本~)

啊,ILDA有降维的作用哦。
4.2. Online-Learning Algorithm
一些单词翻译:
scatter:离散
eigenvector:特征向量
incrementally:递增地
sufficient:充足的
eigendecomposition:特征分解
pseudo code:伪代码
identical:一致、相同
还有一些公式,看原文吧!
It is necessary to incrementally update the existing projection matrix with updated samples because not all training samples are available in online multi-object tracking.

Figure 4 shows the updated projection matrices using batch LDA and ILDA, proving the accuracy of ILDA.
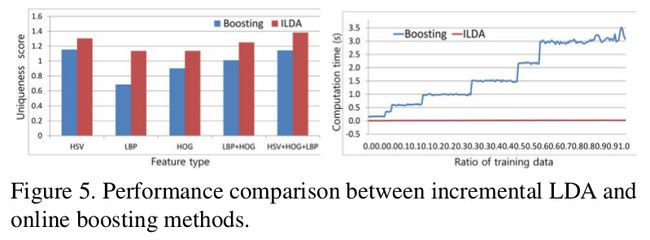
Figure 5中,We can see that the ILDA method is much more effective than the boosting method in terms of computation cost and identification (识别)accuracy.
In the batch LDA, a projection matrix U is constructed(构建).
We employ the ILDA method using sufficient spanning sets by maximizing class separability(可分离性) of the given training set.
这两种方法相关的数学描述看paper。
5. Experiments
略
6. Conclusion
方法是具有有效性和鲁棒性的。
We build optimal(最佳的) tracklets by sequentially linking tracklets and detections using the proposed local and global association according to their confidence.
Furthermore, the proposed online appearance learning allows us to discriminate(区分)multiple objects in both associations even in complex sequences.(即使在复杂的序列中也能区分两个关联中的多个对象。)