关于Cookie的分析我在爬虫笔记(六) - 关于 Cookie 的分析(Postman Request Selenium)中说明了,本次的目标网站也是同一个
本文主要包含一个要点,在分析完请求后,使用不同的方法构造同一个HTTP请求,方法包括:
- Scrapy框架
- Request库
- Chrome的Postman插件
Scrapy中一段让我揪心的代码
在分析前,我说一个自己遇到过的SB问题,在最开始我只放代码~~~
Scrapy中的spider
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
class JobSpider(scrapy.Spider):
name = "job"
def start_requests(self):
base_url = "https://www.lagou.com/jobs/positionAjax.json"
querystring = {"city": "广州", "needAddtionalResult": "false", "kd": "python", "pn": "1"}
headers = {
'user-agent': "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0",
'cookie': "user_trace_token=20170502200739-07d687303c1e44fa9c7f0259097266d6;"
}
yield Request(url=base_url, method="GET", headers=headers)
def parse(self, response):
print response
从Postman中获取到的Request请求
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
# @Time : 2017/5/2 20:24
# @Author : Spareribs
# @File : test_lagou.py
"""
import requests
import json
url = "https://www.lagou.com/jobs/positionAjax.json"
querystring = {"city":"广州","needAddtionalResult":"false","kd":"python","pn":"1"}
headers = {
'user-agent': "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0",
'cookie': "user_trace_token=20170502200739-07d687303c1e44fa9c7f0259097266d6;"
}
response = requests.request("GET", url, headers=headers, params=querystring)
print(response.text)
如果看完这两段代码你看懂了关键点,本文最想突出的核心要点你也看懂了。
看不懂也不急,先看下基础分析
Scrapy框架中的Request请求分析
首先是Request对象中文文档
class scrapy.http.Request(url[, callback, method='GET', headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback])
参数要点:
- url(必填):请求的URL,所说的目标网站
- method='GET'
- headers
- body
- cookies
Scrapy特有:
- encoding='utf-8'
- priority=0
- dont_filter=False
- meta:
- callback:
- errback:
(占位---待继续更新)
Request库中的Request请求分析
中文文档
requests库中requests的方法
def request(method, url, **kwargs):
with sessions.Session() as session:
return session.request(method=method, url=url, **kwargs)
def get(url, params=None, **kwargs):
kwargs.setdefault('allow_redirects', True)
return request('get', url, params=params, **kwargs)
def post(url, data=None, json=None, **kwargs):
return request('post', url, data=data, json=json, **kwargs)
(占位---待继续更新)
Chrome的Postman插件中的Request请求分析
对于Postman的请求,我这里分两种Method分析(其他的爬虫中很少用到)
- Get请求
- Post请求
首先是get请求
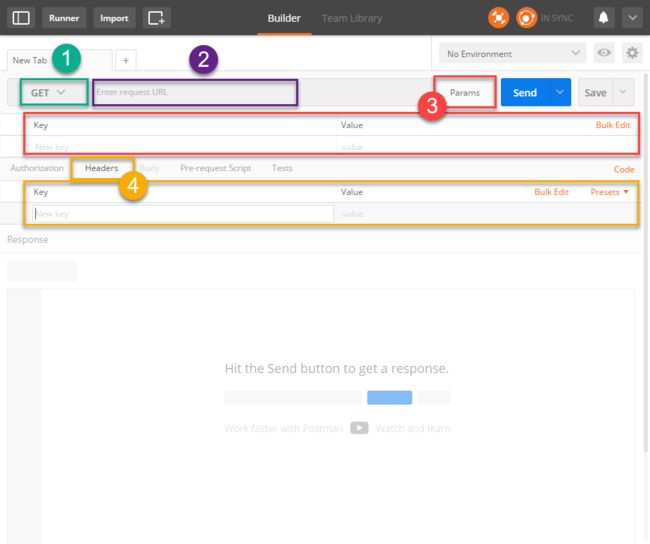
Postman中Get请求
要点:
- 请求的方法:Get
- 请求的URL
- 请求的Params参数
- 请求的Headers头部
然后是Post请求

Postman中Post请求
要点:
- 请求的方法:Post
- 请求的URL
- 请求的Params参数
- 请求的Headers头部
- Request Body(提供了4中编辑方式)
然而,在Post中的4种编辑方式分别为:
- form-data
- x-www-form-urlencoded
- raw
- binary
(占位---待继续更新)
总结:其实我想了很久,一直没想明白,为什么同一个请求放Request库中成功了,而在scrapy中失败了,对于这个问题,其实就是不是很难,就是越简单越害人。Request库的请求的Cookies是可以放到headers中可以辨别的,而Scrapy的Cookies有一个独立的cookies参数来处理Cookie,放在headers中不生效
以上都是我的跟人观点,如果有不对,或者有更好的方法,欢迎留言指正~~~(持续更新中)