第1章 机器学习概述
1.云计算,就是分布式计算,简单来讲就是将一个很复杂的任务进行拆解,由成百上千的机器各自执行任务的一个小模块,然后将结果汇总。
2.人工智能的发展史,就是对于过往经验的收集和分析方法不断演绎的历史。
3.机器学习算法发展到目前阶段,做的事情主要是将生活中的场景抽象成为数学公式,并且依靠机器的超强计算能力,通过迭代和演绎生成模型,对于新的社会问题进行预测或者分类操作。
4.当今世界的人工智能可以总结为数据和智能算法的结合。
5.目前有两方面的瓶颈,一方面是数据产生和数据收集的瓶颈,另一方面是采集到的数据和能被分析的数据之间的瓶颈。
(1)造成目前数据采集与数据生成失衡的主要原因是数据的采集缺乏标准,特别是传统行业来说,数据的采集方式还处于摸索当中
(2)目前可以供分析的数据还只占很小的比例,造成这样的困境主要有两方面因素,一个是目前比较主流的机器学习算法都是监督学习算法,监督学习需要的数据源是打标过的数据,打标数据很多时候是依赖于人工标记;
另一个导致可分析数据比例较低的因素是对于非结构化的数据处理能力较低。虽然目前的科技水平已经具备了文本和图像方面的分析能力,但是在大批量处理和特征提取方面依然处于相对基础的阶段。
6.机器学习方法是计算机利用已有的数据(经验)得出了某种模型,并利用这些模型预测未来的一种方法。这个过程其实与人的学习过程极为相似,只不过机器是一个可以进行大维度数据分析而且可以不知疲倦地学习的“怪兽”而已。
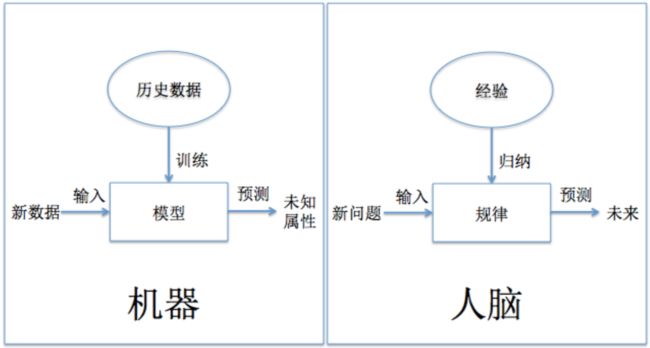
7.机器学习的整个流程大致可以分为 6 个步骤,整个流程按照数据流自上而下的顺序排列,分别是场景解析、数据预处理、特征工程、模型训练、模型评估、离线/在线服务。
(1)场景解析。场景解析就是先把整个业务逻辑想清楚,把自己的业务场景进行一个抽象;场景抽象就是把业务逻辑和算法进行匹配。
(2)数据预处理。数据预处理主要进行数据的清洗工作;数据预处理阶段的主要目标就是减少量纲和噪音数据对于训练数据集的影响。
(3)特征工程。特征工程是机器学习中最重要的一个步骤;在算法相对固定的情况下,可以说好特征决定了好结果。
8.数据源结构:
(1)结构化数据;如日志类数据结构,是以矩阵结构存储在数据库中的数据,可以通过二维表结构来显示。
结构化数据中还有两个非常重要的概念需要介绍一下,即特征(Feature)和目标列(Label)。这是机器学习算法中最常出现的两个名词,其中特征表示的是数据所描述对象的属性;目标列表示的是每一份数据的打标结果,目标列表示的是这一组数据的结果。
(2)半结构化数据;比较典型的半结构化数据就是 XML 扩展名的存储数据,某些字段是文本型的,某些字段是数值型的。
(3)非结构化数据;典型的非结构化数据就是图像、文本或者是语音文件。目前的做法也是通过把非结构化数据转为二进制存储格式,然后通过算法来挖掘其中的信息。
9.算法分类:
监督学习主要解决的是分类和回归的场景,无监督学习主要解决聚类场景,半监督学习解决的是一些打标数据比较难获得的分类场景,强化学习主要是针对流程中不断需要推理的场景。
(1)监督学习;监督学习(Supervised Learning),是指每个进入算法的训练数据样本都有对应的期望值也就是目标值,进行机器学习的过程实际上就是特征值和目标队列映射的过程。
监督学习的一个问题就是获得目标值的成本比较高,需要进行人工标注。
(2)无监督学习;无监督学习主要是用来解决一些聚类场景的问题,因为当我们的训练数据缺失了目标值之后,能做的事情就只剩下比对不同样本间的距离关系。
(3)半监督学习;通过对样本的部分打标来进行机器学习算法的使用。
(4)强化学习;强调的是系统与外界不断地交互,获得外界的反馈,然后决定自身的行为;典型的案例包括无人汽车驾驶和阿尔法狗下围棋。
10.过拟合问题:
即过度拟合,因为这套模型在训练的时候过度地接近于训练集的特征,缺乏鲁棒性(抗变换性);比如模型完美拟合训练集数据,但是换了数据后准确度就会下降,这就叫过拟合。
原因:
(1)训练数据集样本单一
(2)训练样本噪音数据干扰过大
(3)模型过于复杂
解决方法:
(1)在训练和建立模型的时候,一定要从相对简单的模型开始
(2)数据的采样,一定要尽可能地覆盖全部数据种类
(3)在模型的训练过程中,我们也可以利用数学手段预防过拟合现象的发生,可以在算法中添加惩罚函数来预防过拟合
11.结果评估
TP(True Positive):本来是正样本,被模型预测为正样本。
TN(True Negative):本来是负样本,被模型预测为负样本。
FP(False Positive):本来是负样本,被模型预测为正样本。
FN(False Negative):本来是正样本,被模型预测为负样本。
精确度=TP/(TP+FP)(评估的准确度)
召回率=TP/(TP+FN)(评估的覆盖率)
F1= 2×精确率×召回率/(精确率+召回率)
第2章 场景解析
1.数据探查
(1)数据量的大小;指数据条数,一般数据源都是矩阵形式
(2)数据缺失或乱码;需要进行很多的 ETL 操作(抽取extract、转换transform、加载load),称为“数据清洗”。
(3)字段类型;数据库的字段分为整型(int)、字符型(string)、双精度浮点数(double)和单精度浮点数(float)
等,不同算法对字符串类型的支持也是有要求的。
(4)是否含有目标队列;这关系到接下来的算法选择是有监督学习还是无监督学习。如果没有目标队列,需要考虑是否可以通过一些 ETL 操作来生成,这一环节对于接下来算法选择的意义非常重大。
2.场景抽象
场景抽象就是通过已有的数据,挖掘出可以应用的业务场景。目前来看,机器学习主要用来解决的场景包括二分类、多分类、聚类和回归。
(1)商品推荐;推荐的商品是否购买,可以抽象为“是”或“否”的二分类问题
(2)疾病预测;癌症可以简单分为早期、中期、晚期,即可以抽象为多分类的场景
(3)人物关系挖掘;根据通话记录中的通话次数和时长,抽象成数学里面的图论内容,图论包含点、边和权重的概念
(4)把人群按照性别划分,就是聚类场景;预测股票走势,是回归问题;
场景抽象的时候需要具备下面两个能力:一是对于自身的业务有充分的认识;二是对算法逻辑有大概的了解。
3.算法选择
(1)确定算法范围;
第一步:了解数据种类,选择相应的算法;
第二步:判断数据是否存在目标队列,有目标值则选择监督学习的算法;
第三步:根据实际业务场景,选择分类、聚类或回归算法;
(2)多算法尝试;当明确了范围之后,建议可以尽可能地多尝试不同算法的组合。
(3)多视角分析;包括算法的鲁棒性、算法的复杂度以及资源消耗量、算法的调参和优化成本
第3章 数据预处理
1.数据预处理主要包括四种方式:采样、去噪、归一化和数据过滤
2.随机采样分为有放回采样和无放回采样两种。
3.归一化是指一种简化计算的方式,将数据限定在[0,1]。
数据归一化可以加快算法的收敛速度,而且在后续的数据处理上也会比较方便;另外,归一化算法是一种去量纲的行为。
4.去噪有不同的处理方法,常见的一种叫正态分布 3σ 原则。
5.过滤:一般使用数值型数据,因此要过滤掉字符型数据;同时,也要过滤掉一些不具备描述行为特性的数据。这样的过滤处理往往需要依靠 SQL语句来实现。
6.在数据预处理阶段其实目的很简单:把数据集尽量优化成对于算法干扰最小的状态,尽可能地排除数据形式对于模型训练的影响。
第4章 特征工程
特征抽象
1.特征抽象是指将源数据抽象成算法可以理解的数据。
2.特征抽象需要具备两方面能力,一方面是需要进行大量的相关工作来积累经验,另一方面需要对特征抽象的数据的业务场景足够了解。
3.如何利用非结构化数据进行分析呢?如何从复杂的数据中挑选出特征?这就需要我们对数据进行抽象。
(1)时间戳
因为通常采集到的数据往往来自于系统日志,采集到的时间都是“年-月-日”这样的格式,但是因为这种年、月、日的计算并不符合十进制的计算原理,很难对这样结构的数据做加减乘除的处理。
具体的操作方法可以选定一天作为基准,然后取具体日期字段中的数据与这一天的差值 。
(2)二值类问题
这种数据可以通过两个数值来表示,通常可以表示成0和1
(3)多值有序类问题
(4)多值无序类问题(信息阉割)
(5)多值无序类问题(One-hot 编码)
(6)文本类型
(7)图像或语音数据
思路大体是首先将图像或者语音转化成矩阵结构
特征重要性评估
1.特征是具备一定属性的字段,很多时候我们需要了解每个特征对目标列的影响程度,因为特征的权重往往会对业务的决策带来启示。
2.特征评判的方法有很多,有两种常见方法,一种是利用回归模型的参数来评判,另一种是根据信息熵。
特征衍生
1.特征衍生是指利用现有的特征进行某种组合,生成新的具有含义的特征。
2.机器学习算法的特点是通过高维的特征数据来挖掘其中的最优模型,所以我们需要进行一定的特征衍生,增加相应特征量,从而挖掘更有价值的特征来提高算法的结果准确性。
3.在进行特征衍生的过程中,我们可以分别从3 个角度去分析,购物者、商品、购物者和商品的关系:
(1)购物者
· 为了更精确地表示用户购物的热情,可以衍生出一个新特征叫购物频率,购物频率的公式为:
购物频率= 用户总购买量/(用户最后购买时间 - 用户第一次购物时间)
· 对用户的性格刻画,可以衍生一种特征来区分这样两种人群,一种是“光看不买”,还有一种是“一看就买”,把这个特征叫作“点击购买率”,通过公式可以这样表示:
点击购买率= 用户购物行为为0的次数/用户购物行为为1的次数
(2)商品
· 产品的热度;即产品的受欢迎程度,这个指标可以通过两种方式来获得,一种是计算这个商品的总被购买量,另一种是首先算一下全部产品的总购买量然后求平均值,通过总购买量和平均值的对比进行打标。
· 产品的季节因素;需要对产品的被购买行为加上时间序列的考虑
· 产品的消耗频率;这个特征主要是用来区别低消品和高消品,这个特征的计算会有一点复杂,需要跟踪每一个产品和特定用户间的消费间隔或者二次购买率。
(3)购物者和商品关系
购买者和商品之间的关系特征是最难被衍生出来的,这个特征主要表示的是特定用户对特定产品的喜爱程度。如点击频率、收藏行为等
特征降维
1.如果输入的数据源是一个多字段的矩阵,特征降维就是挖掘出其中的关键字段,从而减少输入矩阵的维度。(特别是图像识别或者是文本分析领域)
2.特征降维的主要目的:
(1)确保变量间的相互独立性
(2)减少计算量
(3)去噪
3.数据挖掘领域中常用的降维方法包括以下几种:
(1)主成分分析;主成分分析是最常用的一种线性降维方法,PCA 通过线性映射投影的方法,把高维的数据映射到了低维的空间中。
(2)线性判别式分析;通俗的解释就是通过线性判别式分析处理后的数据,同类间距会非常小,不同类的间距会非常大。
(3)局部线性嵌入;简单理解就是通过 LLE 降维算法之后,原来高维度上相近的数据点在低维上依旧距离相近。
第5章 机器学习算法——常规算法
5.1 分类算法
定义:解决分类问题,如广告的投放和疾病预测;分类算法一般都是监督学习算法,需要通过已有的打标数据来生成分类模型。
KNN(K近邻)
1.KNN 是一种 Lazy Learning(也可称为“惰性学习”,可理解为考虑问题的最简化情况)模式的算法。即KNN 只考虑与目标的距离最近的K个点的集合中哪个类别的点数量最占优势。

2.K 值对预测对象的最终预测结果的影响是很大的。K 值取得太小可能会造成参与评估的样本集太小,结果没有说服力;K 值取得过大,会把距离目标队列距离过远的一些噪音数据也考虑进去,造成结果的不准确性。
3.KNN 的另外一个问题就是计算成本很高,因为每个预测点都需要对全量数据集进行一次距离的计算和排序,这样就会造成非常大的计算资源开销。
朴素贝叶斯
1.朴素贝叶斯模型(Naive Bayesian Model,NBM)作为以条件概率为基础的分类器,是一种监督学习算法,常被用于文本分类和垃圾邮件过滤等场景中。
2.贝叶斯定理主要是通过已知的正向概率求解逆向概率。
如果我们事先不知道袋子里有多少个黑球、多少个白球,我们摸一个球出来,通过所摸出球的颜色对袋子里的黑白球比例进行推测,这就是逆向概率问题。
3.贝叶斯理论在分类场景中解决的问题就是:当我们已知目标列和特征列各自分布的概率情况下,特征列概率已知,求解目标列每个值的概率。
4.举例:
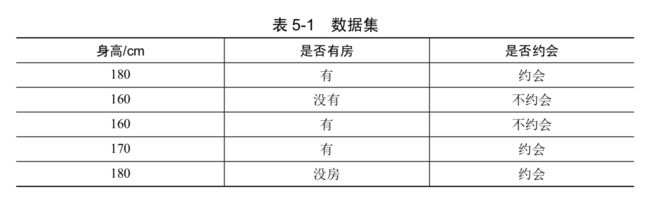
在这个数据集中,“身高”和“是否有房”是两个特征项,“是否约会”是目标列。我们希望通过贝叶斯算法,当已知一个男士的“身高”和“是否有房”这两个特征数据之后判断他约会成功的概率。
逻辑回归
1.逻辑回归(Logistic Regression,LR)是一种广义的线性回归分析模型,属于监督学习算法,最常用的是二分类问题。
2.LR作为机器学习算法中的“明星算法”,无论对大数据量的问题或是小数据量的问题都有很好的性能和计算结果,而且在参数设计上也比较利于调参。
3.在机器学习领域,有不少于一半的场景是通过逻辑回归算法来解决的,所以学会逻辑回归等于学会了机器学习的“半壁江山”。
4.举例:

支持向量机
1.支持向量机(Support Vector Machine,SVM)是一种有监督的分类算法,通过探求风险最小来提高学习机的泛化能力,实现经验风险和置信度范围的最小化。
2.详细解析:

这条用于分类的直线就叫作分类机。
在二分类的这条线上下,都有每个类别跟分类器间隔最近的一些点,这些点被标记出来。如果这些点的位置发生了变化,那么分类机的位置也相应地会发生变化,也就是说这些间隔点支持了分类机,这些间隔点就是“支持向量”。
即这个算法的组成和含义,就是支持向量和分类机。只要保证每一个类别的这些支持向量跟分类机的几何距离最大,就可以保证分类的准确度。
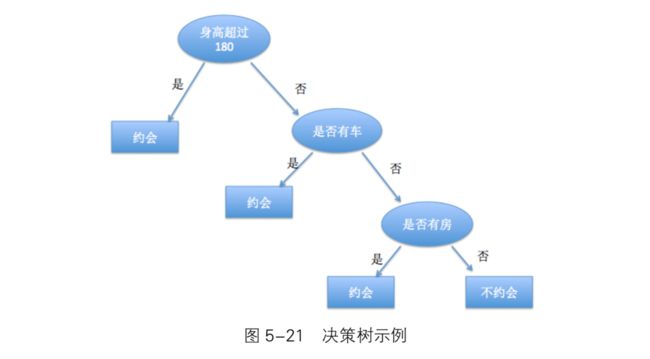
随机森林
1.随机森林(Random Forests,RF),一种由多个决策树组成的分类器,是一种监督学习算法。
随机森林由许多决策树组成,每个决策树都是一个弱分类器,最终的结果由这些弱分类器投票决定。
5.2 聚类算法
1.聚类算法就是将具有相似属性的一组数据归为一类。

2.聚类与分类的区别:
分类一般解决的是有监督学习的场景,往往是根据历史的经验数据或者是打标好的数据训练模型,然后通过这个模型对未知的数据进行预测。分类比较典型的场景是疾病的预测和天气预报等。
聚类解决的是无监督学习的场景,就是没有打标好的数据的场景,如在用户画像的时候,我们有一组数据表示的是用户的年龄、收入和兴趣等数据,这样就可以通过聚类算法把相似度高的用户分到同一个类别中。
3.聚类的算法很多,根据计算方式不同可以分为基于距离的聚类算法和基于密度的聚类算法。
基于距离:如果我们想把上面的这些点通过距离聚类的方式分为两类,需要找到两个簇,其中每个簇都有一个中心点,簇里的点到各自簇的中心点的距离都小于到其他簇的中心点的距离。
基于密度:密度聚类更多的考虑的是点和点之间的连接关系。如果有一连串的点是彼此相邻的,它们之间的密度就是相近的,我们就可以把这种点看成相同类别。
4.K-means 和 DBScan 是最常见的两种聚类算法,其中 K-means 是根据距离聚类,DBScan是根据密度聚类。
5.K-means 是一种无监督的,基于距离聚类的机器学习算法。
应用:例如在用户画像领域,通过人群的多维属性对人群的类别进行划分,在文本分析中对生成的词向量进行聚类可以挖掘出相似语义的词语。
缺陷:复杂度较高;噪音点不能及时被排查;需要预设聚类的数量,但聚类数是比较难以预先判断;需要设置初始质心位置,随机生成的初始质心对最终的结果构成一定影响
6.DBSCAN 是一款基于密度的聚类算法。


优势:相比于 K-means ,此算法会根据密度自动调整聚类的类数,针对这种按照密度区分明显的数据集,通常可以得到更合理的分类结果;相对 K-means,DBSCAN 的另一个优势是可以过滤噪音数据。
缺陷:处理高维数据性能较差;在处理一些数据分离不明显的数据集时,聚类效果较差;当数据有重叠时,会做合并操作;DBSCAN 的算法复杂度较高,大于K-means;
5.3 回归算法
1.分类与回归的区别:
分类和回归的区分为,通常如果预测变量是离散的,我们称其为分类,如果预测变量是连续的,则叫作回归。
回归算法其实就是拟合出贴近于实际数据点的曲线。

5.4 文本分析算法
分词算法——Hmm
1.分词算法就是将句子按照每个词的意义进行分割,对于中文来说,词与词在书写的过程中不具备天然的分隔符,所以需要对句子中的词进行拆分。
2.分词大致可以分为 3 种方法:机械分词、统计分词和机器学习分词。
(1)机械分词:设置一个涵盖所有词语的词库,将需要分词的文章从前向后遍历一遍。
(2)统计分词:在海量文本中找出同时出现频率很高的几个字,那么这几个字组成在一起很有可能就是一个词语。
(3)机器学习分词:这类分词基于人工标注的词性和统计特征对中文进行建模,实际的分词过程其实就变成了对结果的预测过程,通过计算每种分词可能性的概率大小来进行分词并且得到最终结果。比较常见的方法就是隐马尔科夫模型(Hidden Markov Model,HMM)和条件随机场(ConditionalRandom Field,CRF)算法
3.隐马尔科夫模型主要可以用来解决 3 种基本问题:评估问题(Forward-backward 算法)、解码问题(Viterbi 算法)和学习问题(Baum-Welch 算法)。
TF-IDF
1.词频-逆向文件频率(TF-IDF)是一种用于信息检索和数据挖掘的加权技术,即文本的打标。
2.文本打标就是找出最能代表这个文本意义的一些词语:一方面是打标词语要出现得足够多,即词频统计;另一方面,把多篇文章放在一起来比较,找出每篇文章中独特的词语;
LDA
1.隐含狄利克雷分布(LDA)是文本挖掘领域的主题模型。
LDA 是一种无监督的机器学习算法,通过大规模的语料数据训练,挖掘出其中潜在的一些主题,这些主题可以代表每篇文章的含义。
5.5 推荐类算法
1.根据推荐的维度不同把协同过滤分为两种:一种是基于人的推荐,叫 UCF(User-based Collaborative Filtering ), 另 一 种 是基于物品的推荐, 叫 ICF ( Item-based Collaborative Filtering)。
· UCF基于人的偏好进行推荐,从全量数据集中找出哪些人是有相同偏好的,针对人群之间的相似偏好性进行推荐。
· ICF 是基于物品的推荐,从物品的角度先找到相似度高的商品,然后进行推荐。
2. ICF和 UCF,算法的推导过程中的核心就是聚类,也就是计算向量距离。
5.6 关系图算法
1.关系图算法指输入的数据源是呈图状结构的,我们通过网图中不同对象之间的关系来进行数据挖掘。
2.关系图算法的核心是 Community,我们可以通过算法挖掘关系网络中的主要成分、预测行车轨迹的最短路径、判断社交网络中彼此的亲密程度、做金融行业的风险管控等。
3.关系图算法中运用较多的两个算法,分别是标签传播和迪杰斯特拉(Dijkstra)最短路径算法。
(1)标签传播算法是一种基于图数据的半监督方法。
举例:

金融风控的例子:如果我们已知 A 是欺诈用户,F 是信用很高的用户。通过标签传播算法可以将每个人的属性从 A 和 F 开始传播,直到计算出全图所有对象是欺诈用户的概率以及信用用户的概率,传播的方式也很简单,根据距离的远近(是否有连通)来判断。最终得到了每个人的欺诈指数。
当两点的距离越近,也就是传播距离越短,这两点的边权重越大;当两点的距离越远,边权重越小。这一点也比较容易理解,因为“近朱者赤,近墨者黑”,数据集合中每个点肯定是受到最邻近的点的影响较大。
(2)标签传播的中心思想是通过全网中部分打标数据,利用标签传播,挖掘出其他未打标数据的结果。在关系网状结构的数据挖掘中还有一个主要场景,就是最短路径的挖掘。
举例:可以利用最短路径算法计算两点间的最短线路,实现导航功能。
第6章 机器学习算法——深度学习
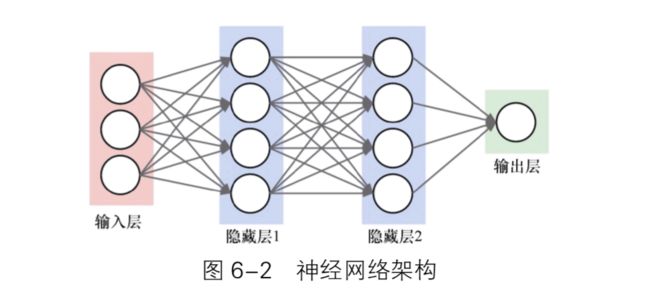
1.生物在识别某些个体的时候,大脑内部是做了层层抽象的,这些抽象就像通过神经元把每种事物拆分成颗粒,然后通过对这些颗粒的理解来做出一些反应。
这种抽象工作是通过神经元的逐层抽象来实现的,这就构成了神经网络的一个基础架构,深度学习也继承了这种架构。
2.深度学习与机器学习的关系
深度学习是机器学习的一种。
机器学习分类的话,除了分成监督学习、无监督学习、半监督学习和增强学习之外,从算法网络深度的角度来看还可以分成浅层学习算法和深度学习算法。
3.浅层学习并没有涉及多层次的不断抽象特征的过程,算法的架构相比于深度学习比较简单。
4.深度学习训练模型的过程是双向训练的,从输入到输出作为第一条链路,从输出到输入是第二条链路。
模型训练的逐层训练就是深度学习对特征不断抽象的过程。
5.深度学习和浅层学习另一个特别大的区别体现在对特征的处理上,在浅层学习当中,特征都是通过人的手工加工和提取生成的,对图形数据这种特征复杂的场景扩展性很差。深度学习可以通过算法自动构建特征,将特征映射到不同的维度空间中。
6.深度学习在特征非常复杂的场景下会有比较好的表现,如图像识别、语音识别和文本分析这样的场景。
7.深层学习与浅层学习的差别总结:
(1)目标场景;目前浅层学习还是机器学习的主流应用,主要用于解决一些日志类的数据分析,特别是结构化数值类数据的一些预测场景。深度学习主要解决复杂特征场景,如图像识别、文本分析和语音识别这样的场景。
(2)特征抽象;浅层学习主要是通过人工手动构建特征,需要具备大量的业务背景知识,而且依赖于手工的特征抽取方式的扩展性不会特别好。深度学习采用了自动编码的方式,逐层抽象特征,对复杂的特征抽取场景有比较好的效果。
(3)模型训练;浅层学习因为架构的层次较少,通过单层梯度下降的方法就可以有监督地对模型进行训练和优化。在深度学习中,往往要通过从前到后和从后到前两条链路来对模型进行训练和优化,而且在模型训练的过程中要考虑不同层次之间函数的偏导关系。
8.深度学习的常见结构
(1)深度神经网络(Deep Neural Network,DNN),泛指多层次的神经网络,这些模型的隐藏层之间彼此相连。
(2)卷积神经网络(Convolutional Neural Network,CNN),主要是通过卷积来解决空间上一些复杂特征的问题,如人脸识别、图像识别。
图片数据其实是一种空间上的相互联系,如猫的图像中鼻子边上可能是嘴,CNN 解决的是空间的问题。
(3)循环神经网络(Recurrent Neural Network,RNN)是一种环状的深度神经网络,常用来解决时序行为的问题,如机器翻译、文本分析、语音识别。
下一个时间产生的文本会受到前一时刻文本的影响,也就是说在时间维度上是彼此关联的,所以 RNN 的环状特点就会更好地解决这种时序空间的联系。
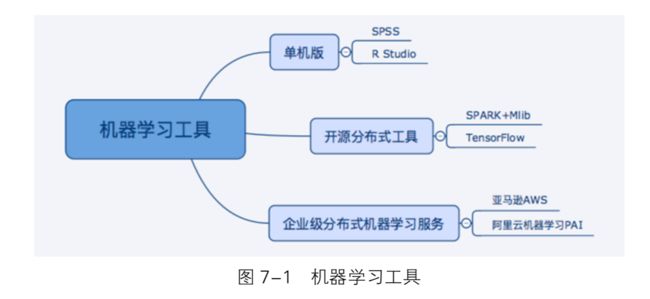
第7章 常见机器学习工具介绍
1.
第8章 业务解决方案
1.心脏病预测
(1)这是一个二分类的监督学习场景,可以选用逻辑回归和SVM等二分类算法
(2)数据为半结构化数据,需要做特征抽象
(3)因为数据都是打标数据,可以利用拆分数据集的方式对生成模型进行评估
2.商品推荐系统
(1)数据集适合于通过协同过滤算法做推荐。
(2)通过算法可以找到成交可能性高的商品对A和B
(3)当用户购买A时,推荐用户商品B
3.金融风控案例
(0)通过关系图算法挖掘人员关系网络中的彼此信用,实现一个金融风险控制的场景
(1)因为是部分数据打标的场景,希望通过部分打标数据对全量数据进行预测,这是一
个半监督学习算法
(2)数据为点边相连的关系图状数据,需要选择关系图算法
(3)基于以上两点选择标签传播算法
4.新闻文本分析
通过机器学习算法解决文本分析的两个常见场景:其一是将新闻文本进行自动打标,可以理解成提取文章中的关键字;另一个场景是新闻的自动分类,把新闻按照各自的类别(如女性、体育和军事等)自动分类
以上思路总结如下:
• 提取关键词,可以选用TF-IDF找出每篇文章中最有个性化的关键词。
• 对文章进行分类,选用 LDA 算法找出每篇文章的主题,并且通过主题代替文章,把主题向量化然后通过 K-means 算法来进行聚类,找出文章的最终分类。
5.农业发放贷款预测
业务场景:银行需要评估每一个借贷农户的还贷能力,然后才能决定发放贷款的金额。
• 根据历史标记数据学习并对贷款金额进行预测,监督学习场景,选择线性回归算法
• 数据为半结构化数据,需要进行特征抽象
• 根据预测的还贷金额和贷款申请金额对比,判断是否借贷
6.雾霾天气成因分析
• 训练数据是结构化数据,选用逻辑回归进行特征重要性的评估。
• pm10、so2、co、no2 作为特征列,pm2 作为目标列。给 pm2 设置一个阈值,构成正负打标样本,把实验划分为二分类的场景。
• 针对二分类场景,用户可以选择逻辑回归以及随机森林两个算法来比较效果。
7.图片识别
通过 Tensorflow 的第三方算法包 TFLearn 对 CIFAR-10 数据进行训练,并最终预测实现了图片识别场景。
第9章 知识图谱
1.人工智能的未来会建立在数据共享和数据互通的基础上。
(1)统一的数据标准;如果 10 家不同公司的数据存储成 10 种不同格式,那就意味着需要开发至少 10 种数据接口的算法,这样就造成了一套算法无法在一个行业里复用的情况。
(2)行业间连通;如果可以把各行各业的数据通过一个主键关联起来,以人为单位来看,就可以获得每一个人完整的用户画像,有了这样完整的用户画像之后就可以做很多个性化的推荐工作。
(3)数据流转的自动化;未来的数据知识图谱建模,这些数据流转的过程应该会实现完全的自动化。
2.知识图谱包括 3 个要素:实体、关系和属性。
实体是客观事物,关系和属性是事物间的连线。
3.知识图谱最核心的功能应该是推理。
推理并不是发现新知识,而是对图谱中隐藏关系的发现。
4.举例:
“王治郅是姚明的篮球队队友,王治郅个子高么?”
接下来就可以进行这样的推理,王治郅是姚明的篮球队队友,所以王治郅也是篮球运动员,篮球员动员具有个子高的属性,所以王治郅的个子也高。
对人类来讲,这只是简单的常识性问题,但是如果机器可以完成上述的推理过程,将大大推动人工智能的发展,这一切的根源来自于知识图谱。