文集名字已经改成《蜘蛛结网》了,那么这个专题下不限于课程学习的练习题,也有自己的练手和札记。
最近去爬了一个留学服务网站,主要汇集了美国私立中学的信息,学习爬虫不久,不过凭这门语言的经验和一些小技巧基本能搞定。
点击“院校”链接进入可以看到诸如所在州,城市,宗教等分类可供筛选。
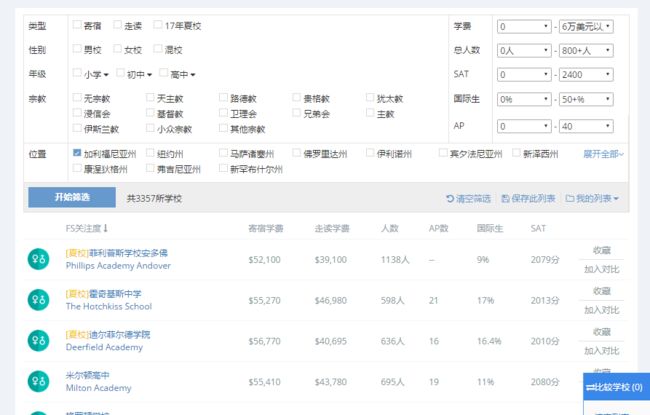
-------------------------------------Channel 入口----------------------------------------
爬取的思路就是按州的分类来爬取,从URL中可以发现美国各州的缩写包含在里面,那么就把所有州放入最初的state_list里面:
state_list = '''
MA
CT
... # 有省略,米国所有州缩写
'''
----------------------------------------Link列表的获取-----------------------------------
然后就在base_url的基础上编辑每个州所有学校所在页面的URL:
for page in range(1, page_num):
school_page = base_url + state + '&page=' + str(page)
这样就可以写一个get_school_link(state_list)函数获取所有州下全部学校的link("href"标签)。注意到页面有每页显示10条,20条,50条记录数等,这样也可以设定我们最初的URL,这个网站上的所有学校数目是可以看到的,因此也就知道每页50条记录的话,page的数目设为50就绰绰有余了。当然也可以通过最后一页无信息的特定标签来确定爬取页面到头了。
把所有学校的link插入MongoDB数据库中,后续调用爬取每个URL的页面,并且也可以作为断点续传时候总的集合:
school_list_total.insert_one({'school_link': school_link})
------------------------------------------单个页面的爬取------------------------------------
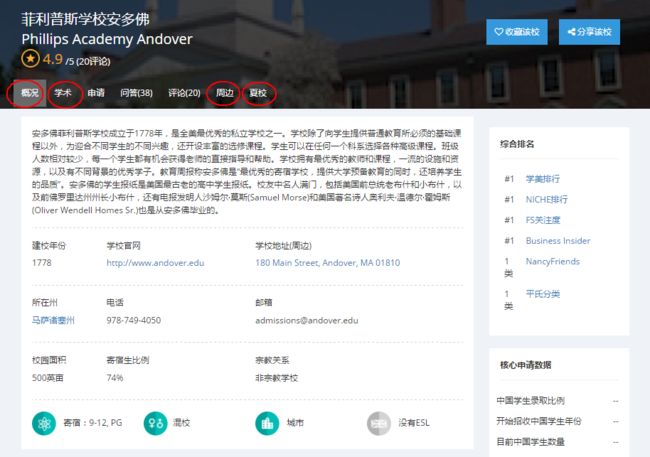
要获取的学校信息较多,分别在“概况”,“学术”,“周边”等link下,因此将每个link分别写了一个函数准备爬取的时候调用:
学校概况(base_info(url)):
将爬出的数据存入字典base_data中:
base_data = {
'学校名称': cn_name,
'英文名称': eg_name,
'学校介绍': introduction[0].get_text().strip(),
'学校类型': school_type,
'建校时间': build_time[0].get_text(),
... # 更多信息省略,strip()是一个很好用的方法,去除字符串之间的空格
'教师学历': tuition[6].get_text().strip() + '硕士以上',
'SAT分数': tuition[7].get_text().strip(),
}
当然为防止出错,也要用异常处理的(try-except),否则程序跑着可能因为IndexError,ConnectionError等等类似问题停下,可能是由于网页中对应的内容没有,如果没有我们就在except中将这个内容设为'N/A'。
其他相应的有AP_course(url),society_structure(url),uni_college_list(url), summer_school(url)等函数,分别存入字典course_data, society_info_data,society_info_data, uni_college_data, summer_school中,Python3.X里面字典的操作有合并更新一项,因此几个字典可以合并一起插入数据库中存储。
def get_info(school_link):
try:
data = {'school_link': school_link}
base_data = base_info(school_link) # 学校基本信息
data.update(base_data) # 将学校信息在data中更新
course_data = course_info(school_link + '/academia') # AP课程信息
data.update(course_data)
uni_college_data = uni_college_info(school_link + '/academia') # 升学信息
data.update(uni_college_data)
society_data = society_info(base_url + school_link.split('/')[-1] + '/area') # 社会信息
data.update(society_data)
summer_school_data = summer_school(base_url + school_link.split('/')[-1] + '/summerschool') # 夏校信息
data.update(summer_school_data)
get_info_1.insert_one(data) # 将学校信息插入数据库
print(school_link)
except (ConnectionError, ConnectionAbortedError):
pass
前面有所有学校的URL,这里我们爬取一所学校就存入一条完成的URL,如果中途服务器连接中断就可以提取未爬过URL(两者的差集)的断点续传:
db_urls = [item['school_link'] for item in school_list_total.find()]
index_urls = [item['school_link'] for item in get_info_1.find()]
x = set(db_urls)
y = set(index_urls)
rest_of_list = x-y
最后当然要用上proxy(最好有一个列表从里面随机取),headers,time.sleep()这些小技巧应对反爬,进程池可以提高爬取效率,这样就可以顺利获得想要的数据了。同时可以写个小程序统计所用的时间和爬取的数据数目,此处略去一万字。
-----------------------------------------把数据导出来-----------------------------------------
爬完之后数据是存储在MongoDB中的呀,如图所示:
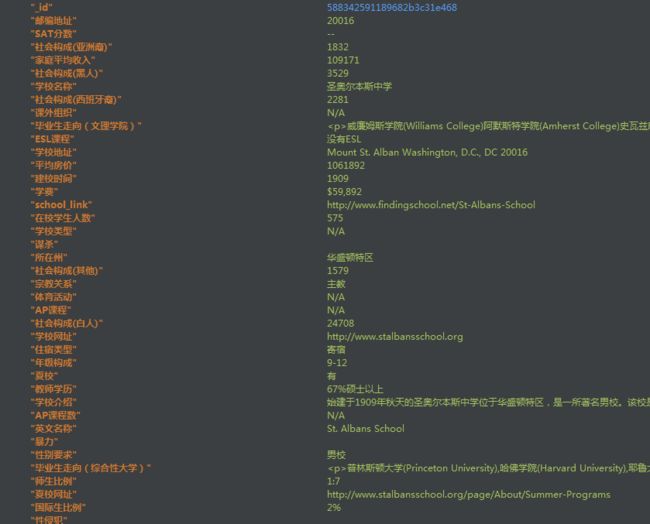
我们想要这些数据为我们后续所用(这里比如我想看到全部的数据啊),那就导出,导出成json格式和csv格式都非常方便。只是注意导出成csv的时候需要指定字段名称才能导出相应字段,而且打开后可能有乱码,可以先用notepad++打开再改为ANSI编码(csv编码格式),然后保存为csv就没有问题了。
----------------------------------最后的分割线--------------------------------------------------------
这次的对代码块的样式有了改进,前面有网友吐槽排版,这次终于找到正确的打开方式了,附上一篇上详细教程
http://www.jianshu.com/p/q81RER
小试牛刀,学无止境,不敢偷懒,后面还是会继续学习更新的。