摘要: 还在为搜索引擎的工作原理感到困惑吗?看完本篇就可以自己动手构建搜图服务了。
为什么是相似搜索?
一张图片胜过千言万语,甚至N行代码。网友们经常使用的一句留言是,no picture, you say nothing。随着生活节奏的加快,人们越来越没有耐心和时间去看大段的文字,更喜欢具有视觉冲击性的内容,比如,图片,视频等,因为其所含的内容更加生动直观。
许多产品是在外观上吸引到我们的目光,比如在浏览购物网站上的商品、寻找民宿上的房间租赁等,看起来怎么样往往是我们决定购买的重要因素。感知事物的方式能强有力预测出我们想要的东西是什么,因此,这对于评测而言是一个有价值的因素。
然而,让计算机以人类的方式理解图像已经成为计算机科学的挑战,且已持续一段时间了。自2012年以来,深度学习在图像分类或物体检测等感知任务中的效果慢慢开始超越或碾压经典方法,如直方梯度图(HOG)。导致这种转变的主要原因之一是,深度学习在足够大的数据集上训练时,能够自动地提取有意义的特征表示。

这就是为什么许多团队,比如Pinterest、StitchFix和Flickr 都开始使用深度学习来学习图像特征,并基于用户认为视觉上令人愉悦的内容提供推荐。同样,Insight的研究员也使用深度学习为应用程序建立模型,例如推荐购买太阳镜以及寻找艺术风格等。
目前,许多的推荐系统都是基于协同过滤(collaboratiove filtering):利用用户关联来提出建议(即,假设喜欢你喜欢的东西的用户也会喜欢”)。但是,这些基于协同过滤的模型需要大量数据,其效果才能准确,并且难以处理尚未被任何人查看过的新内容。如果将内容表示应用于基于内容的推荐系统中,那么该系统不会遇到上述问题。
此外,这些表示还允许消费者高效地搜索照片库,以寻找到与他们刚刚拍摄的自拍(通过图像查询)相似的图像,或者用于特定物品(通过文本查询)的照片,这方面的常见示例包括关键字搜图以及以图搜图功能。
根据我们多年语义理解项目的技术经验,希望编写一个教程,介绍如何构建自己的特征表示,包括图像和文本数据,以及如何有效地进行相似性搜索。希望看完本文,读者能够对任意大小的数据无论数据集的大小如何,都能够从头开始构建出一个快速语义搜索模型。
计划
聊聊优化
在机器学习中,就像在软件工程中一样,有很多方法可以解决同一个问题,但每种方法都有不同的权衡及侧重点。如果是正在进行研究或本地原型设计,就可以摆脱效率非常低的解决方案。但是,如果是要构建一个需要可维护和可扩展的图像相似性搜索引擎,则必须考虑如何适应数据演变以及模型运行的速度。
下面让我们思考一些方法:

在方法1中,我们构建了一个端到端模型,该模型在所有的图像上进行训练,将图像作为输入,并输出所有图像的相似度得分。预测过程耗时很短(一次前向传播过程即可),但是,当每次添加新图像时,我们都需要重新训练得到一个新模型。此外,当类别多的时候,也会很难正确地优化它。这种方法虽然看起来很简单且预测过程很快,但是不能够扩展到大型的数据集。此外,我们还必须手动标记数据集与图像的相似性,这个过程可能非常耗时。
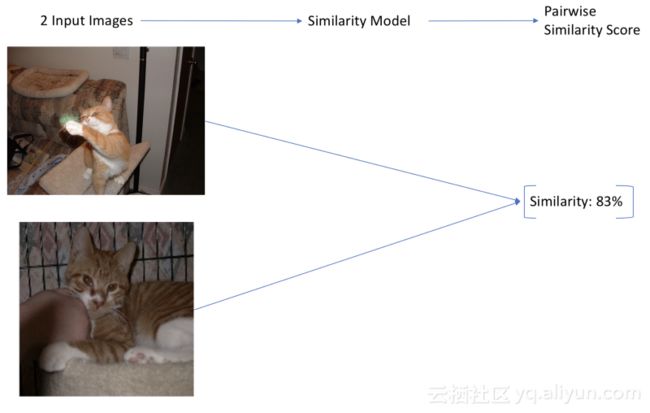
在方法2中,构建一个接收两个图像的模型,并输出0到1之间的成对相似得分(例如,孪生网络Siamese Networks)。这些模型对于大型数据集是准确的,但会另外导致一个可伸缩性问题。我们通常希望通过查看大量图像来查找相似的图像,因此我们必须为数据集中的每个图像对都运行一次相似度模型。如果模型采用的是CNN网络,并且有十几个图像时,那么这个过程就非常慢了。此外,这个方法仅适用于图像相似性搜索,而不适用于文本搜索。虽然此方法可扩展到大型数据集,但运行速度很慢。

方法3是一种更简单的方法,类似于字嵌入。如果找到一个富有表现力的矢量表示或嵌入图像,就可以通过观察矢量彼此之间的距离来计算相似性。这种类型的搜索是深入研究的常见问题,许多库都实现了快速解决方案(本文使用Annoy)。此外,提前计算出数据库中所有图像的矢量,这种方法既快速(一次正向传递就是一种有效的相似性搜索),又可以进行扩展。最后,如果我们设法为图像和单词找到常见的嵌入,就可以使用它们来进行文本到图像的搜索!由于其简单性和高效性,第三种方法作为本文的实现方法。
如何做到?
那么,如何实际使用深度学习表示来创建搜索引擎呢?我们的最终目标是拥有一个搜索引擎,可以接收图像并输出相似的图像或标签,还能接收文本并输出类似的单词或图像。为了实现这一目标,将经历三个连续的步骤:
1、根据输入图像搜索类似图像(图像→图像)
2、根据输入词搜索类似的单词(文本→文本)
3、为图像生成标签,并使用文本搜索图像(图像↔文本)
为此,将使用嵌入、图像和文本的矢量表示。一旦有了嵌入,搜索过程就转变为只需找到靠近输入矢量的矢量。我们采用的方法是计算图像嵌入和其他图像嵌入之间的余弦相似度。类似的图像将具有类似的嵌入,意味着嵌入之间具有高余弦相似性。
下面从数据集开始实验。
数据集
图像
图像数据集由1000张图像组成,分为20个类别,每类图像包含50个图像。该数据集可在此处找到,此数据集包含每个图像的类别和一组说明。为了使这个问题的难度更高,并且为了表明本方法的概括性,本文只使用了类别,而忽略说明。总共有20个类别,如下所示:
aeroplane bicycle bird boat bottle bus car cat chair cow dining_table dog horse motorbike person potted_plant sheep sofa train tv_monitor
从上图中可以看到,标签非常嘈杂:许多图像都包含多个类别,图像的标签并不总是来自最突出的内容。例如,在右下方,图像被标记为chair(椅子)而不是person(人),而该图的中心是有3个人,且几乎看不见椅子。
文本
此外,加载已在Wikipedia上预训练的单词嵌入(本文使用GloVe模型中的单词嵌入),使用这些向量将文本合并到语义搜索中。
图像-->图像
现在要加载一个在大型数据集(Imagenet)上预先训练过的模型,并且可以在线免费获取。本文使用VGG16网络为图像生成嵌入,注意,这里本文采用的方法适用于任何最新的CNN架构(不局限于VGG16)。
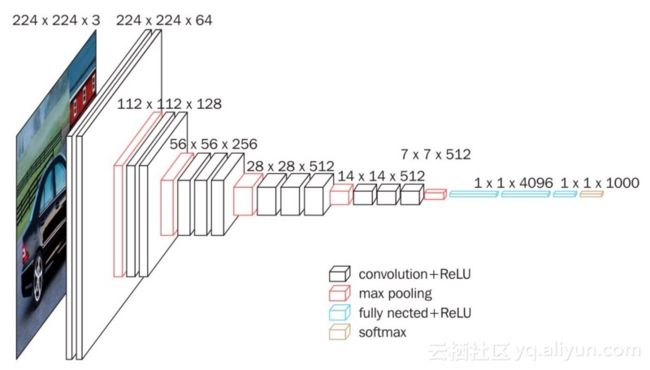
生成嵌入是什么意思?我们将使用预先训练模型倒数第二层前的网络结构,并存储对应的权重值。在下图中,用绿色突出显示表示嵌入层,该嵌入层位于最终分类层之前。

一旦使用该模型生成图像特征,就可以将其存储到磁盘中,重新使用时无需再次进行推理!这也是嵌入在实际应用中如此受欢迎的原因之一,因为可以大幅提升效率。除了将它们存储到磁盘之外,还将使用Annoy构建嵌入的快速索引,这将允许我们非常快速地找到任何给定嵌入的最近嵌入。
以下是本文得到的嵌入。现在每个图像都由一个大小为4096的稀疏向量表示。注意:向量稀疏的原因是在激活函数之后将负数归零。

使用嵌入来搜索图像
现在可以简单地接收图像,获得其嵌入后,并查看快速索引以查找类似的嵌入,从而找到类似的图像。这是特别有用的,因为图像标签通常很嘈杂,且图像比标签更多。例如,在数据集中,有一个类别cat(猫)和一个类别bottle(瓶子)。您认为下面这张图片会被标记为哪个类别?

正确的答案是瓶子,这是一个经常在真实数据集中出现的实际问题。将图像标记为唯一类别是非常受限的,这就是为什么希望使用更细粒的表示。幸运的是,这也正是深度学习所擅长的!下面看看使用嵌入的图像搜索是否比通过人为标记的更好。
搜索相似的图片todataset / bottle / 2008_000112.jpg,可以看见该图像位于bottle(瓶子)类别。
结果出人意料的好,搜索得到很多猫的图像,而不是瓶子的图像,这看起来很合理!由于预训练网络的训练集中包含各类图像,这样包括猫,因此它能够准确地找到相似的图像,即使它之前从未接受过本文选定数据集的训练。
但是,最下面一行中间的一幅图像显示了一个瓶架。一般而言,这种方法执行后找到类似的图像,但有时我们只对图像的一部分感兴趣。
例如,给定一张包含猫和瓶子的图像,我们可能只对和猫类似的图像感兴趣,而不是瓶子。
本文作者:【方向】
阅读原文
本文为云栖社区原创内容,未经允许不得转载。