Incorporating Copying Mechanism in Sequence-to-Sequence Learning
作者来自香港大学和诺亚方舟实验室
Motivation
本文的模型通过借鉴人类死记硬背的模式,提出了CopyNet的模型机制。在很多谈话或者文章中,回答或者摘要的时候需要大量的copy源句子,那么如何copy?从什么地方开始copy?本文模型给出了一种解决方法。

Model
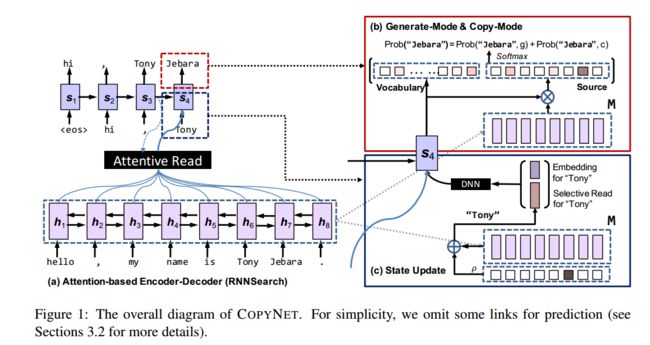
首先,该模型还是一个encoder-decoder的框架,基于attentive-based 的端到端的模型。
encoder
普通的双向RNN,生成的隐状态{h1,h2, ... , hn}表示为M.
decoder
decodr部分相对复杂,在这里decoder有两个模式,1.生成模式。2. copy模式。对于对话或者摘要,一如果完全copy源端,那么生成的回复肯定比较生硬,而且表达方面会欠缺很多东西。而端到端的生成模型,则可以生成一些符合语法并且geneal的回复,对于OOV的问题,不能很好的解决。那么将两者进行组合,可以很好的克服彼此的弊端。
另外,对于从哪开始copy的问题,作者将位置信息加入到了M中,然后通过类似注意力机制的方法去“注意”复制哪些信息,并将这种模式称做selective read。再加上attention-based 的decoder 的atentive read,这两种机制的 hybrid coordination 使得copynet的效果很不错。
词表:
对于decoder,作者并没有向传统的decoder那样用softmax求概率,在这里作者用了两个词表X,V. V 表示频率大的topK的词,和一般选取的词表方法一样。而X则表示,所有在源端出现一次的词,X和V有交集,如下图。
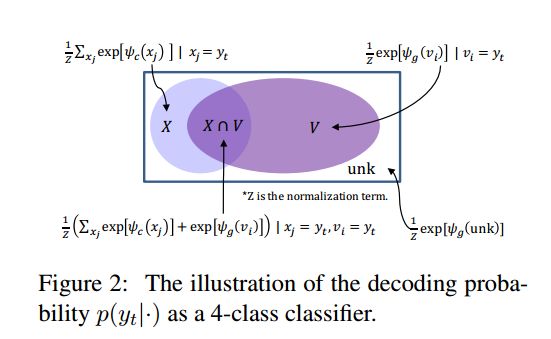
概率的计算公式:

其中

生成模式,用的线性映射,copy模式,用的非线性模式,并且作者表示tanh激励函数比其他函数要好。
到这,这里讲的都是上图Figure1里的红色方框里的东西,对于蓝色方框,作者对传统的decoder的输入进行了改进。除了输入st-1,和yt-1,ct ,作者将yt-1进行改进,除了自身的embedding外,还加入了类似attention的机制,对M进行加权求和,并且与yt-1的向量合并,共同作为输入,这样包含在M中的位置信息,以加权和的方式进入decoder,对于copy机制选择从哪里开始copy有很大的帮助。

这个机制就是selective read。
Experiments
作者分别在三个数据集(简单模式,摘要,对话)三个方面进行实验。实验结果都很惊艳。