论文笔记:Incorporating Copying Mechanism in Sequence-to-Sequence Learning-copynet
主要用途:
- certain segments in the input sequence are selectively replicated in the output sequence.
- COPYNET can nicely integrate the regular way of word generation in the decoder with the new copy-ing mechanism which can choose sub-sequences in the input sequence and put them at proper places in the output se-quence.
- 即:可以有选择性的从源端复制句子到合适的目标端。
3.copynet
3.1. model overreview
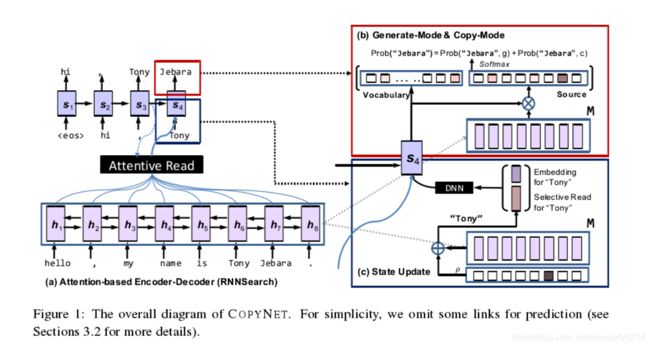
网络架构图
Encoder:
- 和别的encoder一样。
Decoder端:
read M and predict the target sequence,和之前的decoder有以下几点不同:
- Prediction:COPYNET基于两种混合模式的概率模型来预测单词。包括生成模式和copy模式,copy模式是直接从源端pick单词到目标端。
- State_update:t-1时刻的单词被用来更新t时刻的状态,但是copynet不仅用t-1时刻单词的word_embedding,也用t-1时刻的单词在M中隐藏层状态的具体位置有关。
- Reading M:除了attentive read to M,Copynet 也用selective read to M,这就使它成为一个强大的混合体,既考虑到了内容,也考虑到了位置。
3.2 Prediction with Copying and Generation
词汇表:V = {v1, ..., vN},所有的OOV词用unk代替,
all the unique words in source sequence X ={x1, ..., xTS}.
M:隐藏层状态
因为X当中包含一些词汇表中没有的单词,所以使用copy机制,可以输出部分OOV单词。
在这种情况下,源端词汇表就是 vocabulary for source X is V ∪ UNK ∪ X

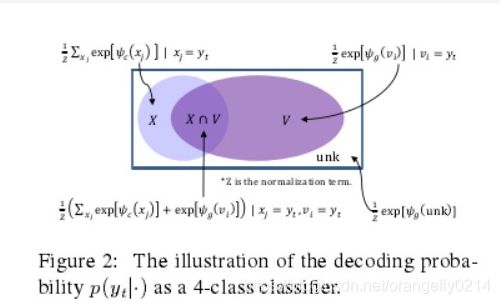
ψg(·) and ψc(·) 分别是生成模式和copy模式下的score function。
生成模式下:

copy模式下:

发现用tanh非线性激活函数比linear transformation的效果更好,所以用它来做以下实验:
我们用隐藏层状态{h1, ..., hTS} 来表示源端序列 {x1, ..., xTS} 中 的每一个单词,因为双向RNN的encodes不仅包含内容,而且把位置信息也encodes进了hidden states M中,这个位置信息对copy机制来说非常重要。
在上面的⑥式当中,我们将所有的xj=yt的概率做了加和,这是因为考虑到了会有很多源端symbols都可以decoding yt。
p(yt,c|·)=0,如果yt没有出现源端句子中。
p(yt, g|·) = 0 当yt只出现于源端句子当中时
3.3 state update
copynet根据前一时刻的隐层状态st-1,前一时刻的symbol yt-1,以及context vector Ct,来更新t时刻的隐层状态st,在copy machanism中,yt-1——st会有一些改变



3.4 Hybrid Addressing of M
copynet通过将基于内容和基于位置信息的策略结合起来的混合状态来获得隐层M的内容,单词的语义和它在X中的位置信息都会通过encoder RNN encode进隐藏层状态M,
copynet的注意力机制更多的是由语义和语言模型驱动,因此即使是很长的距离,也可以更加自由的在隐藏层状态M中游荡。另外,一旦copynet进入copy机制,选择读取M时也由位置信息决定。因此,the selective read often takes rigid move and tends to cover consecutive words,including UNKs.
- location based addressing
- Hadling Out-Of-Vocabulary word
尽管很难直接验证上述具体的addressing stategy,但是我们的经验学习表明一个更显著的现象一个训练得当的copynet可以copy一个相当长的充满OOV的句子,尽管这个句子的隐层状态表示M缺乏语义信息。这就提供了一个很自然的方法:扩展有效的词汇来包含远端的所有单词,尽管这个改变很小,但是却在很大程度上减轻了OOV问题
4.learning
copynet可以通过end-to-end fashion用bp算法进行优化。

5.实验
文章分别在合成数据集,文本摘要,单轮对话中做了实验验证了copynet的强大。
我自己是因为要处理机器翻译的未登录词来学习这篇文章,copynet可以在一定程度上解决部分未登录词,但是并不能解决所有的未登录词问题,而且我觉得对于文本摘要这种需要从文章中提取关键词的任务好像更适合用copynet,因为文本摘要中的提取出来的命名实体识别的词更多一些。
文章仅用于学习记录,方便自己日后查看,如有问题请大神们指出,非喜勿喷!