
原文链接:https://arxiv.org/abs/1603.06393
Motivation
传统的Seq2seq模型存在OOV(Out Of Vocabulary)问题,即对于超出词表的词难以预测。实际上,这种问题可以通过直接从输入复制单词来解决。例如如下的对话问题中,姓名、原句都可以直接复制。

作者提出Copynet,通过选择生成模式和拷贝模式,使得模型在必要时可以直接从输入中复制单词作为输出。
Model
模型如图所示。左下方的encoder和传统seq2seq模型一致,将输入进行编码。左上方的decoder进行解码,包括答案预测、状态更新两部分。
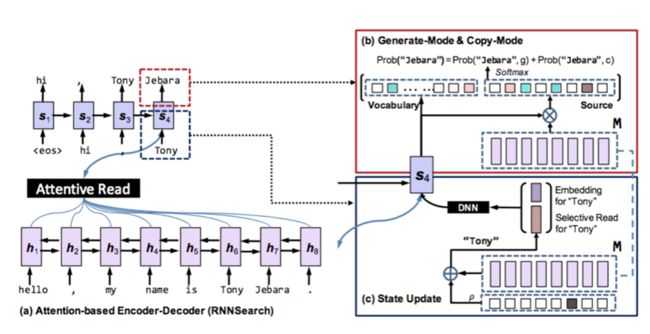
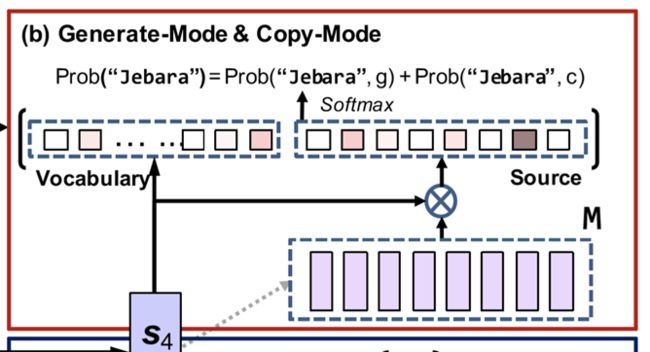
答案预测
答案来源包括词表和输入两个部分。答案预测模式分为复制模式(copy mode)和生成模式(generate mode)。复制模式即使用指针网络从输入中选择答案,生成模式类似传统RNN,从词表中选择答案。
预测一个词yt的概率p可以分解为以生成模式预测yt的概率和以复制模式生成yt的概率的和。
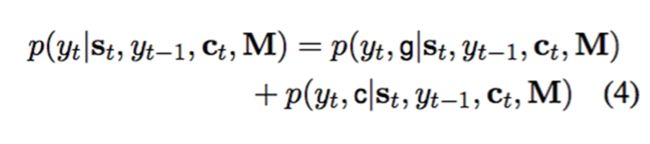
两种模式的选择由以下方式确定。
生成模式:
1)对于词表中的词语,pg为eφg(yt)/Z
2)对于在输入而不在词表中的词语,pg为0,即不从词表预测
3)对于既不在输入也不在词表的词语,pg为eφg(UNK)/Z
复制模式:
1)对于在输入的词语,pg为Σxj=yteφc(xi)/Z,即计算所有和该词相同的输入的分值总和
2)对于不在输入的词语,pg为0,即不从输入预测
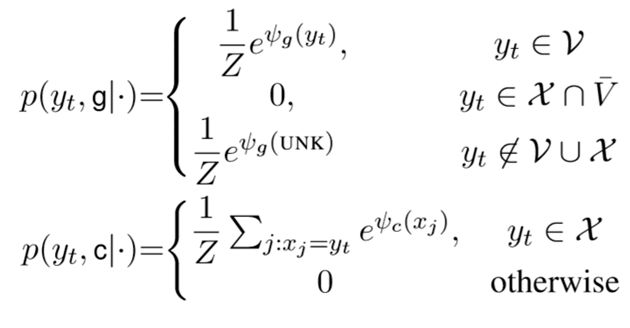
在上式中,归一化项Z由如下方式给定(即两种答案来源的所有词的分值总和)
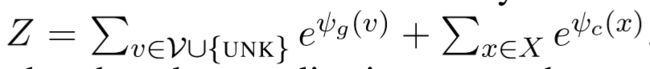
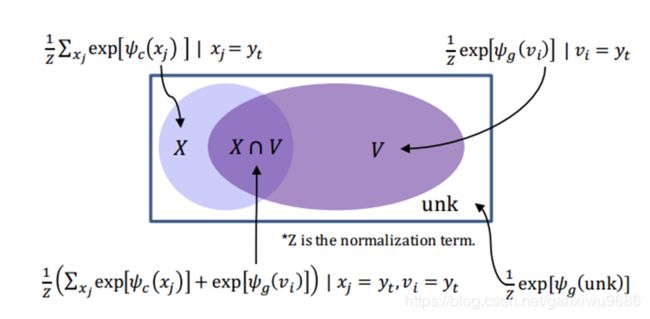
下图更加直观地说明了不同来源答案的预测方式,即对于词表和输入的交集采用两种模式,若仅在一个来源则采用一种模式,两种来源都不包含则使用UNK词语进行预测。
生成模式的打分函数由下式给定,即词语的one-hot向量×参数矩阵×该步的状态向量。
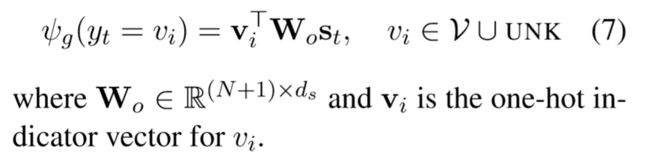
复制模式的打分函数如下,即将encoder隐态×参数矩阵经过激活函数后乘以该步的状态向量。
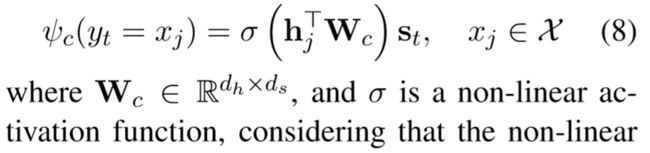
状态更新
状态st更新时使用上一步的输出值yt-1,用如下方式表征,其中e(y-1)为yt-1的embedding,ζ为一种加权平均。
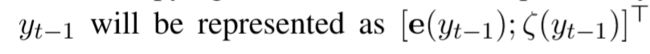
ζ由下式计算(类似Attention),即使用每一步的复制模式概率(经过归一化)作为权重,对所有隐态进行加权平均。
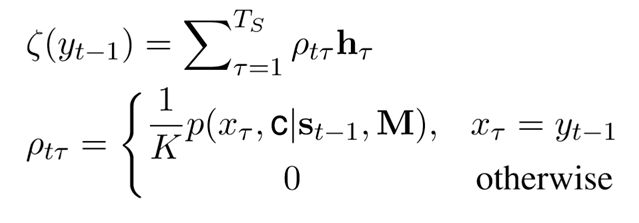
ζ与st、yt的更新关系如下所示。
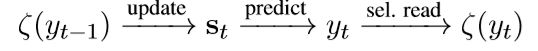
目标函数
Loss由下式计算,即对于batch中的每一组(x,y)和每一个时间步,将该步预测正确(基于输入和此前输出)的条件概率对数求和,整体取负值方便梯度下降最小化。
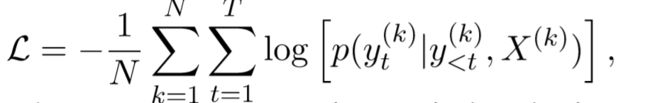
Results
对于对话问题,模型输出如下,可以看出答案中有很多词语是从输入直接复制的。

文本总结问题模型输出如下。
