写在之前的话
这是第一次翻译英文博客文章,连文档/论文都算不上,真的很困难=.=… 以及Google翻译真的很厉害,整个文章丢进去,对照原文还是能看懂的…
原文在这里,作者McCormick, C.,所有图片均来自于原博主。
Word2Vec Tutorial - The Skip-Gram Model
这篇教程是关于Word2Vec的skip gram神经网络结构的。我的写这篇教程的初衷是想跳过关于Word2Vec常规的介绍和抽象的见解,并深入更多的细节。具体来说我正深入探索skip gram神经网络模型。
The Model
skip-gram神经网络模型最基本的形式实际上惊人的简单。我们从微调和强化开始解释这个模型。
我们从高层次的见解(宏观?)开始。Word2Vec使用了一个你可能在其他机器学习见过的技巧。我们将训练一个简单的带有一个隐藏层(hidden-layer)的神经网络来完成某个任务,但是我们实际上没有将这个神经网络用于我们的任务。我们的目标实际上只是为了学习隐藏层的权重(weights),我们会看到这些权重实际上就是我们尝试学习的“词向量(word vector)”。
另外一个你可能见过这个技巧的地方是在非监督特征学习——训练一个自动编码器(auto-encoder)在隐藏层压缩输入向量,然后在输出层(output layer)解压缩回原来的样子。训练完之后,我们会去掉输出层(解压缩的步骤),只使用隐藏层。这是一个学习图片特征而不标记训练数据(图片)的技巧。
The Fake Task
所以我们现在需要讲一下这个要用来建立神经网络的“假”任务("fake" task),然后我们再回来看看这是如何间接地给到我们以后要用到的词向量的。
我们将要训练神经网络来做以下的事情。给定一个在句子中间部分出现的特定单词(就是神经网络的输入,the input word),在这个单词临近(nearby)的单词中随机选一个(a nearby word)。这个神经网络将要告诉我们每一个在词汇表(vocabulary)中的单词成为这个nearby word的概率。
我们说的“临近(nearby)”,实际上是这个算法的一个参数,叫窗口大小(window size)。一个常见的窗口大小可能是5,意思是特定单词的前后各5各单词(总共10个)。
神经网络输出的概率将关联每个词汇表中的单词临近我们输入的单词的概率。比如说,如果你给训练完的网络输入单词"Soviet",输出的概率中,"Union"和"Russia"的值要比不相关的单词如"watermelon"和"kangaroo"要高得多。
我们将通过提供训练文本中找到的单词对(word pairs)来训练神经网络。下面的是一些我们从句子"The quick bron fox jumps over the lazy doe."中取出的训练样本(training samples)的例子(word pairs),在这个例子中,我使用了一个较小的窗口大小的值:2,蓝色高亮的是我们输入的单词。
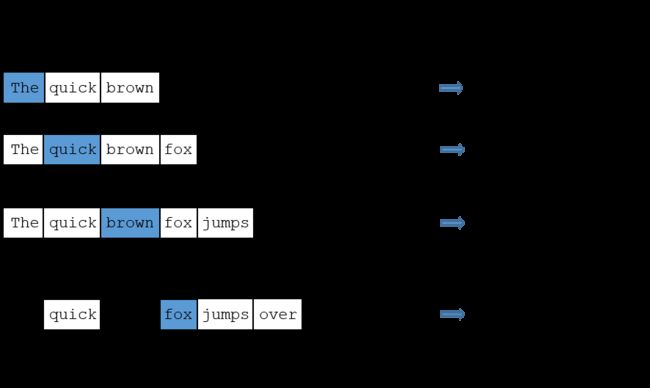
这个网络将要从每一个组合出现的次数来学习统计。因此,比如,相比("Soviet", "Sasquatch"),网络会得到更多的("Soviet", "Union")训练样本,如果你输入单词"Soviet"作为网络的输入,那么网络输出"Union"或者"Russia"的概率值会比
"Sasquatch"更高。
Model Details
那么这是如何表示的呢?
首先,我们知道不能直接把单词用字符串的形式输入到神经网络中,所以我们需要找到一个在给网络“表达”单词的方法。为了实现这一点,我们首先从训练文本中创建一个词汇表(vocabulary),假设我们这个词汇表中有10000个不同的单词。
我们要把单词比如"ants"表达成一个独热向量(one-hot vector)。这个向量有10000个元素,每个分别表示词汇表中的一个单词,我们把单词"ants"在向量中对应的位置的值设为"1",其余的设为"0"。
网络的输出是一个同样有10000个元素的向量,每个都是对应一个概率值,指随机选择一个这个输入单词"ants"的临近单词(nearby word)就是这个元素对应的单词的概率。
这是这个神经网络的结构。

这里在隐藏层神经元中使用没有激活函数,但是在输出层中使用了softmax激活,我们后面再来说这个。
使用单词对训练这个神经网络的时候,输入和输出都是one-hot vector,但是当拿一个单词来验证这个训练完的网络时,输出实际上是一个概率分布(即一堆浮点数,而不是独热向量)
The Hidden Layer
对于这个例子,我们可以说我们在学习有300个特征的词向量。所以隐藏层将由一个有10000行(每行指词汇表中的一次单词)和300列(300个隐藏层神经元)的权重矩阵(weights matrix)来表示。
300个特征值这个“300”的数字,是Google曾经用来在Google news数据集上训练后发布的模型的特征值数量。特征的数量是一个根据你的应用调整的超参数(hyper parameter)(就是说尝试不同的值,看看哪个会得到最好的结果)
如果你看这个权重矩阵的行,实际上就是我们的词向量!

所以,所有这些的最终目标其实就是学习这个隐藏层中的权重矩阵——当我们完成后,我们会扔掉输出层(output layer)!
但是,让我们回来看看我们要训练的模型的定义。
现在,你可能会问你自己——“那个独热向量几乎是全0的,有什么用呢?”当你拿一个110000的独热向量乘以一个10000300的矩阵的时候,它会非常有效率地只选择在矩阵中对应行是1的来计算。下面是一个小例子:

这意味着这个模型中的隐藏层只是相当于查表操作,隐藏层的输出只是输入单词的词向量。(This means that the hidden layer of this model is really just operating as a lookup table. The output of the hidden layer is just the “word vector” for the input word.)
The Output Layer
单词"ants"的1*300的词向量会被送到输出层。输出层是一个softmax回归分类器(softmax regression classifier)。这里有一个关于softmax回归的深入教程,但这里的要点是,每一个输出神经元(代表词汇表中的每个单词)会产生0和1之间的输出,这些输出的值加起来等于1。
每个输出层的神经元有一个权重向量,它与隐藏层中的词向量相乘,然后把得到的结果应用到函数exp(x)中。最后,为了让输出值加起来等于1,我们除以所有10000个输出的值的和。
下面是计算单词"car"的输出神经元的输出的图:

要注意,神经网络不知道任何输出单词对于输入单词的offset。在输入单词之前和之后的单词之前它没有学到一组不同的概率(It does not learn a different set of probabilities for the word before the input versus the word after)。为了理解这个含义,假设在我们的训练语料库中,每一个"York"都出现在"New"之前。这意味着,至少在训练数据中,"New"有100%的可能出现在"York"附近。然而,如果我们在"York"附近的10个单词中随机取一个,是"New"的可能性不是100%;你可能选择了附近的其它的一个词。
Intuition
ok,下面要深入了解这个网络一个令人兴奋的点。
如果两个不同的单词有相似的“上下文(contexts)”(也就是说,他们附近可能出现的单词相似),那么我们的模型需要为这两个单词提供输出相似的结果。让网络输出相似的上下文预测的一种情况是,词向量是相似的(原文直译会很奇怪…)。所以,如果两个单词有相似的上下文,那么我们的网络就有动机去学习这两个单词的词向量!嘿嘿!
两个单词有相似的上下文是什么意思呢?你可以认为像"intelligent"和"smart"这样的同义词会有非常相似的上下文。或者有关联的单词,比如"engine"和"transmission"也很有可能有相似的上下文。
这网络也能帮你处理词干提取(stemming)的任务——网络可能会从单词"ant"和"ants"学习到相似的词向量,因为他们有相似的上下文(语境)。
Next Up
你可能留意到skip-gram神经网络包含大量的weights…就我刚刚的例子而言,有300个特征和10000个单词的词汇表,那么在隐藏层和输出层中分别有3,000,000个weights!在一个大数据集上训练这个网络会非常困难,所以word2vec的作者介绍了一些微调的方法来让训练变得可行。这些在part 2 of this tutorial里面会有介绍。
Other Resources
I've also created a post with links to and descriptions of other word2vec tutorials, papers, and implementations.
Cite
McCormick, C.(2016, April 19). Word2Vec Tutorial - The Skip-Gram Model. Retrieved from http://www.mccormickml.com