在2016WWDC大会上,Apple公司介绍了一个很好的语音识别的API,那就是Speech
framework。事实上,这个Speech
Kit就是Siri用来做语音识别的框架。如今已经有一些可用的语音识别框架,但是它们要么太贵要么不好。在今天的教程里面,我会教你怎样创建一个使用Speech
Kit来进行语音转文字的类似Siri的app。
设计App UI
前提:你需要Xcode 8 beta版本和一个运行iOS 10 beta系统版本的iOS 设备。
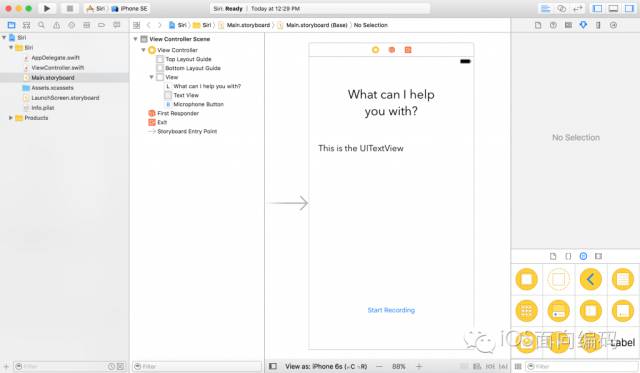
先从创建一个新的命名为SpeechToTextDemo的单视图工程开始。接下来,到 Main.storyboard 中添加一个 UILabel,一个 UITextView, 和一个 UIButton,你的storyboard应该看起来如下图:
接下来在
ViewController.swift文件中为UITextView 和UIButton
定义outlet变量。在这个demo当中,我设置UITextView
的名称为“textView”,UIButton的名称为“microphoneButton”。然后创建一个当microphone按钮被点击时会触发的空的按钮执行方法。
@IBAction func microphoneTapped(_ sender: AnyObject) {
}
如果你不想从创建最原始工程开始,你可以在在这里下载原始工程 然后继续下面的教学指导。
使用Speech Framework
为了能使用Speech
framework, 你必须首先导入它然后遵循 SFSpeechRecognizerDelegate 协议。因此让我们导入这个框架,然后在
ViewController 文件中加上它的协议。现在你的 ViewController.swift 文件应该如下图所示:
import UIKit
import Speech
class ViewController: UIViewController, SFSpeechRecognizerDelegate {
@IBOutlet weak var textView: UITextView!
@IBOutlet weak var microphoneButton: UIButton!
override func viewDidLoad() {
super.viewDidLoad()
}
@IBAction func microphoneTapped(_ sender: AnyObject) {
}
}
用户授权
在使用speech framework做语音识别之前,你必须首先得到用户的允许,因为不仅仅只有本地的ios设备会进行识别,苹果的服务器也会识别。所有的语音数据都会被传递到苹果的后台进行处理。因此,获取用户授权是强制必须的。
让我们在 viewDidLoad 方法里授权语音识别。用户必须允许app使用话筒和语音识别。首先,声明一个speechRecognizer变量:
private let speechRecognizer = SFSpeechRecognizer(locale: Locale.init(identifier: "en-US")) //1
然后如下图更新 viewDidLoad 方法:
override func viewDidLoad() {
super.viewDidLoad()
microphoneButton.isEnabled = false //2
speechRecognizer.delegate = self //3
SFSpeechRecognizer.requestAuthorization {
(authStatus) in //4
var isButtonEnabled = false
switch authStatus { //5
case .authorized:
isButtonEnabled = true
case .denied:
isButtonEnabled = false
print("User denied access to speech recognition")
case .restricted:
isButtonEnabled = false
print("Speech recognition restricted on this device")
case .notDetermined:
isButtonEnabled = false
print("Speech recognition not yet authorized")
}
OperationQueue.main.addOperation() {
self.microphoneButton.isEnabled = isButtonEnabled
}
}
}
首先,我们创建一个带有标识符en-US 的 SFSpeechRecognizer实例,这样语音识别API就能知道用户说的是哪一种语言。这个实例就是处理语音识别的对象。
我们默认让microphone按钮失效直到语音识别功能被激活。
接下来,把语音识别的代理设置为 self 也就是我们的ViewController.
之后,我们必须通过调用SFSpeechRecognizer.requestAuthorization方法来请求语音识别的授权。
最后,检查验证的状态。如果被授权了,让microphone按钮有效。如果没有,打印错误信息然后让microphone按钮失效。
现在如果你认为app跑起来之后你会看到一个授权弹出窗口,那你就错了。如果运行,app会崩溃。好吧,既然知道结果为什么还要问呢?(别打我),看看下面解决方法。
提供授权消息
苹果要求app里所有的授权都要一个自定义的信息。例如语音授权,我们必须请求2个授权:
麦克风使用权。
语音识别。
为了自定义信息,你必须在info.plist 配置文件里提供这些自定义消息。
让我们打开 info.plist配置文件的源代码。首先,右键点击 info.plist。然后选择Open As > Source Code。最后,拷贝下面的XML代码然后在
标记前插入这段代码。
现在你已经在info.plist文件里添加了两个键值:
NSMicrophoneUsageDescription -为获取麦克风语音输入授权的自定义消息。注意这个语音输入授权仅仅只会在用户点击microphone按钮时发生。
NSSpeechRecognitionUsageDescription – 语音识别授权的自定义信息
可以自行更改这些消息的内容。现在点击Run按钮,你应该可以编译和成功运行app了,不会报任何错误。
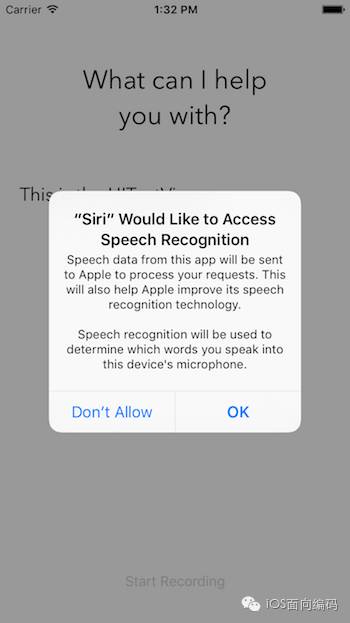
注意:如果稍后在工程运行完成时还没有看到语音输入授权框,那是因为你是在模拟器上运行的程序。iOS模拟器没有权限进入你Mac电脑的麦克风。
处理语音识别
现在我们已经实现了用户授权,我们现在去实现语音识别功能。先从在 ViewController里定义下面的对象开始:
private var recognitionRequest: SFSpeechAudioBufferRecognitionRequest?
private var recognitionTask: SFSpeechRecognitionTask?
private let audioEngine = AVAudioEngine()
recognitionRequest对象处理了语音识别请求。它给语音识别提供了语音输入。
reconition task对象告诉你语音识别对象的结果。拥有这个对象很方便因为你可以用它删除或者中断任务。
audioEngine是你的语音引擎。它负责提供你的语音输入。
接下来,创建一个新的方法名叫 startRecording()。
func startRecording() {
if recognitionTask != nil {
recognitionTask?.cancel()
recognitionTask = nil
}
let audioSession = AVAudioSession.sharedInstance()
do {
try audioSession.setCategory(AVAudioSessionCategoryRecord)
try audioSession.setMode(AVAudioSessionModeMeasurement)
try audioSession.setActive(true, with: .notifyOthersOnDeactivation)
} catch {
print("audioSession properties weren't set because of an error.")
}
recognitionRequest = SFSpeechAudioBufferRecognitionRequest()
guard let inputNode = audioEngine.inputNode else {
fatalError("Audio engine has no input node")
}
guard let recognitionRequest = recognitionRequest else {
fatalError("Unable to create an SFSpeechAudioBufferRecognitionRequest object")
}
recognitionRequest.shouldReportPartialResults = true
recognitionTask = speechRecognizer.recognitionTask(with: recognitionRequest, resultHandler: { (result, error) in
var isFinal = false
if result != nil {
self.textView.text = result?.bestTranscription.formattedString
isFinal = (result?.isFinal)!
}
if error != nil || isFinal {
self.audioEngine.stop()
inputNode.removeTap(onBus: 0)
self.recognitionRequest = nil
self.recognitionTask = nil
self.microphoneButton.isEnabled = true
}
})
let recordingFormat = inputNode.outputFormat(forBus: 0)
inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) { (buffer, when) in
self.recognitionRequest?.append(buffer)
}
audioEngine.prepare()
do {
try audioEngine.start()
} catch {
print("audioEngine couldn't start because of an error.")
}
textView.text = "Say something, I'm listening!"
}
这个方法会在Start Recording按钮被点击时调用。它主要功能是开启语音识别然后聆听你的麦克风。我们一行行分析上面的代码:
3-6行 – 检查 recognitionTask 是否在运行。如果在就取消任务和识别。
8-15行 – 创建一个 AVAudioSession来为记录语音做准备。在这里我们设置session的类别为recording,模式为measurement,然后激活它。注意设置这些属性有可能会抛出异常,因此你必须把他们放入try catch语句里面。
17行 – 实例化recognitionRequest。在这里我们创建了SFSpeechAudioBufferRecognitionRequest对象。稍后我们利用它把语音数据传到苹果后台。
19-21行 – 检查 audioEngine(你的设备)是否有做录音功能作为语音输入。如果没有,我们就报告一个错误。
23-25行 – 检查recognitionRequest对象是否被实例化和不是nil。
27行– 当用户说话的时候让recognitionRequest报告语音识别的部分结果 。
29行
– 调用 speechRecognizer的recognitionTask 方法来开启语音识别。这个方法有一个completion
handler回调。这个回调每次都会在识别引擎收到输入的时候,完善了当前识别的信息时候,或者被删除或者停止的时候被调用,最后会返回一个最终的文本。
31行 – 定义一个布尔值决定识别是否已经结束。
35行 – 如果结果 result 不是nil, 把 textView.text 的值设置为我们的最优文本。如果结果是最终结果,设置 isFinal为true。
39-47行 – 如果没有错误或者结果是最终结果,停止 audioEngine(语音输入)并且停止 recognitionRequest 和 recognitionTask.同时,使Start Recording按钮有效。
50-53行 – 向 recognitionRequest增加一个语音输入。注意在开始了recognitionTask之后增加语音输入是OK的。Speech Framework 会在语音输入被加入的同时就开始进行解析识别。
55行 – 准备并且开始audioEngine。
触发语音识别
我们需要保证当创建一个语音识别任务的时候语音识别功能是可用的,因此我们必须给ViewController添加一个代理方法。如果语音输入不可用或者改变了它的状态,那么
microphoneButton.enable属性就要被设置。针对这种情况,我们实现了SFSpeechRecognizerDelegate
协议的 availabilityDidChange 方法。实现内容看下面:
func speechRecognizer(_ speechRecognizer: SFSpeechRecognizer, availabilityDidChange available: Bool) {
if available {
microphoneButton.isEnabled = true
} else {
microphoneButton.isEnabled = false
}
}
这个方法会在可用性状态改变时被调用。如果语音识别可用,那么记录按钮record会被设为可用状态。
最后一件事就是我们必须更新响应方法microphoneTapped(sender:):
@IBAction func microphoneTapped(_ sender: AnyObject) {
if audioEngine.isRunning {
audioEngine.stop()
recognitionRequest?.endAudio()
microphoneButton.isEnabled = false
microphoneButton.setTitle("Start Recording", for: .normal)
} else {
startRecording()
microphoneButton.setTitle("Stop Recording", for: .normal)
}
}
在这个方法中,我们必须检查
audioEngine是否正在工作。如果是,app应该停止 audioEngine,
中止向recognitionRequest输入音频,让microphoneButton按钮不可用,并且设置按钮的标题为 “Start
Recording”
如果 audioEngine 正在工作,app应该调用 startRecording() 并且设置按钮的标题为 “Stop Recording”。
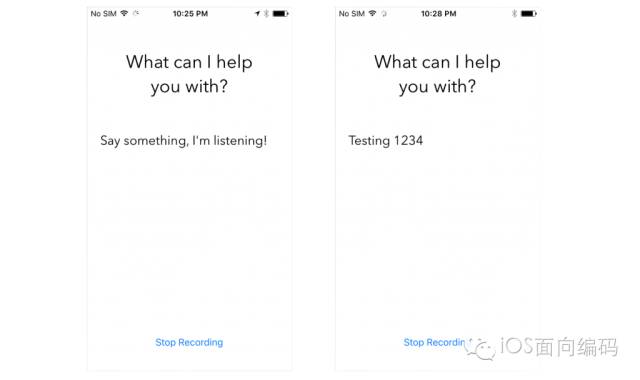
非常好!现在可以准备测试app了。把app部署到一个iOS10的设备,然后点击“Start Recording”按钮。去说些什么吧!
注意:
苹果公司对每个设备的识别功能都有限制。具体的限制并不知道,但是你可以联系苹果公司了解更多信息。
苹果公司对每个app也有识别功能限制。
如果你经常遇到限制,请一定联系苹果公司,他们应该可以解决问题。
语音识别会很耗电以及会使用很多数据。
语音识别一次只持续大概一分钟时间。
总结
在这个教程中,你学习到了怎样好好的利用苹果公司开放给开发者的惊人的新语言API,用于语音识别并且转换到文本。Speech
framework
使用了跟Siri相同的语音识别框架。这是一个相对小的API。但是,它非常强大可以让开发者们开发非凡的应用比如转换一个语音文件到文本文字。
我推荐你看WWDC 2016 session 509 去获取更多有用信息。希望你喜欢这篇文章并且在探索这个全新API中获得乐趣。
作为参考,你可以在这里查看Github完整工程
长按关注:

QQ群:427763454
欢迎你的投稿,展示的你的技术文章:[email protected]